
spark共74篇
排序
Spark 凭什么成为最火的大数据计算引擎?| 极客时间
原标题:Spark 凭什么成为最火的大数据计算引擎?| 极客时间 现在,几乎所有公司都离不开推荐、广告、搜索这 3 类业务场景,因此 Spark 也相应成了大多数互联网公司的标配: 美团在 2014 年就引...

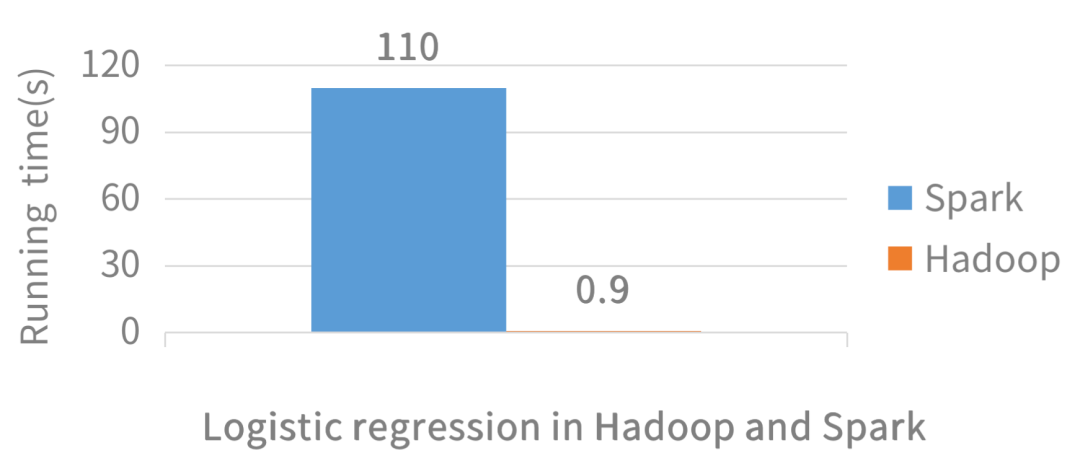
spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...

AI大模型团队Colossal-AI破局创新,火热招募中!
公司简介 潞晨科技致力于解放 AI 生产力,通过高效多维并行、异构内存管理、大规模优化库、自适应任务调度等自研技术,打造面向大模型时代的通用深度学习系统 Colossal-AI ,高效促进 AI 大模型...

YARN资源分配,没有比这说的更清楚的了
让你彻底搞明白YARN资源分配 - 知乎 (zhihu.com)本篇要解决的问题是:Container是以什么形式运行的?是单独的JVM进程吗?YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚...

高效扩展Hadoop与Spark的数据处理工具:DataFu
Apache DataFu 是一个开源的 Apache 项目,它是一个用于大数据处理和数据分析的库。它提供了一组功能丰富的工具和函数,用于在 Apache Hadoop 和 Apache Spark 等分布式计算框架上进行数据转换...

大数据开发:Hadoop、Spark、Flink三大框架对比
目前来说,大数据领域最为活跃的三个计算框架,当属Hadoop、Spark以及Flink这三者。三个框架在不同的大数据处理场景当中,表现各有优势,因此也常常被拿来做比较。今天我们也来做个对比,看看Ha...
我的面板

看一看

真·大语言模型Stable Diffusion时刻?StableLM开源,70亿参数在线体验
原标题:真·大语言模型Stable Diffusion时刻?StableLM开源,70亿参数在线体验 新智元报道 编辑:编辑部 【新智元导读】Stability AI也有大语言模型了,现在已有3B和7B的版本。大语言模型的Sta...

推荐一款免费工具确保Kubernetes的部署安全
导语:DevSecOps解决方案提供商Alcide发布了新解决方案的Beta版,该解决方案旨在为Kubernetes部署提供“端到端连续安全护栏”。 sKan,是一个开放和免费的命令行工具,它将Alcide Kubernetes Ad...
Nvidia训练出83亿参数世界最大语言模型,53分钟成功训练Bert
智东(公众号:zhidxcom) 导语:Nvidia训练出世界最大语言模型MegatronLM,模型 智东(公众号:zhidxcom) 导语:Nvidia训练出世界最大语言模型MegatronLM,模型使用了83亿个参数,比Bert大24...
解决两大难题,TDengine 助力亿咖通打造自动驾驶技术典范
小 T 导读:在安全解决方案 SuperCloud 中,亿咖通面临着磁盘占用量大、车辆最新状态实时查询难以实现两个核心问题。最终,他们选择了让 TDengine 承担数据中台的重要角色,负责车辆实时数据的...

Linux vmstat命令详解
Linux命令千千万,而我们在日常工作中真真切切用到的命令应该不超过50个,在接下来的日子里,我会对 Linux命令千千万,而我们在日常工作中真真切切用到的命令应该不超过50个,在接下来的日子里...

游戏人,卷得过AI吗?二战时期,几名吉普赛女人被迫脱光上衣,露出胸部勒令拍照
编者按:本文来自微信公众号 深燃(ID:shenrancaijing),创业邦经授权发布。 2023年,AI的热潮席卷各行各业。相比于大语言模型ChatGPT,AI绘画火得更早,目前看来,在市场上的应用也来的更早...

