大家都在看

最新发布第9页
排序
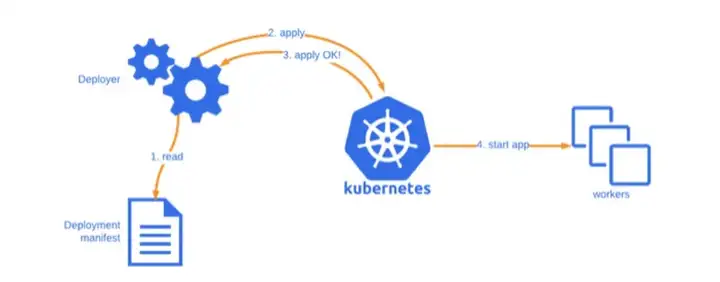
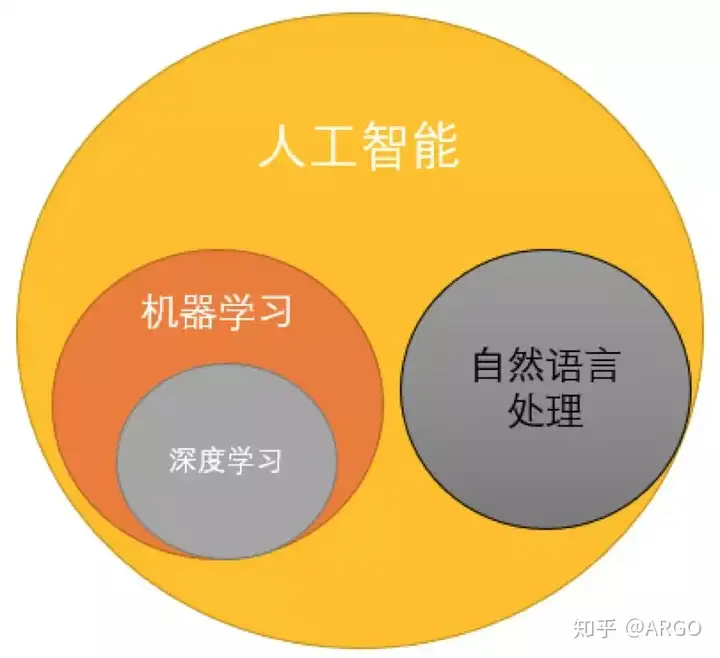
一文了解 Kubernetes
简介:Docker 虽好用,但面对强大的集群,成千上万的容器,突然感觉不香了。这时候就需要我们的主角 Kubernetes 上场了,先来了解一下 Kubernetes 的基本概念,后面再介绍实践,由浅入深步步为...

spark为什么这么快
作者:张科 网上答案都是千篇一律:数据都在内存所以快,是有误区的。 聊spark必须聊rdd, rdd 全英文 Resilient Distributed Datasets,搞懂这三个单词就完事了其实。 Resilient:能复原的,弹...

深入浅出Spark(1)什么是Spark
今天开始我们将一起学习Sameer Farooqui在Spark summit 2015上分享的内容。本文是“深入浅出Spark”系列文章的第一篇,通过本篇文章我们将了解: 1. Spark是什么 2. Spark生态圈 3. Spark的优点...
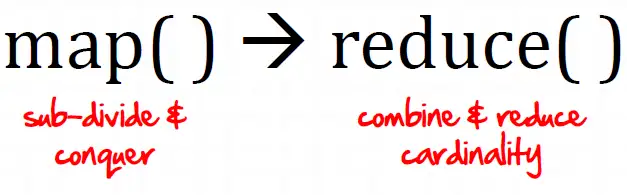
与 Hadoop 对比,如何看待 Spark 技术?
Hadoop 首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。HDFS,在由普通PC组成的集群上提供...

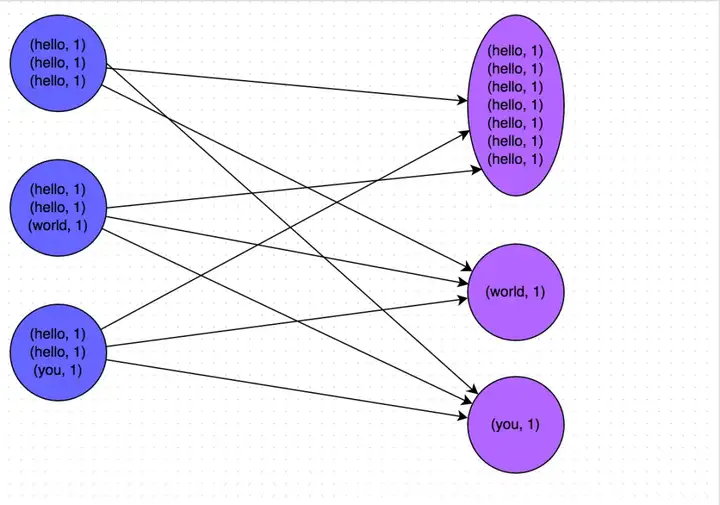
MapReduce和Spark的区别是什么?
首先大数据涉及两个方面:分布式存储系统和分布式计算框架。前者的理论基础是GFS。后者的理论基础为MapReduce。MapReduce框架有两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combin...
Spark特点及缺点?
本文目录: 一、调优概述 二、数据倾斜发生时的现象 三、数据倾斜发生的原理 四、如何定位导致数据倾斜的代码 五、某个task执行特别慢的情况 六、某个task莫名其妙内存溢出的情况 七、查看导致...







VR看房











![表情[haobang]-卡咪卡咪哈-一个博客](https://kmkmha.com/wp-content/themes/zibll/img/smilies/haobang.gif)



