
spark共74篇 第10页
排序

大数据培训如何优化HiveSQL
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数...
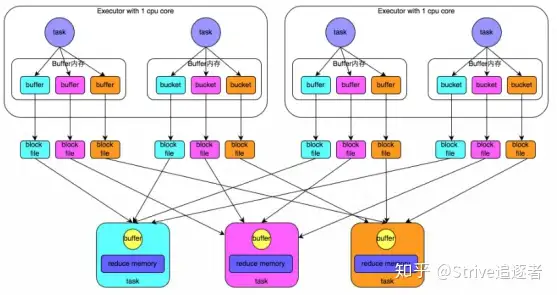
SparkShuffle及Spark SQL图解执行流程语法
1.SparkShuffle 1.1SparkShuffle概念: reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对...
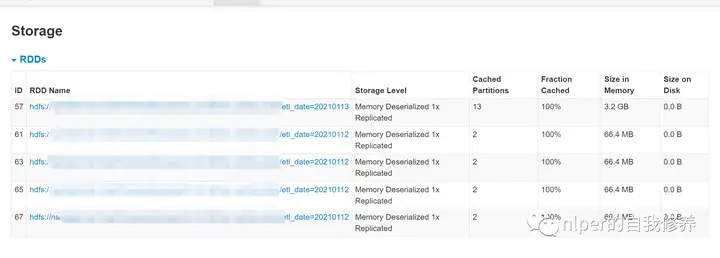
spark性能优化(一)
本文内容说明初始化配置给rdd和dataframe带来的影响repartition的相关说明cache&persist的相关说明性能优化的说明建议以及实例配置说明 spark:2.4.0 服务器:5台(8核32G) 初始化配置项 %...

Spark流式数据处理——Spark Streaming
Spark Streaming简介 Spark Streaming是Spark核心API的一个扩展,可以实现实时数据的可拓展,高吞吐量,容错机制的实时流处理框架。 Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flum...

大数据人才需求怎么样 Spark技术是怎么回事
大数据人才需求怎么样?Spark技术是怎么回事?Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但...

百度马小龙:Spark在百度的工程实践分享
原标题:百度马小龙:Spark在百度的工程实践分享 2015年4月16-18日,由CSDN主办、CSDN专家顾问团支持的 OpenCloud 2015大会将在北京国家会议中心拉开帷幕。为期三天的大会,以推进行业应用中的...
我的面板

看一看

收藏!晶振性能优化与改进的方案
原标题:收藏!晶振性能优化与改进的方案 晶振作为电子设备中的关键元件,其性能直接影响到设备的稳定性和可靠性。为了确保设备能够正常工作,我们需要对晶振进行性能优化与改进。本文将从以下...

小白学AI – YOLOv8目标检测 – 训练自己的数据集(Windows环境)
mac环境训练自己的数据集,这训练时间可闹心了,500张素材,训练400轮,训练了12个小时,才训练100轮,这时间真真是太久了,所以找一台闲置的Windows电脑试试,。弄完发现跟电脑没关系,跟cpu,...
NLP介绍
图片 NLP是什么? NLP来自英文Neuro-Linguistic Programming的前三个字母,是由美国天才年轻理查德•班德勒博士约翰•格林德由上个世纪70年代创造。 N,直译为“神经”,指的是我们的“身心”。...

Linux 系统上安装 Kafka 的详细步骤和命令
以下是在 Linux 系统上安装 Kafka 的详细步骤和命令。下载 Kafka首先,您需要下载 Kafka,可以从官网下载最新版本的 Kafka。假设您要下载的是 Kafka 2.9.2 版本,可以使用以下命令下载:bashwge...

当Swin Transformer遇上DCN,清华可变形注意力模型优于多数ViT
机器之心报道 编辑:小舟 本文中,来自清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置,使得自注意力...

