
AI视频共12篇 第2页
排序
论文解释:Vision Transformers和CNN看到的特征是相同的吗?
近年来,Vision Transformer (ViT) 势头强劲。 本文将解释论文《Do Vision Transformers See Like Convolutional Neural Networks?》 (Raghu et al., 2021) 由 Google Research 和 Google Brain...
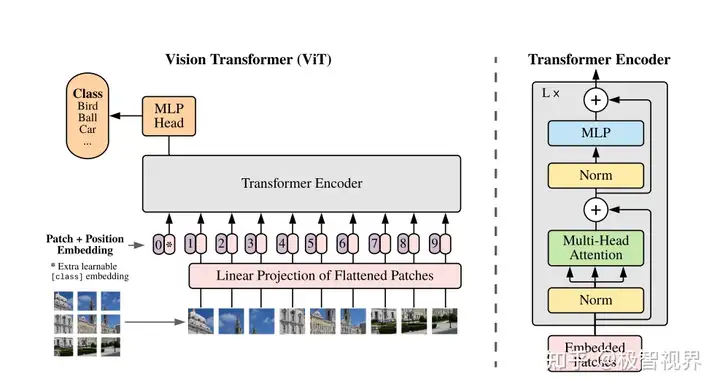
极智AI | 详解 ViT 算法实现
欢迎关注我,获取我的更多笔记分享 大家好,我是极智视界,本文详细介绍一下 ViT 算法的设计与实现,包括代码。 ViT 全称 Vision Transformer,是 transformer 在 CV 领域应用表现好的开始,而...
脑科学能用Transformer做什么?
图片来源@视觉中国 文 | 追问nextquestion 自ChatGPT问世以来,“Transformer模型”始终以超高频率出现在各个AI新产品模块当中。比如,大家所熟知的GPT-4、Midjourney、GitHub Copilot等,它们...

当Swin Transformer遇上DCN,清华可变形注意力模型优于多数ViT
机器之心报道 编辑:小舟 本文中,来自清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置,使得自注意力...

用 Vision Transformer 进行图像分类
Transformer 问世后被广泛地用在 NLP 的各种任务中,但是却很少出现在计算机视觉领域中。目前计算机视觉主流的模型依然是 CNN,各种 attention 操作也是在 CNN 结构上进行。本文介绍 Vision Tra...
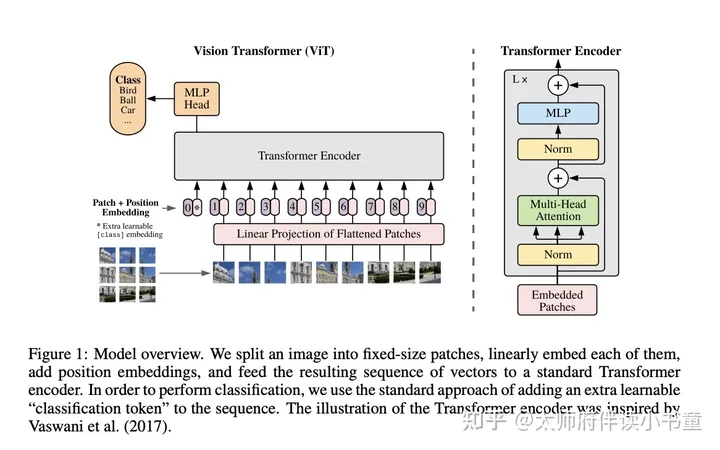
Vision Transformer(ViT):打通CV与NLP领域的经典之作
打通的壁垒 回顾一下,在Transformer中,计算自注意力权重的时候,需要序列中的元素两两计算相似度(或者叫相容性函数),其计算复杂度是 O(n2)O( n^{2} )。所以,如果序列长度太长的话,计算复...
我的面板

看一看

百度推出的免费AI绘画应用,无需付费,无需排队!!
百度发力AI已经有五年时间了,不过主要还是在自动驾驶,智慧城市,工业AI这些方向,我们平时生活中并没有什么感知。 但在刚刚结束的2022百度世界大会上,展示了这样一个场景:随着画卷的缓缓展...

对话360集团CEO创始人周鸿祎:做大语言模型比做光刻机简单多了“肯德基吸管”事件遭群嘲,把当代社会的又一病态现象暴露无遗
本文是5月31日品玩举办的“模型思辨——国内大模型生态研讨会”上,品玩创始人、CEO骆轶航与360集团创始人、CEO周鸿祎的对话实录,经整理编辑发布。访谈人:骆轶航受访人:周鸿祎 大模型确实要...
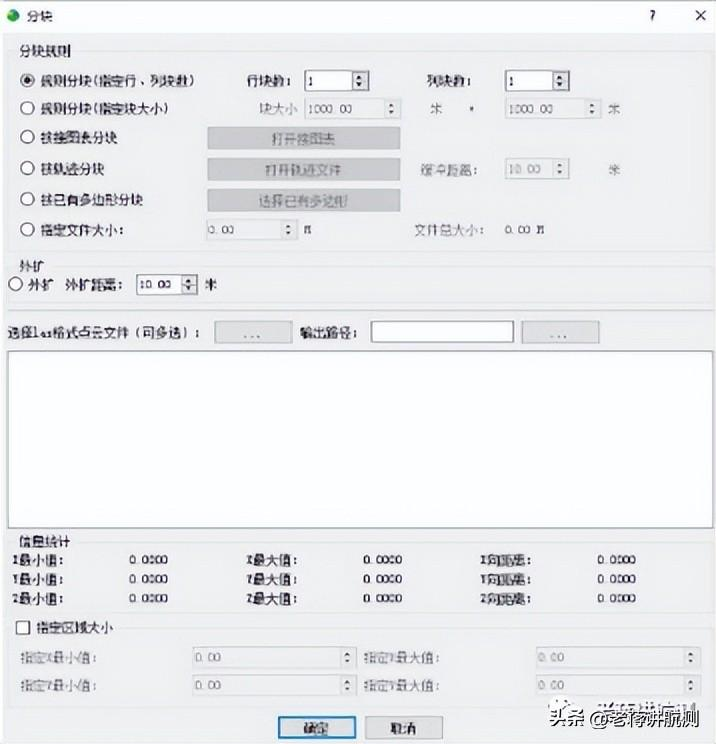
「大疆智图」点云测绘应用——点云智绘
大疆智图激光雷达点云数据处理只是做了预处理,把L1原始激光雷达文件转换成标准las格式三维点云,还需要借助以下点云分析软件才能实现地形提取、DEM生成、植被信息提取等行业应用。 点云智绘 点...
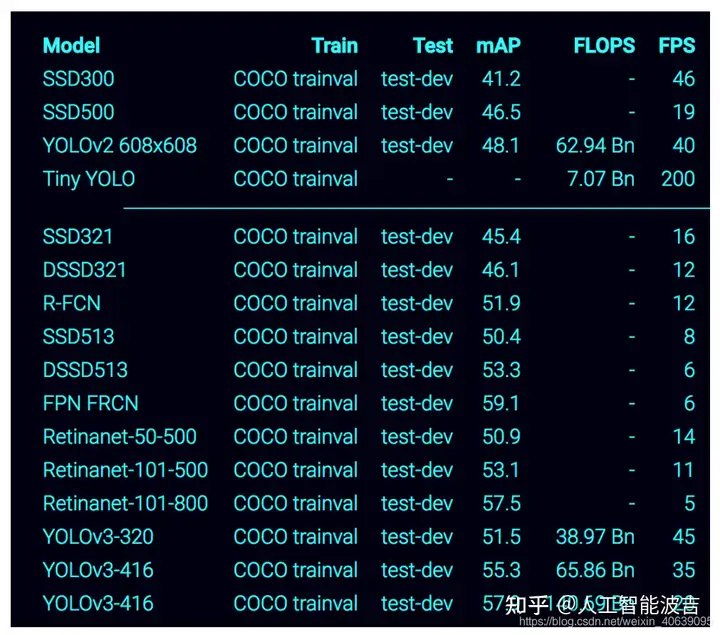
yolov5算法原理(yolov4算法原理)深度学习计算机视觉之YOLO,YOLOv2和YOLOv3算法(超详细解析),
您只看一次(YOLO)是针对实时处理的对象检测系统。我们将在本文中介绍YOLO,YOLOv2和YOLOv3。这是YOLO官网提供各种模型的准确性和速度比较。 转载自深度学习计算机视觉之YOLO,YOLOv2和YOLOv3...

无人机“飞播” ,看智慧农业助力春耕的这些神操作
新快报讯 记者李红云 通讯员江轩报道 一个人在手机上轻点几下,远处无人机智能地将种子播撒到田间,只需要 4 分钟就可以完成一亩的播种工作。 这样的场景真实发生在广东江门台山市都斛镇。近日...
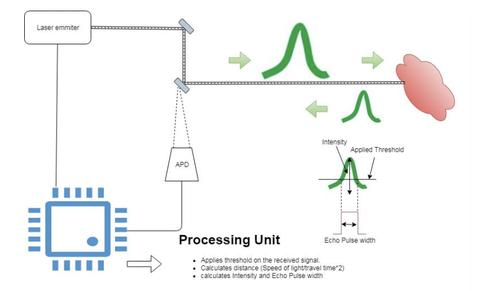
端到端传感器建模生成激光雷达点云
发表在SIGAI的翻译文章: SIGAI:端到端传感器建模生成激光雷达点云14 赞同 · 0 评论文章 注:这是一篇2019年7月发表在arXiv的论文【1】,如题目所言是对激光雷达传感器的仿真建模,以生成3D点...

