
AI视频共12篇
排序

超过ConvNeXt等!上海交大提出Transformer架构新SOTA:SeTformer
作者丨小源 来源丨数源AI 编辑丨极市平台 论文链接:https://arxiv.org/pdf/2401.03540.pdf 引言 Transformer最初是用于自然语言处理(NLP)的技术,在视觉领域得到了显著的流行,这要归功于Vis...
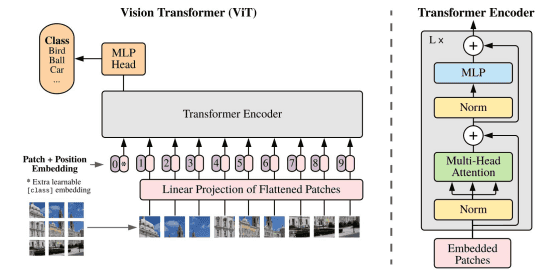
深度学习:读论文《Vision Transformer (ViT)》-2021年
hello,大家好,我是小孟,欢迎来到我的频道,如果喜欢,请三连:关注、点赞、转发。您的支持是我创作的动力源泉。今天我们来读一篇论文,这篇论文的标题是《An Image Is Worth 16x16 Words: Tr...

当Swin Transformer遇上DCN,清华可变形注意力模型优于多数ViT
机器之心报道 编辑:小舟 本文中,来自清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置,使得自注意力...

用 Vision Transformer 进行图像分类
Transformer 问世后被广泛地用在 NLP 的各种任务中,但是却很少出现在计算机视觉领域中。目前计算机视觉主流的模型依然是 CNN,各种 attention 操作也是在 CNN 结构上进行。本文介绍 Vision Tra...
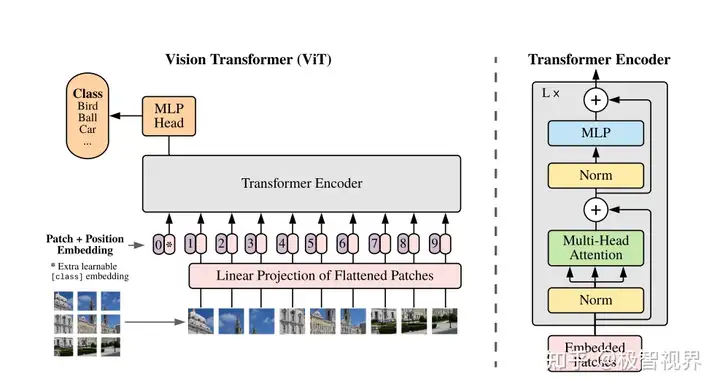
极智AI | 详解 ViT 算法实现
欢迎关注我,获取我的更多笔记分享 大家好,我是极智视界,本文详细介绍一下 ViT 算法的设计与实现,包括代码。 ViT 全称 Vision Transformer,是 transformer 在 CV 领域应用表现好的开始,而...
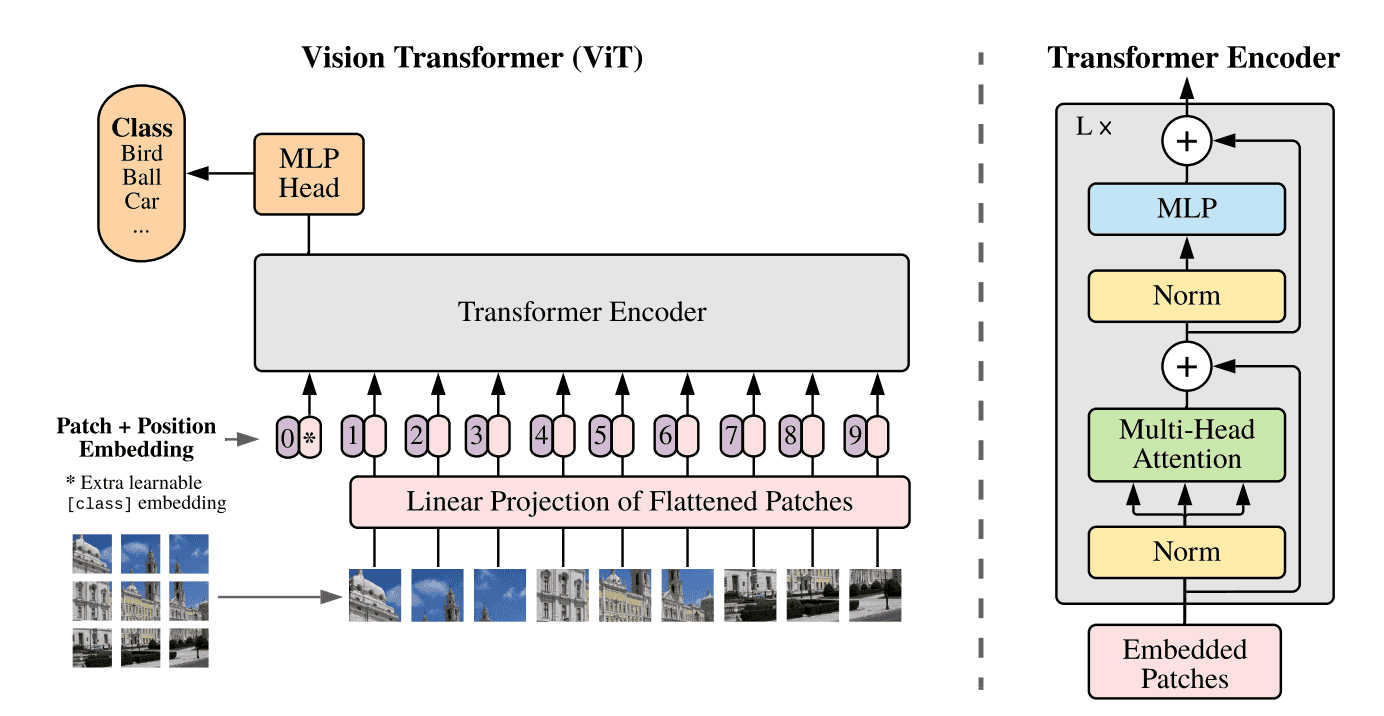
ViT-Vision Transformer 详解
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打...
我的面板

看一看

NLP这12个数据集,赶紧收藏备用!
平台的数据集版块,共有200个不同类别,不同应用的数据集。 本周在此基础上,又上新12种人体姿态识别相关的数据集,目前总共有212种数据集。 ① 文本摘要 数据集名称:CurationCorpus数据集 数...

spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...
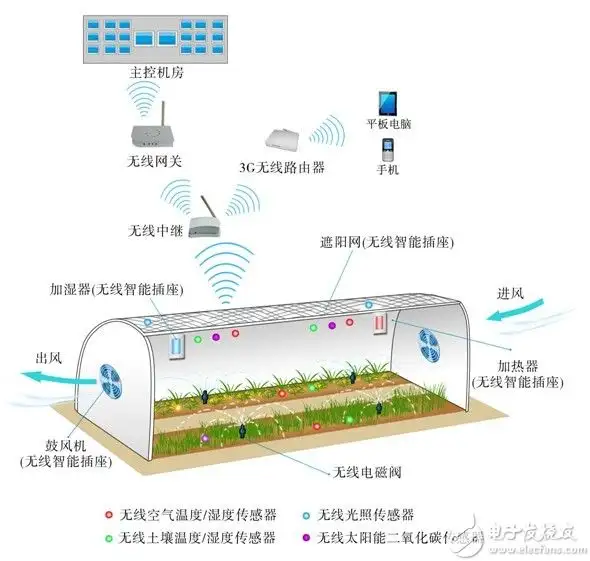
以温室大棚种植技术为例,看看智慧农业方案需要用到哪些技术?
在物联网技术的引领下,现代化的精准农业采用了先进的温室大棚种植技术。可以在阳光不足的时候,通过物联产品自动补充人造光线,促进光合作用;可以在湿度不够的时候,通过物联产品自动为农作物...
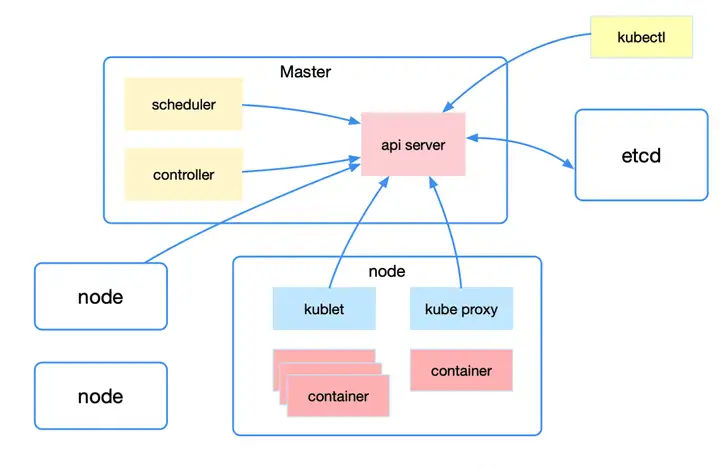
有了这篇 Kubernetes 的介绍,它的原理秒懂!
kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。本文将带着大家快速了解 kubernetes ,了解...

40项增强功能更新,2个功能被弃用,Kubernetes 1.25发布!贾玲“整容式”近照曝光:暴瘦40斤,颜值逆天,我却笑不出来
【CSDN 编者按】自 2014 年 Kubernetes 首次面世以来,这套基于开源且能在集群服务器上部署应用和容器的系统就备受业界喜爱。目前 Kubernetes 发布了 1.25 版本,该版本共包含 40 项增强功能。...
Flink学习笔记一:安装部署与快速入门
1、概述 1.1、基础介绍 Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. 1.2、数据处理结构演变 1)传统...

