
spark共14篇 第2页
排序

常用大数据引擎介绍,快速直达工具集
大数据平台是对海量结构化、非结构化、半机构化数据进行采集、存储、计算、统计、分析处理的一系列技术平台。大数据平台处理的数据量通常是TB级,甚至是PB或EB级的数据,这是传统数据仓库工具无...

Spark环境部署
部署预备Hadoop安装spark运行一般依赖Hadoop(也可以不需要)。关于Hadoop的安装,可以参考 使用虚拟机搭建Hadoop集群在安装Hadoop的过程中,需要同时安装jdk8。2. Scala安装解压Scala二进制包到...

代码+案例详解:使用Spark处理大数据最全指南
全文共17984字,预计学习时长30分钟或更长如今,有不少关于Spark的相关介绍,但很少有人从数据科学家的角度来解释该计算机引擎。因此,本文将试着介绍并详细阐述——如何运行Spark?一切是如何...
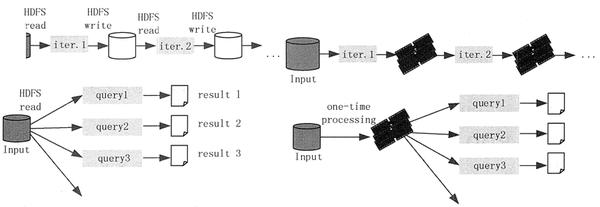
Spark是什么?Spark和Hadoop的区别
Spark 是加州大学伯克利分校 AMP(Algorithms,Machines,People)实验室开发的通用内存并行计算框架。 Spark 在 2013 年 6 月进入 Apache 成为孵化项目,8 个月后成为 Apache 顶级项目。Spark ...
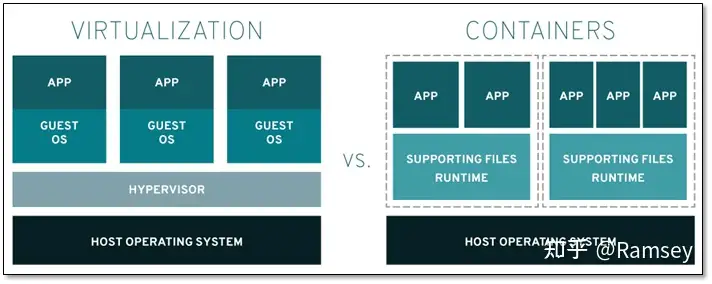
Hadoop + Spark 完全分布式学习环境搭建(Docker版)
计算机中所有程序都要寄托一个环境运行,环境可以理解为一个程序运行所需要的条件的集合;如果只是为了写一个Java程序,它是单进程的,那么我们配置jdk、jre就可以了;如果写一个网站,有前后端...

深入浅出Spark(1)什么是Spark
今天开始我们将一起学习Sameer Farooqui在Spark summit 2015上分享的内容。本文是“深入浅出Spark”系列文章的第一篇,通过本篇文章我们将了解: 1. Spark是什么 2. Spark生态圈 3. Spark的优点...
我的面板


