
AI视频共12篇
排序

世界顶尖多模态大模型开源!又是零一万物,又是李开复
允中 发自 凹非寺 量子位 | 公众号 QbitAI 领跑中英文两大权威榜单,李开复零一万物交出多模态大模型答卷! 距离其首款开源大模型Yi-34B和Yi-6B的发布,仅间隔不到三个月的时间。 模型名为Yi Vi...

超过ConvNeXt等!上海交大提出Transformer架构新SOTA:SeTformer
作者丨小源 来源丨数源AI 编辑丨极市平台 论文链接:https://arxiv.org/pdf/2401.03540.pdf 引言 Transformer最初是用于自然语言处理(NLP)的技术,在视觉领域得到了显著的流行,这要归功于Vis...

视觉AI实战派?场景科技化推进商汤\旷视\微美全息算法升级
随着经济生活水平的提升和人工智能等新兴技术的发展,各行业场景对服务提质增效提出了新的需求。视觉AI作随着经济生活水平的提升和人工智能等新兴技术的发展,各行业场景对服务提质增效提出了新...
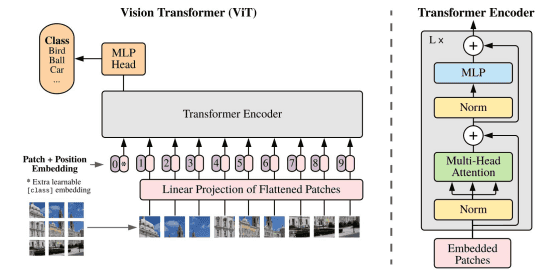
六、Vision Transformer(ViT)
辰流看完Transformer之后,梦里都是Attention。 谢谢你,nlp。 谢谢你,attention。 谢谢你,transformer。 感谢多了,或许就要流泪了。 俗话说趁热打铁。第五章中的Transformer虽用于nlp领域,...
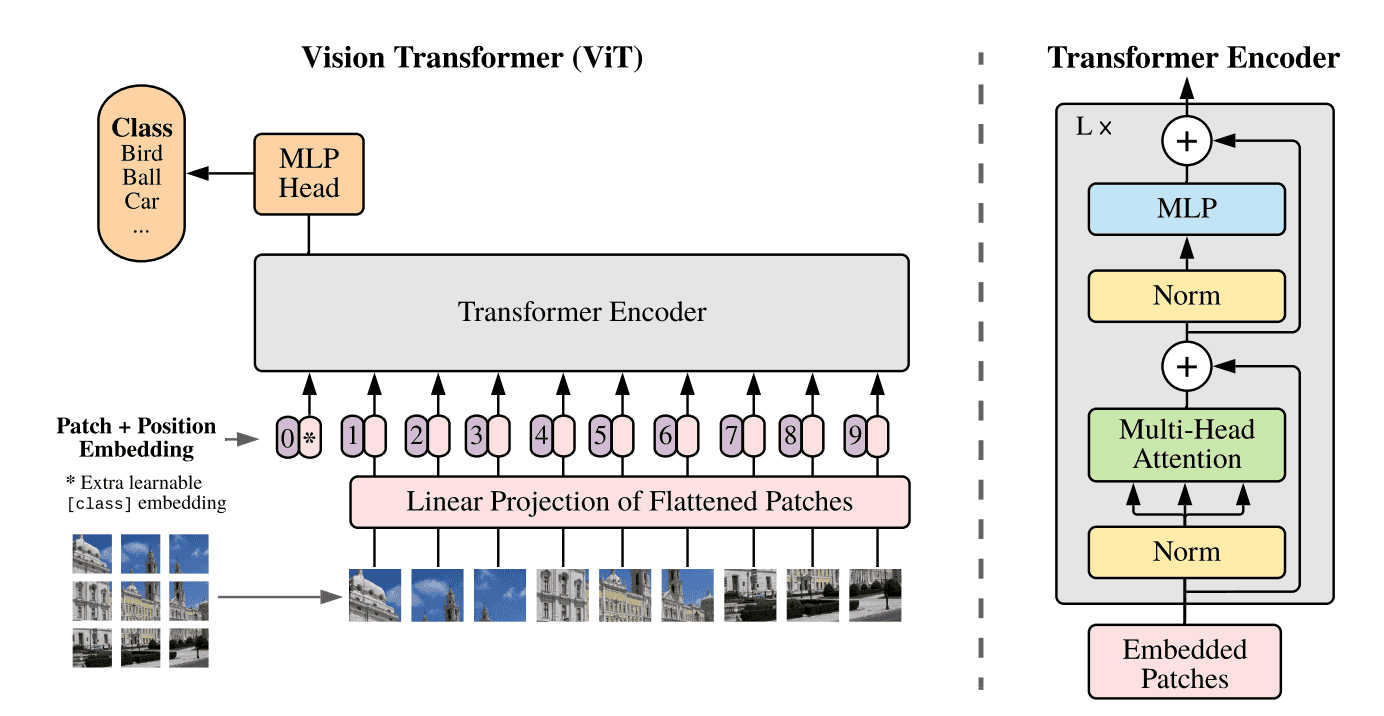
深度学习:读论文《Vision Transformer (ViT)》-2021年
hello,大家好,我是小孟,欢迎来到我的频道,如果喜欢,请三连:关注、点赞、转发。您的支持是我创作的动力源泉。今天我们来读一篇论文,这篇论文的标题是《An Image Is Worth 16x16 Words: Tr...
ViT-Vision Transformer 详解
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打...
我的面板

看一看

unityvr开发教程(unity ar ui)精通篇-Unity AR和VR开发
Unity是一个支持AR(增强现实)和VR(虚拟现实)开发的平台,可以创建交互式的增强现实和虚拟现实应用程序。在Unity中,AR和VR的开发都涉及到三个核心方面:视觉呈现、用户输入和场景管理。1.视...
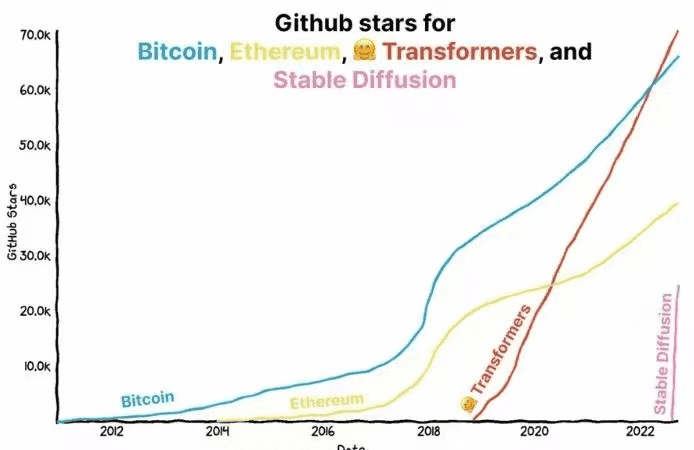
1.01亿美元融资,为Stable Diffusion捐赠算力的公司两年成为独角兽
编辑:shanshan、张倩 这家公司声称要让 10 亿人用上开源大模型。 根据文本生成图像是今年大火的一个研究方向,与之相关的 Stable Diffusion 模型已经在 GitHub 上收获了 3 万多颗星,其热度增...

UNRAID DOCKER 篇二:UNRAID下AI绘图stable-diffusion新版的安装,开启你的AI创作之旅,有LORA哦李玉刚“投河自尽”事件始末
作者:Tommyvinny 购买理由 距离上次AI绘图stable-diffusion的Docker已经都过去了近一年,SD已经进化出了太多的功能,原来的stable-diffusion-guitard这个DOCKER作者更新太慢,而且后来的LORA功...

Deepfake平民化,十美元加一台笔记本,人人都能变阿汤哥
如果说最近哪项技术在近段时间引发了美国全社会的反感,那毫无疑问是人脸识别技术。 从去年开始,美国就已经开始有禁止人脸识别的动作了。去年5月,旧金山成为第一个禁止政府购买和使用人脸识别...

Lidar Studio点云处理与分析软件
Lidar Studio V1.3正式发布 新增功能航带平差模块:自动进行航带平差、计算安置误差,支持SBET格式的航迹文件视图模块:每个点云单独进行渲染设置(按高程渲染等)Lidar Studio V1.2正式发布 新...

PaddleSeg全新版本等你来体验!
图像分割是计算机视觉的一项基础技术,其目标是将图像中的像素按内容分成不同的类别。它在许多领域有重要应用,比如自动驾驶、工业质检、医疗图像分析、遥感图像解译等。 01 导读 PaddleSeg 是...

