


传特斯拉提议在印度建厂;腾讯一季度营收增长11%;北京拟整合现有开源中文预训练数据集
打开凤凰新闻,查看更多高清图片 Sam Altman 出席美国国会听证会,提出三点监管建议 美国参议院举行针对人工智能举行的首场大型听证会,美国 OpenAI 实验室首席执行官山姆・奥特曼(Sam Altman...
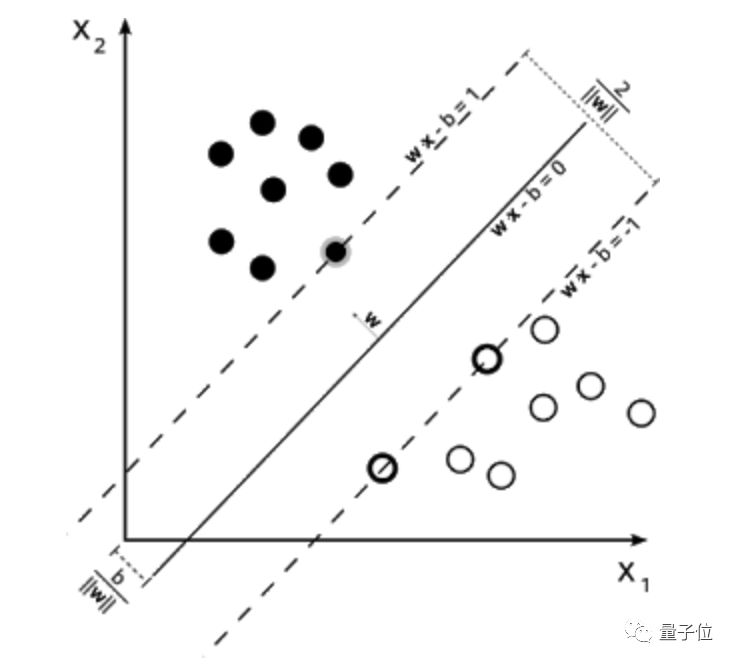
拒绝DNN过拟合,谷歌准确预测训练集与测试集泛化差异,还开源了数据集 | ICLR 2019
鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI 深度神经网络(DNN)如今已经无处不在 深度神经网络(DNN)如今已经无处不在,从下围棋到打星际,DNN已经渗透到图像识别、图像分割、机器...

极客们都在玩这些 Terminal!
GitHub 热点速览 | 极客们都在玩这些 Terminal! 以下文章来源于 HelloGitHub ,作者 HelloGitHub 作者 | HelloGitHub- 小鱼干 来源 | HelloGitHub(ID:GitHub520) 头图 | &nbs...

参数量110亿,附赠750GB数据集,Google提NLP预训练模型T5
整理 | Just,夕颜 出品 | AI科技大本营(ID:rgznai100) 近日,Google 在最新一篇共有 53 页的论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》中...

NLP项目实战必备!16个能降低训练难度的聊天机器人数据集
一个有效的聊天机器人需要大量的训练数据,这样才能在无需人工干预的情况下快速解决用户查询问题。但是,聊天机器人开发的主要瓶颈是获取现实、面向任务的对话数据来训练这些基于机器学习的系统...

在NLP项目中使用Hugging Face的Datasets 库
数据科学是关于数据的。网络上有各种来源可以为您的数据分析或机器学习项目获取数据。最受欢迎的来源之一是 Kaggle,我相信我们每个人都必须在我们的数据旅程中使用它。 最近,我遇到了一个新的...

