
spark共74篇 第12页
排序

内存有限的情况下 Spark 如何处理 T 级别的数据?
UPDATE 1 简单起见,下述答案仅就无shuffle的单stage Spark作业做了概要解释。对于多stage任务而言,在内存的使用上还有很多其他重要问题没有覆盖。部分内容请参考评论中 @邵赛赛 给出的补充。S...
手把手教你在本机配置spark
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark系列的第一篇文章。 最近由于一直work from home节省了很多上下班路上的时间,加上今天的LeetCode的文章篇幅较小,所以抽出了...

Spark性能优化总结(建议收藏)
近期优化了一个spark流量统计的程序,此程序跑5分钟小数据量日志不到5分钟,但相同的程序跑一天大数据量日志各种失败。经优化,使用160 vcores + 480G memory,一天的日志可在2.5小时内跑完,下...

大数据分析技术与实战之 Spark Streaming
Spark是基于内存的大数据综合处理引擎,具有优秀的作业调度机制和快速的分布式计算能力,使其能够更加高效地进行迭代计算,因此Spark能够在一定程度上实现大数据的流式处理。 随着信息技术的迅...
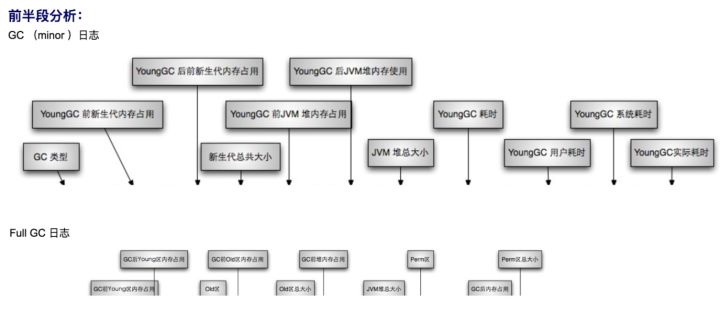
阿里面试100%问到,JVM性能调优篇
JVM 调优概述性能定义吞吐量 - 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。延迟 - 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集...

MapReduce和Spark的区别是什么?
首先大数据涉及两个方面:分布式存储系统和分布式计算框架。前者的理论基础是GFS。后者的理论基础为MapReduce。MapReduce框架有两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combin...
我的面板

看一看

“ChatGPT克星”升级:老师可以把全班作业丢进去检测了!华人作者:免费用
混写也能测,还支持Word等格式。 金磊 发自 凹非寺 「ChatGPT克星」,升级了! 没错,就是之前华人小哥Edward Tian所打造出来的那个GPTZero,几秒内就能摸清文字是人类还是AI写的。 打开凤凰新...

Stable Diffusion怎样训练模型
Stable Diffusion模型是一种在文本到图像生成方面具有很高潜力的模型。本篇文章将介绍如何使用Dreambooth项目进行Stable Diffusion模型训练。从数据准备到模型优化,我们将帮助您掌握和了解训练...
极客们都在玩这些 Terminal!
GitHub 热点速览 | 极客们都在玩这些 Terminal! 以下文章来源于 HelloGitHub ,作者 HelloGitHub 作者 | HelloGitHub- 小鱼干 来源 | HelloGitHub(ID:GitHub520) 头图 | &nbs...

Kubernetes 高可用部署 | 运维进阶
【导读】目前Kubernetes官方以及开源社区都提供了非常多的优秀部署工具,大大简化了Kubernetes的部署难度。本文不限于掌握如何选择合适的工具部署一套高可用的Kubernetes平台,而是在部署实践中...

stable-diffusion干货教学:4GB显存怎么画高分辨率AI图片?没想到,今年“挤奶衫”才是最流行的,谁穿谁好看,显身材有气质
作者:yasden 没有显卡可以AI画图吗?当然可以,只要有cpu就可以AI画图,stable-diffusion免费AI画图工具的安装方法请看下面这篇文章: https://post.smzdm.com/p/a90r8dk5/ 不要以为AI画图只能...
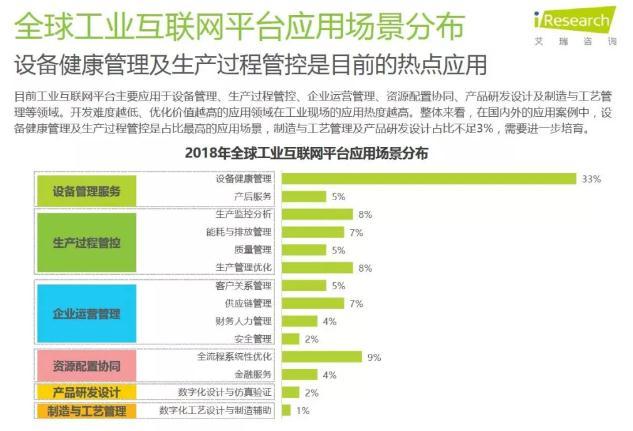
工业互联网技术趋势和主要玩家
“工业互联网,就是把人、数据和机器连接起来,”2012年,美国通用电气公司在提出“工业互联网”概念时 “工业互联网,就是把人、数据和机器连接起来,”2012年,美国通用电气公司在提出“工业...

