
spark共74篇 第5页
排序
手把手教你在本机配置spark
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark系列的第一篇文章。 最近由于一直work from home节省了很多上下班路上的时间,加上今天的LeetCode的文章篇幅较小,所以抽出了...

破题大数据应用难点,TalkingData发布城市大数据场景创新平台
11月25日,T11 2019暨TalkingData数据智能峰会在北京中国大饭店举办。会议期间,TalkingData正式发布“城市大数据场景创新平台”,并与武汉市东湖高新区签订“TalkingData华中研发总部、全国交...
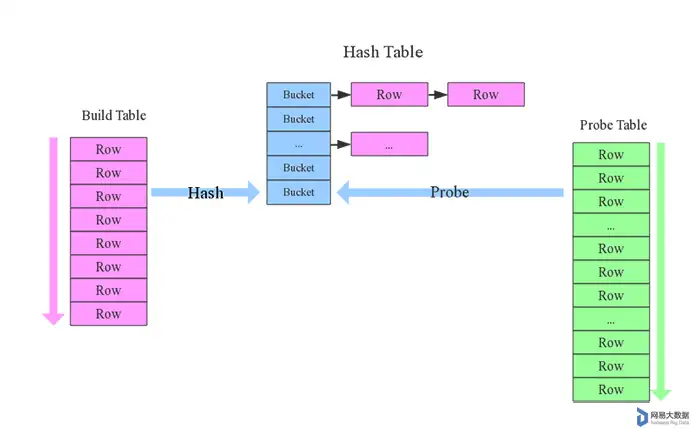
spark大数据分析项目(spark大数据平台的基本构架)SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 。 Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景。 Join背景介绍 Join...

MapReduce和Spark的区别是什么?
首先大数据涉及两个方面:分布式存储系统和分布式计算框架。前者的理论基础是GFS。后者的理论基础为MapReduce。MapReduce框架有两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combin...

深入浅出Spark(1)什么是Spark
今天开始我们将一起学习Sameer Farooqui在Spark summit 2015上分享的内容。本文是“深入浅出Spark”系列文章的第一篇,通过本篇文章我们将了解: 1. Spark是什么 2. Spark生态圈 3. Spark的优点...
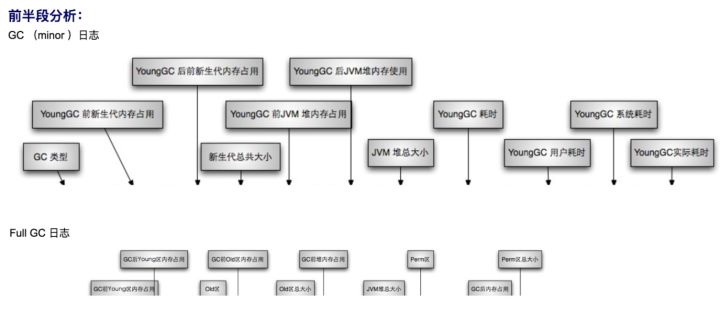
阿里面试100%问到,JVM性能调优篇
JVM 调优概述性能定义吞吐量 - 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。延迟 - 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集...
我的面板

看一看

对话彭博:开源LLM「RWKV」打造AI领域的Linux和Android
作者|沈筱编辑|王与桐“我们没有护城河,OpenAI也是。”近期,谷歌内部人士在Discord社区匿名共享了一份内部文件,点破了谷歌和OpenAI正面临的来自开源社区的挑战。尽管经外媒SemiAnalysis求...

3D视觉点云数据处理十大方法
本篇转载自3D视觉开发者社区用户“悟空”原文链接:3D视觉点云数据处理十大方法 导语 本文主要介绍三维计算机视觉中点云数据处理面对的问题,主要方法和技术,概述其特点。ICP点云配准就是我们...

2023世界人工智能大会“AI生成与垂直大语言模型”论坛重磅来袭!那个高考故意考0分,写8000字抨击高考制度的蒋多多,现在怎样?
当前AI生成与大语言模型的指数级发展,为相关产业链带来新的发展引擎,也为AI落地应用带来新的想象空间。7月7日上午,在世界人工智能大会组委会办公室和共青团上海市浦东新区委员会的指导下,上...


浏览器中的三维空间「Three.js场景搭建」
在第一章《Three.js初体验》 中,大致介绍了在网页中渲染三维场景的简要流程。距离上一章已经过去了两周,如果你充满好奇心,并且有足够的执行力的话,相信你已经能读懂简单的JavaScript和HTML...

“ChatGPT克星”升级:老师可以把全班作业丢进去检测了!华人作者:免费用
混写也能测,还支持Word等格式。 金磊 发自 凹非寺 「ChatGPT克星」,升级了! 没错,就是之前华人小哥Edward Tian所打造出来的那个GPTZero,几秒内就能摸清文字是人类还是AI写的。 打开凤凰新...

