
AI视频共12篇 第2页
排序
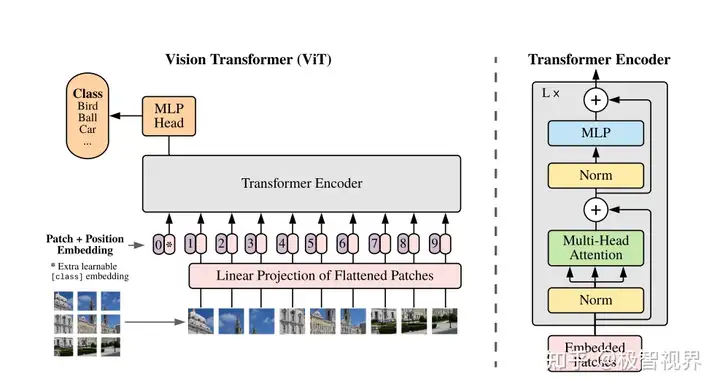
极智AI | 详解 ViT 算法实现
欢迎关注我,获取我的更多笔记分享 大家好,我是极智视界,本文详细介绍一下 ViT 算法的设计与实现,包括代码。 ViT 全称 Vision Transformer,是 transformer 在 CV 领域应用表现好的开始,而...
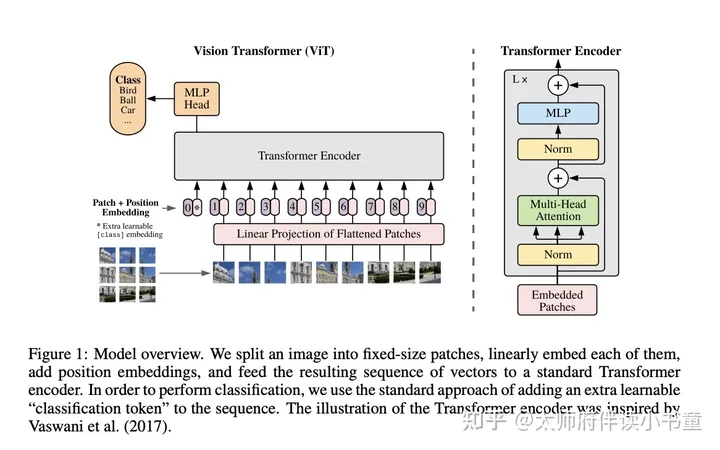
Vision Transformer(ViT):打通CV与NLP领域的经典之作
打通的壁垒 回顾一下,在Transformer中,计算自注意力权重的时候,需要序列中的元素两两计算相似度(或者叫相容性函数),其计算复杂度是 O(n2)O( n^{2} )。所以,如果序列长度太长的话,计算复...
六、Vision Transformer(ViT)
辰流看完Transformer之后,梦里都是Attention。 谢谢你,nlp。 谢谢你,attention。 谢谢你,transformer。 感谢多了,或许就要流泪了。 俗话说趁热打铁。第五章中的Transformer虽用于nlp领域,...

用 Vision Transformer 进行图像分类
Transformer 问世后被广泛地用在 NLP 的各种任务中,但是却很少出现在计算机视觉领域中。目前计算机视觉主流的模型依然是 CNN,各种 attention 操作也是在 CNN 结构上进行。本文介绍 Vision Tra...
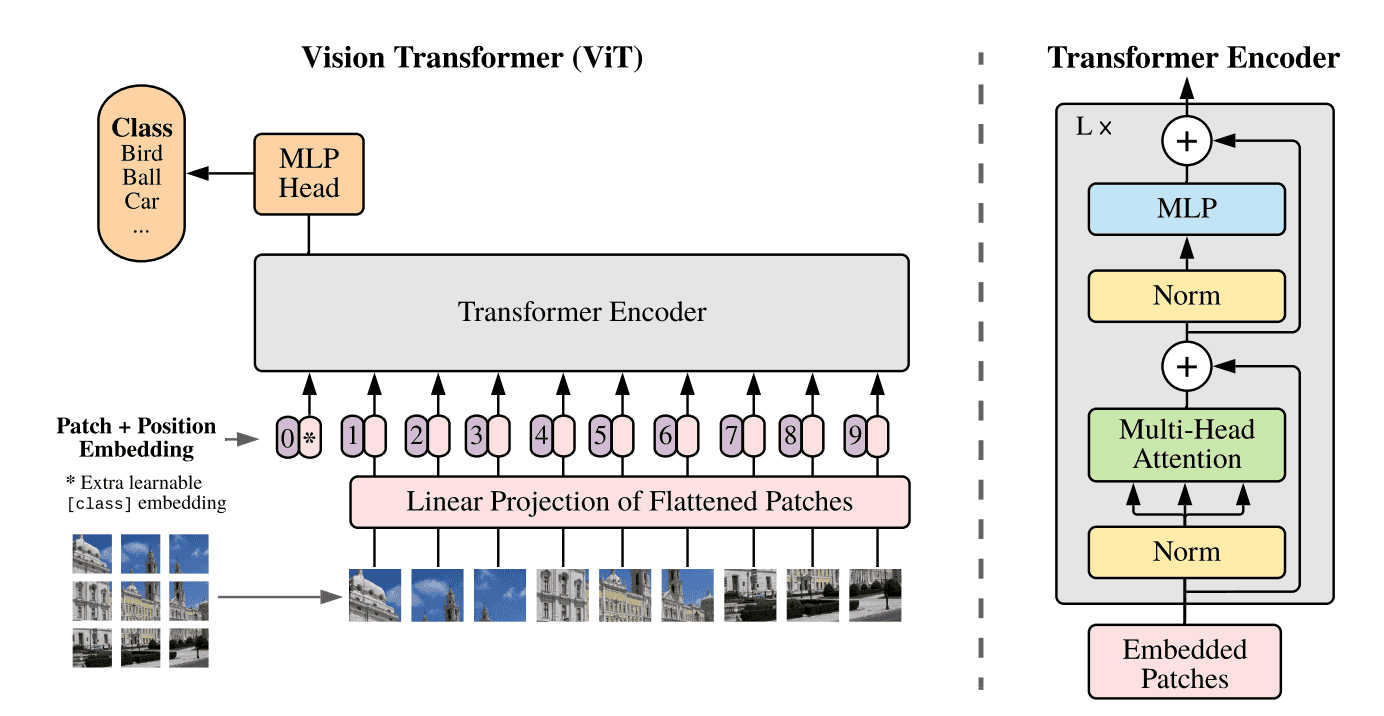
ViT-Vision Transformer 详解
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打...

世界顶尖多模态大模型开源!又是零一万物,又是李开复
允中 发自 凹非寺 量子位 | 公众号 QbitAI 领跑中英文两大权威榜单,李开复零一万物交出多模态大模型答卷! 距离其首款开源大模型Yi-34B和Yi-6B的发布,仅间隔不到三个月的时间。 模型名为Yi Vi...
我的面板

看一看

互联网2023年热门领域有哪些?
2023年互联网行业的热门领域包括: 元宇宙:元宇宙是一个虚拟的世界,它是基于现实世界的数字化版本,可以提供虚拟的空间、社交、游戏、商业等多种应用场景。目前,元宇宙已经成为互联网行业的...

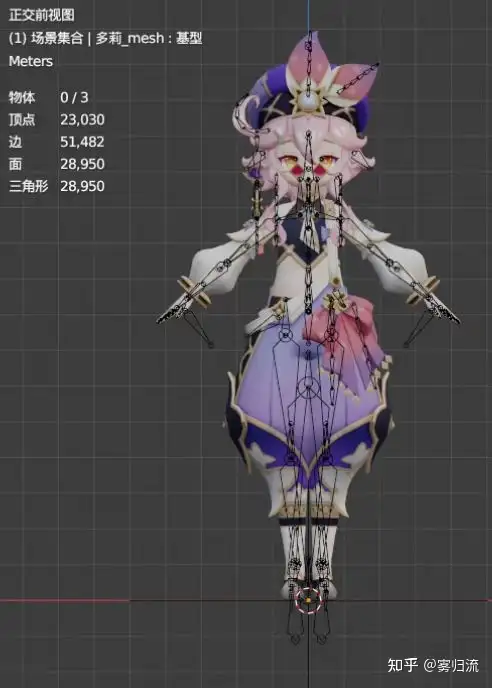
AI技术让手办“整活”:3D建模居然可以这样简单
原创 Synced 机器之心 机器之心报道 机器之心编辑部 拍短视频、发朋友圈,整活必备? 科技领域,既有用元宇宙开发布会的公司,也有 All in 元宇宙的公司,很多虚拟世界已经建立起来,人们面临的...

Kubernetes 真的很难吗?明星在资本面前有多卑微?杨颖被摸胸抱起,林更新被怒骂不敢回嘴
【CSDN 编者按】Kubernetes 提供了许多开箱即用的好东西,可以推进业务的发展。但这是否意味着,所有服务都要放到 Kubernetes 上运行?当然不是。 原文链接:https://rcwz.pl/2023-03-26-kubern...

对话彭博:开源LLM「RWKV」打造AI领域的Linux和Android
作者|沈筱编辑|王与桐“我们没有护城河,OpenAI也是。”近期,谷歌内部人士在Discord社区匿名共享了一份内部文件,点破了谷歌和OpenAI正面临的来自开源社区的挑战。尽管经外媒SemiAnalysis求...

Apple官方优化Stable Diffusion绘画教程
Apple官方优化Stable Diffusion绘画教程 苹果为M1芯片优化Stable Diffusion模型,其中Mac Studio (M1 Ultra, 64-core GPU)生成512*512的图像时间为9秒。想要1秒出图,可以在线体验3090显卡AI绘...

碧桂园北大荒打造全球首个超万亩无人化农场 抢占智慧农业技术制高点
图集 借助卫星导航定位,收割机匀速直线推进,遇到尽头的田埂自主转向掉头,不一会儿机身仓贮就显示已经装满。此时后方无人驾驶的接粮机“闻讯”赶来,两车默契协同作业,收割机准确地将稻谷转...

