
spark共74篇 第3页
排序

代号spark国际服调中文方法,非常简单
原标题:代号spark国际服调中文方法,非常简单 有很多喜欢玩游戏的朋友最近应该都听说过代号spark国际服这款游戏,因为这款游戏的地图非常大,可以让玩家在游戏中自由探索。4月23日代号spark国...

spark大数据教程(spark大数据分析源码解析)《Spark大数据分析实战》笔记
写在前面:此书很棒,但需要一定的编程功底,此外强烈建议买书,因为很多架构图、算子列表,我也不会摘抄下来。 第一章 简介 1.Spark执行的特点 Hadoop中包含计算框架MapReduce和分布式文件系统...

代码+案例详解:使用Spark处理大数据最全指南
全文共17984字,预计学习时长30分钟或更长如今,有不少关于Spark的相关介绍,但很少有人从数据科学家的角度来解释该计算机引擎。因此,本文将试着介绍并详细阐述——如何运行Spark?一切是如何...
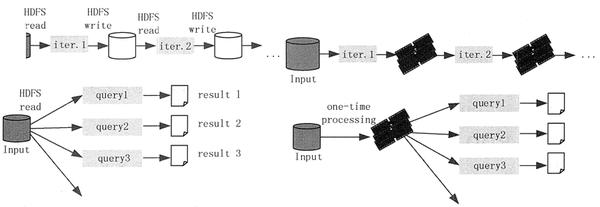
Spark是什么?Spark和Hadoop的区别
Spark 是加州大学伯克利分校 AMP(Algorithms,Machines,People)实验室开发的通用内存并行计算框架。 Spark 在 2013 年 6 月进入 Apache 成为孵化项目,8 个月后成为 Apache 顶级项目。Spark ...

Spark计算引擎:Spark数据处理模式详解
Spark作为大数据领域受到广泛青睐的一代框架,一方面是相比前代框架Hadoop在计算性能上有了明显的提升,另一方面则是来自于Spark在数据处理上,同时支持批处理与流处理,能够满足更多场景下的需...
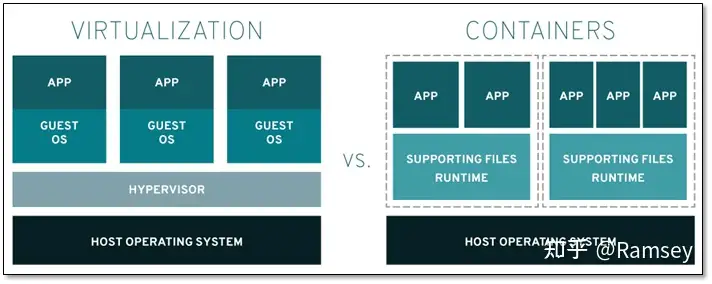
Hadoop + Spark 完全分布式学习环境搭建(Docker版)
计算机中所有程序都要寄托一个环境运行,环境可以理解为一个程序运行所需要的条件的集合;如果只是为了写一个Java程序,它是单进程的,那么我们配置jdk、jre就可以了;如果写一个网站,有前后端...
我的面板

看一看
ChatGPT 有哪些神奇的使用方式?
作者: Fatih Kadir Akın 来源: https://github.com/f/awesome-chatgpt-prompts 编辑: Pytrick介绍 今天为大家介绍的是 “Awesome ChatGPT Prompts” 存储库!这是一组用于 ChatGPT 模型的提示...

强烈推荐:8个Kubernetes运维的技巧
在本文中,我们将探索一些技巧和窍门,这些技巧将使使用Kubernetes更加容易。下面给出的大多数技巧都使用kubectl,这是一个功能强大的命令行工具,可让您对Kubernetes集群执行命令。 1.设置默认...

参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」
编辑:Cris 【新智元导读】谷歌的这项研究,很可能是我们迈向AGI的一大步。 由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。 当扩展...

压测性能分析进阶:XRunner云原生探针
前言 随着信息化系统的建设完整和市场的推广竞争,性能慢慢变成衡量应用是否可用、好用的关键衡量指标之一。性能测试不同于功能测试、接口测试,性能更多关注于业务的响应速度和应用系统的整体...
这7种常见的JavaScript错误,你知道吗?
从浏览器的控制台到运行Node.js的计算机终端,我们到处都会看到各类错误。这篇文章的重点是概述我们在JS开发过程中可能遇到的错误类型。1. RangeError当数字超出允许的值范围时,将抛出此错误。...

Stable diffusion AI画图扩展插件 —— ControlNet 1.1版本介绍(二)
因为在一个篇幅里面写完就太长了,太影响阅读,所以就分成了两部分,这里接上一篇的内容。 四、模型及预处理器 对于ControlNet模型来说,预处理器不是必须的,但我们还是要了解每个模型的预处理...

