
spark共74篇 第4页
排序

PySpark 处理数据和数据建模
安装相关包 from pyspark.sql import SparkSession from pyspark.sql.functions import udf, when, count, countDistinct from pyspark.sql.types import IntegerType,StringType from pyspark....
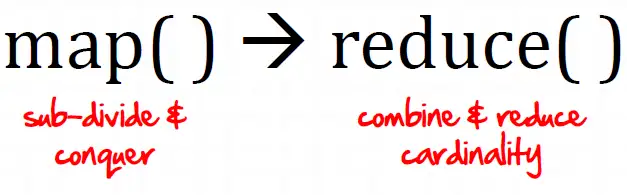
与 Hadoop 对比,如何看待 Spark 技术?
Hadoop 首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。HDFS,在由普通PC组成的集群上提供...
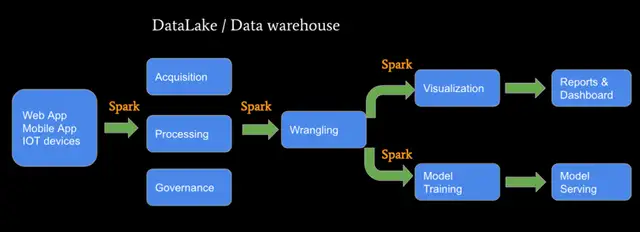
spark大数据分析源码解析Spark 大数据处理最佳实践
内容框架:大数据概览如何摆脱技术小白Spark SQL 学习框架EMR Studio 上的大数据最佳实践一、大数据概览大数据处理 ETL (Data → Data)大数据分析 BI (Data → Dashboard)机器学习 AI (Data → ...

spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...

spark处理大数据有什么优势(大数据 spark架构)大数据入门:Spark Streaming实际应用
作为Spark负责流计算的核心组件,Spark Streaming是整个Spark学习流程当中非常重要的一块。对于Spark Streaming,作为Spark流计算的实际承载组件,我们也需要更全面的掌握。今天的大数据入门分...
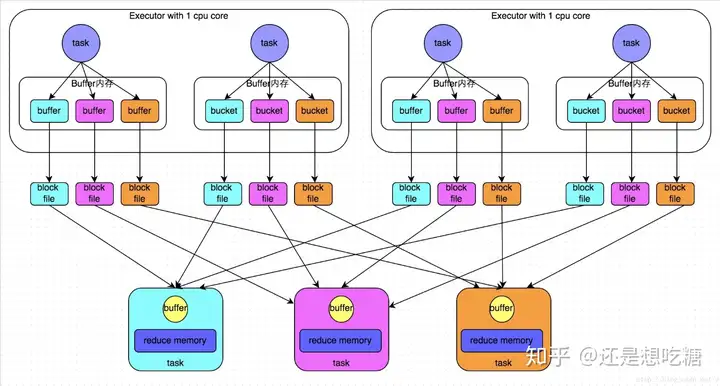
spark性能调优
Spark是大数据分析的利器,在工作中用到spark的地方也比较多,这篇总结是希望能将自己使用spark的一些调优经验分享出来。 一、常用参数说明 --driver-memory 4g : driver内存大小,一般没有广播...
我的面板

看一看
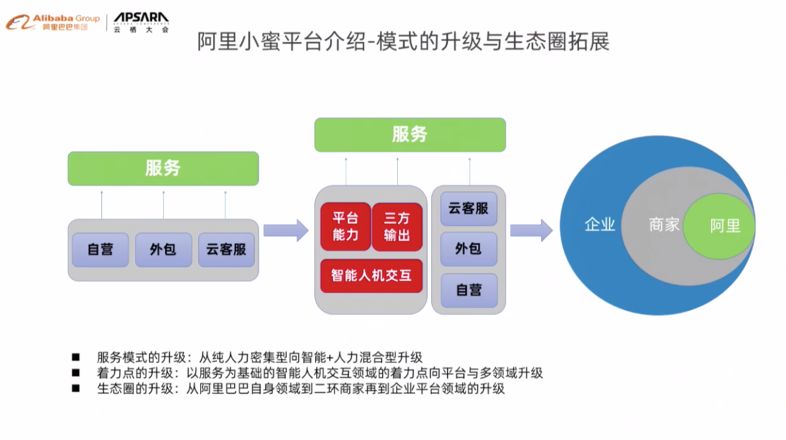
阿里发布NLP和MT自学习平台,还剖析了小蜜平台的NLP技术实践
随着BERT、XLNET等新技术的涌现,深度NLP在语言分析、理解和处理等问题上继续取得突飞猛进的发 随着BERT、XLNET等新技术的涌现,深度NLP在语言分析、理解和处理等问题上继续取得突飞猛进的发展...

Meta发布新AI模型Segment Anything 可检测图像中物体
站长之家4月6日 消息:Meta在人工智能方面有很大的野心,但却一直追不上OpenAI、微软甚至是谷歌的步伐。现在,这家公司发布了最新AI模型,可从图像中识别单个物体。 当地时间周三,Meta发布了其...

区块链技术是什么?有哪些应用场景?
现在很多人多少有点把区块链技术神话了!认为区块链是一种万能的技术,无所不能!在区块链技术的定义上,美国学者梅兰妮⋅斯万在其著作《区块链:新经济蓝图及导读》定义区块链技术是一种公开透...

Web常见的漏洞描述与修复方案
1.SQL注入 漏洞描述 Web程序中对于用户提交的参数未做过滤直接拼接到SQL语句中执行,导致参数中的特殊字符破坏了SQL语句原有逻辑,攻击者可以利用该漏洞执行任意SQL语句,如查询数据、下载数据...
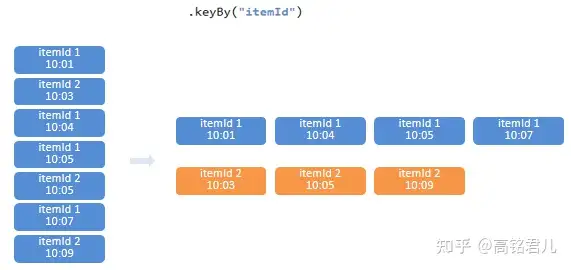
Flink实战小练习
写这篇文章,记录我2019年时做Flink的编程练习,记录一些关键思想套路,为以后举一反三,触类旁通之用。以下需求都非常基础和简单,关键在思路,不在意代码细节。 项目场景 普通的互联网电商平...

VR开发 – Unity环境搭建-新手教程
大家好,我是李康Max,一个学开发的产品经理。 他急了!他急了!远程法师拔剑啦! 为什么VR产品经理要学习使用unity游戏引擎呢? 扎克伯格亲手开发的Facebook; 雷军大学期间就开发了杀毒软件并...

