
spark共74篇
排序

高效扩展Hadoop与Spark的数据处理工具:DataFu
Apache DataFu 是一个开源的 Apache 项目,它是一个用于大数据处理和数据分析的库。它提供了一组功能丰富的工具和函数,用于在 Apache Hadoop 和 Apache Spark 等分布式计算框架上进行数据转换...

百度马小龙:Spark在百度的工程实践分享
原标题:百度马小龙:Spark在百度的工程实践分享 2015年4月16-18日,由CSDN主办、CSDN专家顾问团支持的 OpenCloud 2015大会将在北京国家会议中心拉开帷幕。为期三天的大会,以推进行业应用中的...
如何应对大数据分析工程师面试Spark考察,看这一篇就够了
作者丨斌迪、HappyMint 来源丨大数据与人工智能(ID:ai-big-data) 【导读】本篇 为什么考察Spark? Spark作为大数据组件中的执行引擎,具备以下优势特性。 高效性。内存计算下,Spark 比 MapRe...

Spark从入门到精通(07):Spark SQL和DataSet
了解更多推荐系统、大数据、机器学习、AI等硬核技术,可以关注我的知乎,或同名微信公众号在前面两篇文章中,我们讨论了Spark SQL和DataFrame API。我们研究了如何连接到内置和外部数据源,查看...

Spark流式数据处理——Spark Streaming
Spark Streaming简介 Spark Streaming是Spark核心API的一个扩展,可以实现实时数据的可拓展,高吞吐量,容错机制的实时流处理框架。 Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flum...
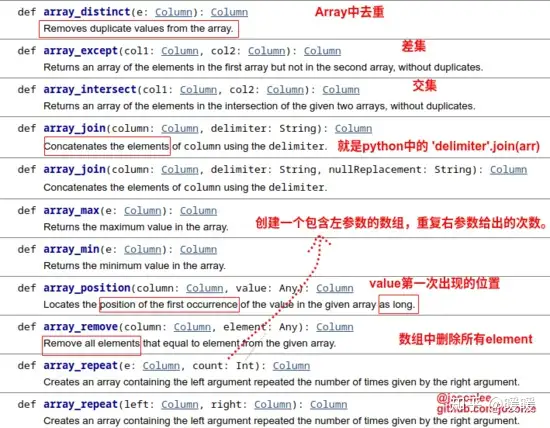
用Spark处理复杂数据类型
转载 用 Spark 处理复杂数据类型(Struct、Array、Map、JSON字符串等) 处理 Structs 的方法 scala> val complexDF = df.selectExpr('struct(Description,InvoiceNo) as complex','Descripti...
我的面板

看一看

「整数智能」获数千万Pre A轮融资,AI大模型重构数据标注生产效率
文丨李安琪编辑丨李勤36氪获悉,AI数据公司「整数智能」于近期完成了数千万Pre A轮融资,本轮由翊宙资本、藕舫天使、安益盛银、图灵启真投资,翊尚资本为独家融资顾问。据悉,本轮融资主要用于...
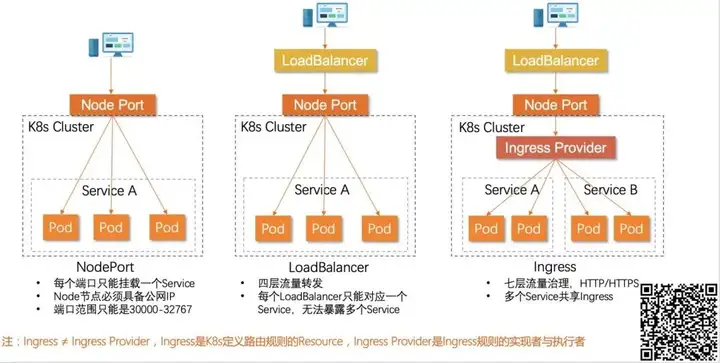
从概念、部署到优化,Kubernetes Ingress 网关的落地实践
Kubernetes Ingress 简介 通常情况下,Kubernetes 集群内的网络环境与外部是隔离的,也就是说 Kubernetes 集群外部的客户端无法直接访问到集群内部的服务,这属于不同网络域如何连接的问题。解...
美国西北大学芬伯格医学院基于浪潮AI服务器开发NLP辅助放射影像检查随访
北京2022年7月6日 /美通社/ -- 随着人工智能不断向行业应用渗透,多技术交叉正在给各个领域的创新带来新的想象力。在医疗健康领域,AI专家和医学专家们正在一起推动从疾病辅助诊断、辅助决策、...

web前端学习容易吗,怎么学习比较好
原标题:web前端学习容易吗,怎么学习比较好 web前端相对于其它的编程语言来说还是比较简单的,对小白比较友好,因为基础比较简单容易上手,尤其是有一定编程基础的人来说。那么怎么学习web前端...
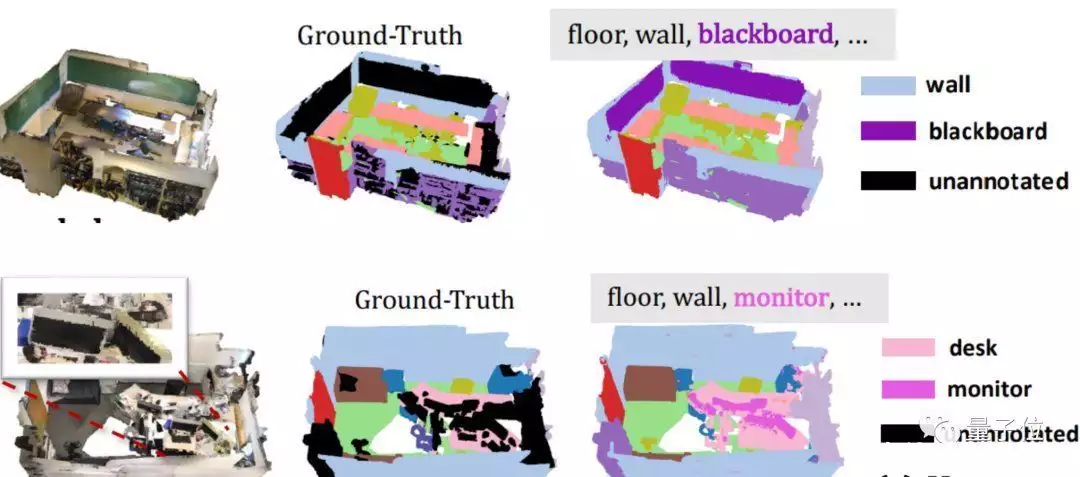
3D模型分割新方法解放双手!不用人工标注,只需一次训练80年代东京红灯区老照片:女孩身穿和服笑脸迎客,站街女随处可见
丁润语 投稿 量子位 | 公众号 QbitAI 3D模型分割现在也解放双手了! 香港大学和字节梦幻联动,搞出了个新方法: 不需要人工标注,只需要一次训练,就能让3D模型理解语言并识别未标注过的类别。 ...
AI绘画lora模型篇,stable diffusion 生成模型基础知识,看完就会
前言 最近一直有粉丝在后台留言,说哪怕有完整的提示词信息,也无法对原始图片进行复原。其实如果想复原一张图片,需要用到的参数和注意事项比较多,另外就是即使你的生成参数完全一致,不同的...

