
spark共74篇 第5页
排序
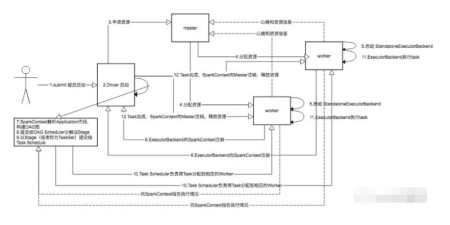
大数据开发之Spark 基础入门学习
集群相关 Cluster Manager指的是在集群上获取资源的外部服务,为每个spark application在集群中调度和分配资源的组件,目前有三种类型: Standalone:Spark 原生的资源管理,由 Master 负责资源...

spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...

spark处理大数据有什么优势(大数据 spark架构)大数据入门:Spark Streaming实际应用
作为Spark负责流计算的核心组件,Spark Streaming是整个Spark学习流程当中非常重要的一块。对于Spark Streaming,作为Spark流计算的实际承载组件,我们也需要更全面的掌握。今天的大数据入门分...

MapReduce和Spark的区别是什么?
首先大数据涉及两个方面:分布式存储系统和分布式计算框架。前者的理论基础是GFS。后者的理论基础为MapReduce。MapReduce框架有两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combin...
T-thinker|继MapReduce,Apache Spark之后的下一代大数据并行编程框架
机器之心专栏 严达 (Daniel Yan)| yanda@uab.edu 计算机科学系助理教授 | 美国阿拉巴马大学伯明翰分校 [欢迎随时跳过文字看最后的讲座视频直接了解 T-thinker]。 什么?是不是又是一个关于设...

大数据培训如何优化HiveSQL
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数...
我的面板

看一看

deepfacelab AI换脸训练参数详解
导言 训练时有许多参数,对不懂机器学习的萌新来说简直就是天书 本篇教程就带大家揭开训练时各参数的含义与效果,同时给出建议数值 我尽量用通俗易懂的语言来解释每一条参数的作用,不需要机器...
AI绘画软件免费吗?有哪些免费的ai作画平台!
AI绘画属于元宇宙的范畴,当下,有很多的科技公司都在积极布局元宇宙,而AI人工智能绘画,或许是他们竞争元宇宙一个非常重要的产品。 正因为如此,很多诸如谷歌、微软等大厂纷纷推出了相应的AI...
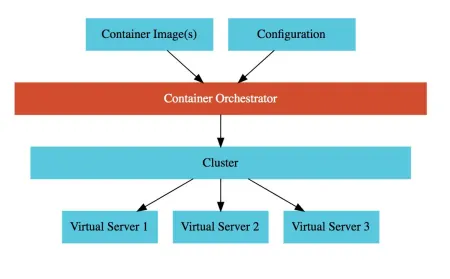
5 个重要的 Kubernetes 概念让学习变得简单
开始使用 Kubernetes 并不容易。本文将帮助您了解 Kubernetes 的一些最重要的概念。 每日分享最新,最流行的软件开发知识与最新行业趋势,希望大家能够一键三连,多多支持,跪求关注,点赞,留...

Kubernetes 真的很难吗?明星在资本面前有多卑微?杨颖被摸胸抱起,林更新被怒骂不敢回嘴
【CSDN 编者按】Kubernetes 提供了许多开箱即用的好东西,可以推进业务的发展。但这是否意味着,所有服务都要放到 Kubernetes 上运行?当然不是。 原文链接:https://rcwz.pl/2023-03-26-kubern...

警告!Kubernetes集群正在遭挖矿劫持,这一次目标是Kubeflow,微软ASC呼吁:不要随意更改默认设置
Azure Kubernetes又被盗了! 6月10日,微软Azure安全中心(ASC)正式发出警告,黑客正在对Kubernetes集群中的机器学习工具包Kubeflow安装加密货币旷工,试图利用CP Azure Kubernetes又被盗了! ...

推荐一款免费工具确保Kubernetes的部署安全
导语:DevSecOps解决方案提供商Alcide发布了新解决方案的Beta版,该解决方案旨在为Kubernetes部署提供“端到端连续安全护栏”。 sKan,是一个开放和免费的命令行工具,它将Alcide Kubernetes Ad...

