
spark共74篇 第8页
排序

Spark性能优化总结(建议收藏)
近期优化了一个spark流量统计的程序,此程序跑5分钟小数据量日志不到5分钟,但相同的程序跑一天大数据量日志各种失败。经优化,使用160 vcores + 480G memory,一天的日志可在2.5小时内跑完,下...

大数据技术学习之Spark技术总结
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数...

每日互动成立大数据联合实验室 助力公共大数据应用创新
本报见习记者吴文文 近日,浙江每日互动网络科技股份有限公司(股票简称:每日互动;股票代码,300766)与浙江省温州市人民政府签署了战略合作协议。作为战略合作的一部分,每日互动与温州市大数...

破题大数据应用难点,TalkingData发布城市大数据场景创新平台
11月25日,T11 2019暨TalkingData数据智能峰会在北京中国大饭店举办。会议期间,TalkingData正式发布“城市大数据场景创新平台”,并与武汉市东湖高新区签订“TalkingData华中研发总部、全国交...

spark—实践之DataSet实战企业人员管理系统应用案例
此案例参考书籍《Spark大数据商业实战三部曲》,特做学习笔记,巩固学习过程。案例预览:给每位员工的年龄增加100给特定的员工年龄增加70,其他增加30对人员信息中的重复数据进行去重按年龄进行...

pyspark处理数据基本语法
作为一个和数据相关的专业,想学习pyspark,从而了解并学习pyspark ,以便更好的应用到工作中。 1、连接数据库 import findspark #初始化 findspark.init() import warnings warnings.filterwarn...
我的面板

看一看
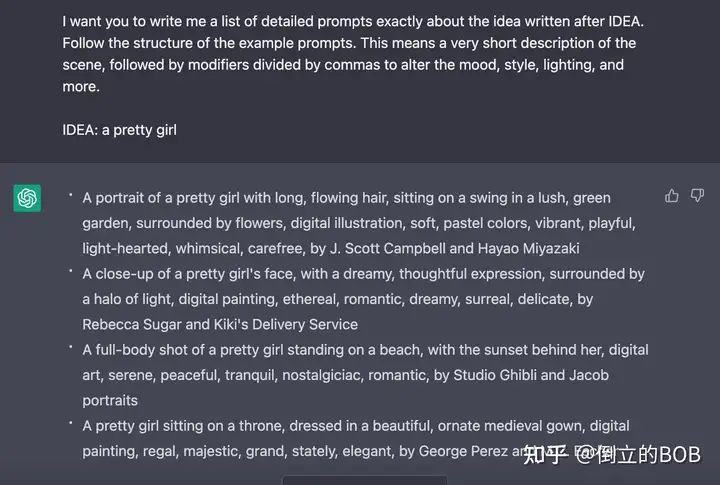
如何用 ChatGPT 生成惊艳的 AI 绘画描述词? – AI 绘画每日一帖
最近由 OpenAI 发布的 ChatGPT 迅速走红,仅一周就获得了 100 万用户。这个令人印象深刻的 AI 可以完成各种各样的任务,例如回答问题、生成故事、对话交流、生成代码、解释复杂的概念等等。国外...

非科班运维开发转NLP 40万的经验:LeetCode不能漏刷
背景: 末流211,非计算机专业硕士,两年半devops经验。 我是NLP就业班学员,之前有一定的机器学习和CV的基础。由于没有项目经验,也没想好自己要从事传统机器学习、图像还是其他机器学习领域,...
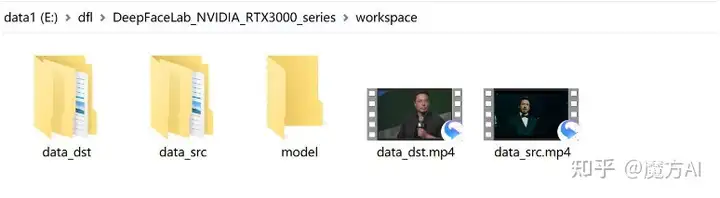
DeepFaceLab教程:工作目录和基本概念
上一篇文章我们已经讲了安装DeepFaceLab所需要的软硬件环境。正常来说就可以进入安装,实操的阶段了。但是,我觉得安装之前还是要先结合workspace来讲一些概念,这样用起来会更加顺畅。workspac...

Flink入门实战(上)
一、Flink 简介 1、初识 Flink Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林 的大学和欧洲的一些其他的大学共同进行的研究项目,2014 年 4 月 Stratosphere...
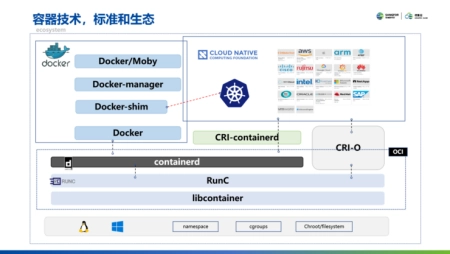
云集技术学社|容器技术和Docker介绍
1月20日,深信服大云售前专家YJ在信服云《云集技术学社》系列直播课上进行了《容器技术和Docker介绍》的分享,详细介绍了容器技术的发展、以Docker为代表的容器技术生态以及容器技术的应用场景...
JS常见的报错及异常捕获,
在开发中,有时,我们花了几个小时写的Js 代码,在游览器调试一看,控制台一堆红,瞬间一万头草泥马奔腾而来。至此,本文主要记录Js 常见的一些错误类型,以及常见的报错信息,分析其报错原因,...

