
spark共74篇 第3页
排序
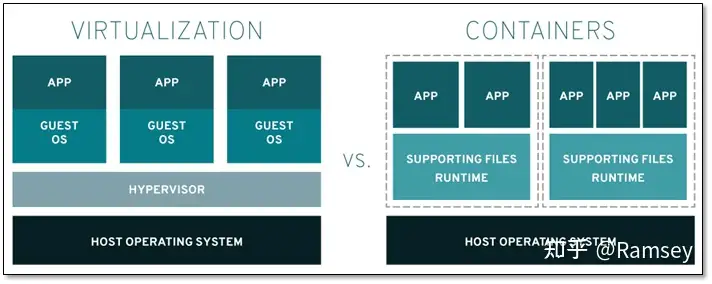
Hadoop + Spark 完全分布式学习环境搭建(Docker版)
计算机中所有程序都要寄托一个环境运行,环境可以理解为一个程序运行所需要的条件的集合;如果只是为了写一个Java程序,它是单进程的,那么我们配置jdk、jre就可以了;如果写一个网站,有前后端...

7个简单的Java性能调优技巧
大多数开发人员都认为性能优化是一个复杂的主题,需要大量的经验和知识。优化应用程序以获得最佳性能并非易事。有几个易于遵循的建议和最佳实践可帮助你创建性能良好的应用程序,这些建议中的大...
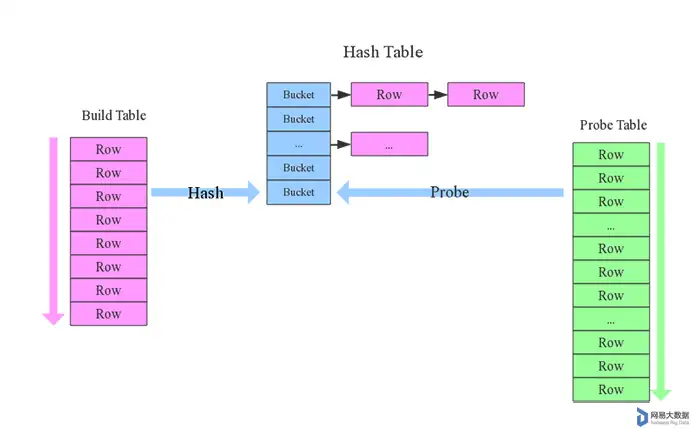
spark大数据分析项目(spark大数据平台的基本构架)SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 。 Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景。 Join背景介绍 Join...
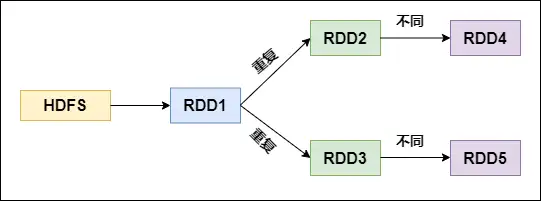
Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
Spark调优之RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下...

spark driver日志(spark 查看yarn日志)基于Spark的大规模日志分析
本文分享自华为云社区《【实战经验分享】基于Spark的大规模日志分析【上进小菜猪大数据系列】-云社区-华为云》,作者:上进小菜猪。 随着互联网的普及和应用范围的扩大,越来越多的应用场景需要...
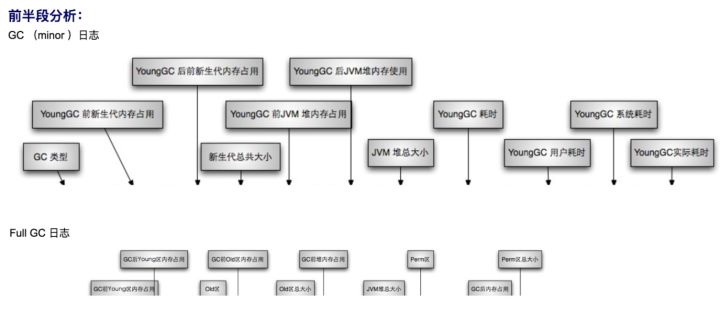
阿里面试100%问到,JVM性能调优篇
JVM 调优概述性能定义吞吐量 - 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。延迟 - 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集...
我的面板

看一看

职业空窗太久,求职信该怎么写?
原标题:职业空窗太久,求职信该怎么写? 简历中职业空窗期太久,找工作时,你就得在求职信里补充说明这点。 求职信是雇主与你之间的第一次沟通,你需要在其中 强调自己的空窗期并不应该成为用...
Rust语言从入门到精通系列 – 零基础lru缓存模块实战
LRU(Least Recently Used)是一种缓存替换算法,它的核心思想是当缓存满时,替换最近最少使用的数据。在实际应用中,LRU算法被广泛应用于缓存、页面置换等领域。Rust语言提供了一个lru模块,...

Uber AI 简单方法实现大规模语言模型的精细控制
OpenAI 的 GPT-2 曾经掀起的「大规模语言模型到底水平多高、到底有没有危害」的口水仗慢慢冷下去了,而语言模型的实用性问题也越来越展现出来:如果很难控制一个语言模型的输出,那可能就很难找...
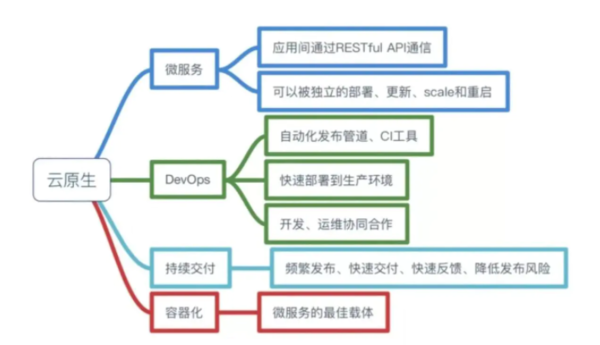
Kubernetes联合创始人Brendan Burns:开放、革新的K8s为客户创造更多价值
随着金融、制造、政务等领域的企业转型上云,云市场正在迎来全新的“云原生”发展阶段。据Gartner云计算技术成熟度曲线显示,以容器管理、无服务PaaS、微服务等为代表的云原生技术,经历“起步...

如何建立Kubernetes治理战略
原标题:如何建立Kubernetes治理战略 译者 | 李睿 治理可带来一致性和可重复性,以确保质量永远不会降低。制定Kubernetes治理模型有助于保持整个组织的正常运行。此外,Kubernetes治理模型中提...
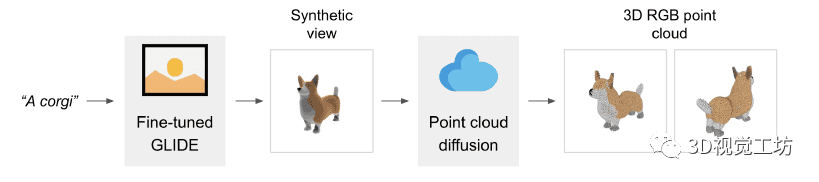
Point-E:使用扩散模型从文本提示中生成3D点云
虽然最近关于根据文本提示生成 3D点云的工作已经显示出可喜的结果,但最先进的方法通常需要多个 GPU 小时来生成单个样本。这与最先进的生成图像模型形成鲜明对比,后者在几秒或几分钟内生成样本...

