
spark共14篇 第2页
排序

spark—实践之DataSet实战企业人员管理系统应用案例
此案例参考书籍《Spark大数据商业实战三部曲》,特做学习笔记,巩固学习过程。案例预览:给每位员工的年龄增加100给特定的员工年龄增加70,其他增加30对人员信息中的重复数据进行去重按年龄进行...
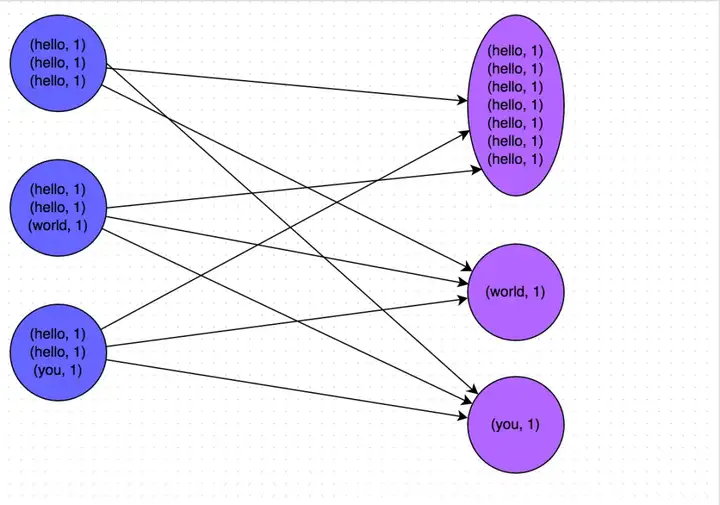
Spark特点及缺点?
本文目录: 一、调优概述 二、数据倾斜发生时的现象 三、数据倾斜发生的原理 四、如何定位导致数据倾斜的代码 五、某个task执行特别慢的情况 六、某个task莫名其妙内存溢出的情况 七、查看导致...

YARN资源分配,没有比这说的更清楚的了
让你彻底搞明白YARN资源分配 - 知乎 (zhihu.com)本篇要解决的问题是:Container是以什么形式运行的?是单独的JVM进程吗?YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚...

代码+案例详解:使用Spark处理大数据最全指南
全文共17984字,预计学习时长30分钟或更长如今,有不少关于Spark的相关介绍,但很少有人从数据科学家的角度来解释该计算机引擎。因此,本文将试着介绍并详细阐述——如何运行Spark?一切是如何...
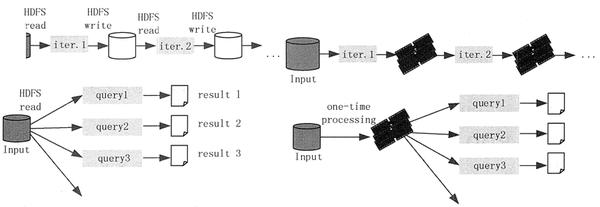
Spark是什么?Spark和Hadoop的区别
Spark 是加州大学伯克利分校 AMP(Algorithms,Machines,People)实验室开发的通用内存并行计算框架。 Spark 在 2013 年 6 月进入 Apache 成为孵化项目,8 个月后成为 Apache 顶级项目。Spark ...

SPARK+HADOOP大数据实验环境配置
最近在上大数据实验的,整理一下配置环境的过程。本文主要包括所需安装包,通用配置、hadoop配置和spark配置。一.实验环境:使用虚拟机软件:VMware Workstation Pro操作系统:Ubuntu 18.04 (mas...
我的面板


