
AI视频共12篇
排序
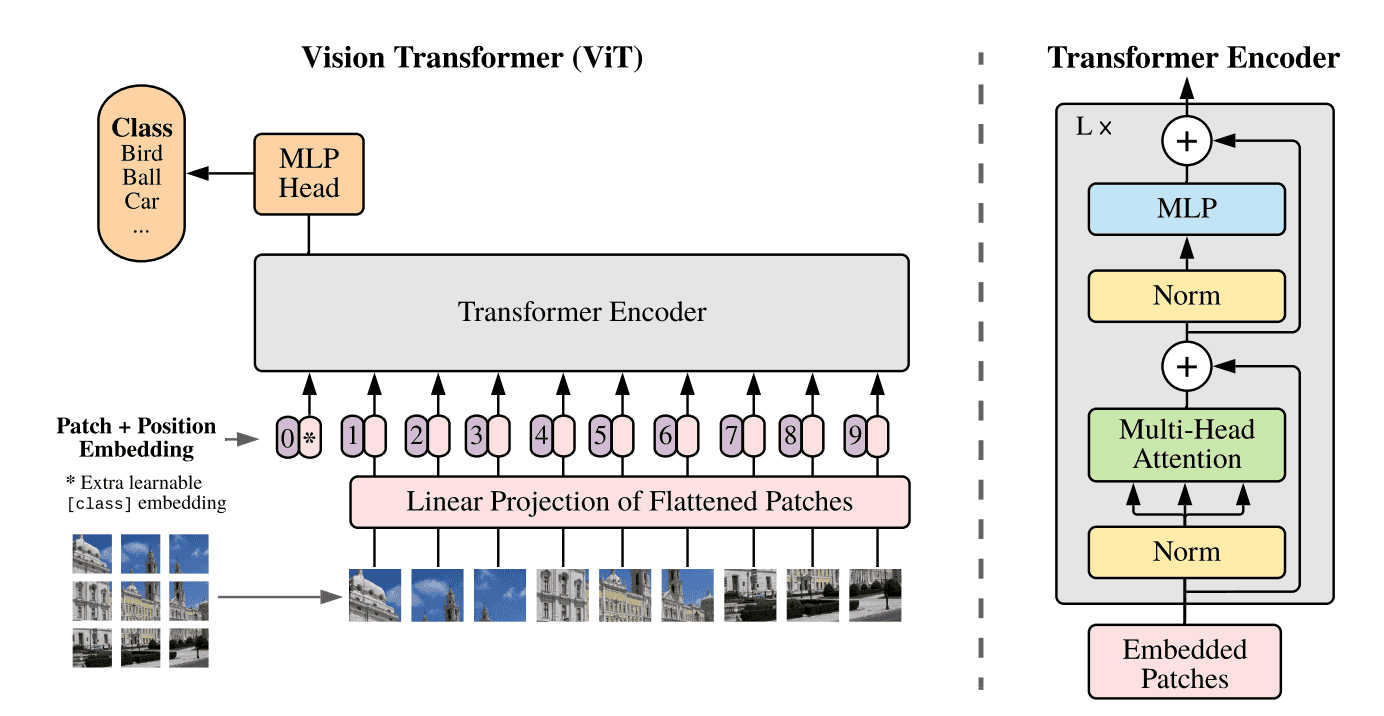
ViT-Vision Transformer 详解
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打...

世界顶尖多模态大模型开源!又是零一万物,又是李开复
允中 发自 凹非寺 量子位 | 公众号 QbitAI 领跑中英文两大权威榜单,李开复零一万物交出多模态大模型答卷! 距离其首款开源大模型Yi-34B和Yi-6B的发布,仅间隔不到三个月的时间。 模型名为Yi Vi...
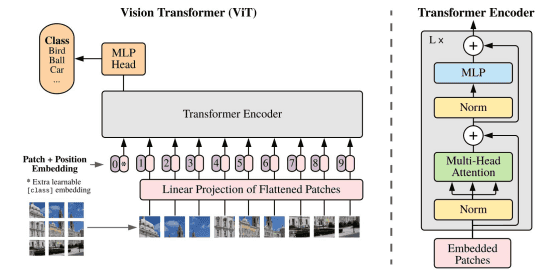
深度学习:读论文《Vision Transformer (ViT)》-2021年
hello,大家好,我是小孟,欢迎来到我的频道,如果喜欢,请三连:关注、点赞、转发。您的支持是我创作的动力源泉。今天我们来读一篇论文,这篇论文的标题是《An Image Is Worth 16x16 Words: Tr...
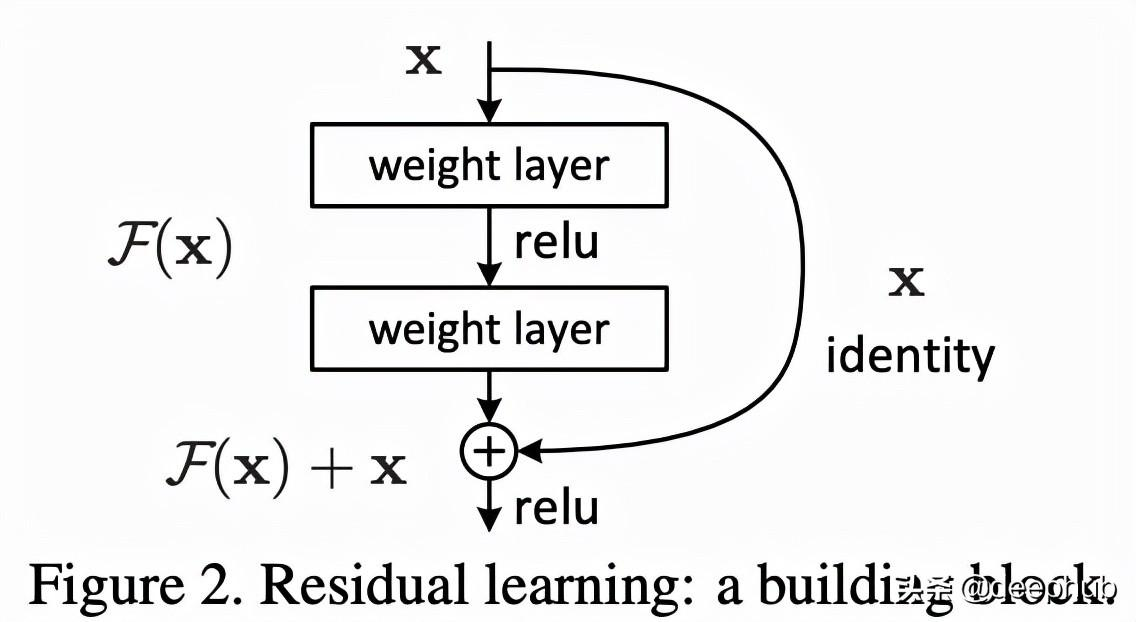
论文解释:Vision Transformers和CNN看到的特征是相同的吗?
近年来,Vision Transformer (ViT) 势头强劲。 本文将解释论文《Do Vision Transformers See Like Convolutional Neural Networks?》 (Raghu et al., 2021) 由 Google Research 和 Google Brain...
脑科学能用Transformer做什么?
图片来源@视觉中国 文 | 追问nextquestion 自ChatGPT问世以来,“Transformer模型”始终以超高频率出现在各个AI新产品模块当中。比如,大家所熟知的GPT-4、Midjourney、GitHub Copilot等,它们...

超过ConvNeXt等!上海交大提出Transformer架构新SOTA:SeTformer
作者丨小源 来源丨数源AI 编辑丨极市平台 论文链接:https://arxiv.org/pdf/2401.03540.pdf 引言 Transformer最初是用于自然语言处理(NLP)的技术,在视觉领域得到了显著的流行,这要归功于Vis...
我的面板

看一看

第三课threejs全景预览房间案例
> 背景: 如何在网页中预览房间每个角度? 如全景看房 ## 功能实现思路 1. 创建threejs场景 2. 创建球体 3. 创建鱼眼全景图片 4. 翻转球体将鱼眼图贴在球体内部 5. 相机设置在球体中心,循环...

推荐3D点云标注工具?
可以看看我们总结的标定工具大全,3D点云标注工具也有作者:汽车人 | 原文出处:公众号【自动驾驶之心】加入我们:技术交流群 标注工具是处理原始数据的第一关,无论是检测任务、分割任务还是3D...

在Unity上开发VR
VR原理 VR(Virtual Reality,虚拟显示,简称VR),VR技术利用计算机创造一个虚拟空间,利用虚拟现实眼镜能够使用户完全沉浸在一个虚拟的合成环境中,无法看到真实环境;利用双目视觉原理,虚拟...

全新大模型参数高效微调方法SSF:仅需训练0.3M的参数,效果卓越(NeurlPS 22 )
点击下方卡片,关注“FightingCV”公众号 回复“AI”即可获得超100G人工智能的教程 点击进入→FightingCV交流群 作者丨字节跳动智能创作团队 来源丨机器之心 转载丨极市平台 论文地址:https://...
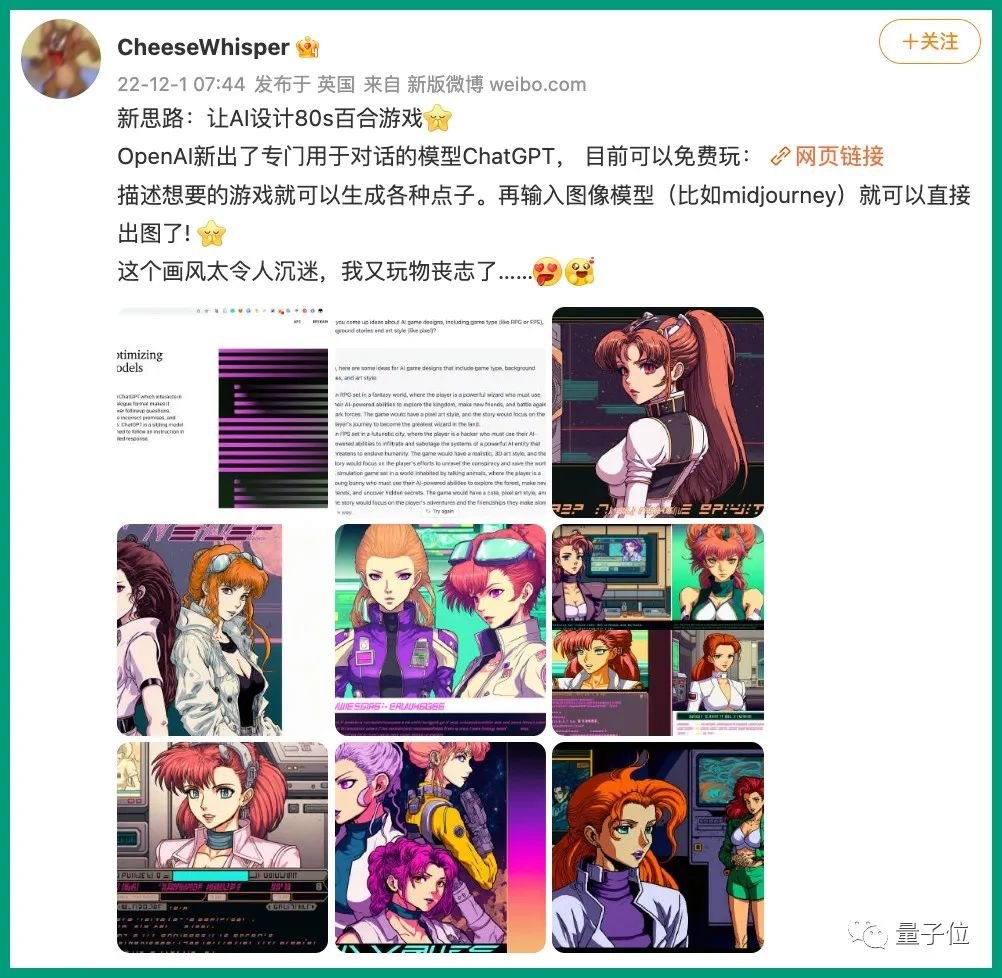
让AI生成AI绘画提示词,OpenAI最新成果ChatGPT被网友玩坏了!还会写代码修bug作诗
一款新的聊天AI被网友们玩疯了。 能直接生成代码、会自动修复bug、在线问诊、模仿莎士比亚风格写作……各种话题都能hold住,它就是OpenAI刚刚推出的——ChatGPT。 有脑洞大开的网友甚至用它来设...

看腾讯如何提升 Kubernetes 集群利用率?
嘉宾 | 宋翔出品 | CSDN云原生 提到近两年的技术热词,“云原生”觉得是位居前列。从云计算大数据再到如今的云原生时代,一大批新技术涌现,例如当下最火热的系统部署和容器服务平台Kubernetes...

