


谷歌发布最大语言模型:等于9个GPT-3,训练成本却低得多
杨净 发自 凹非寺量子位 报道 | 公众号 QbitAI今天,谷歌大脑声称,他们新技术能训练万亿级参数的语言模型。 万亿级,什么概念? 烧了微软10000张显卡的GPT-3,也不过1750亿参数。 现在,他们将...

谷歌、DeepMind等发现大语言模型具有原因不明的突现能力,或可推动自然语言处理研究
关于 AI 未来发展的一个关键话题是,扩大规模是否会导致模型的质量产生较大变化。最近,来自谷歌研究院、斯坦福大学、北卡罗来纳大学教堂山分校和 DeepMind的一组研究人员给出了肯定答案。 他们...

DeepMind最新研究:如何将「大语言模型」 训练到最优?
作者丨维克多 Transformer的提出距离我们已经有5年的时间,随着模型规模的不断增长,性能提升也逐渐出现边际效益递减的情况。如何训练出最优性能的大模型? 最近,DeepMind做了一项调查,想弄清...
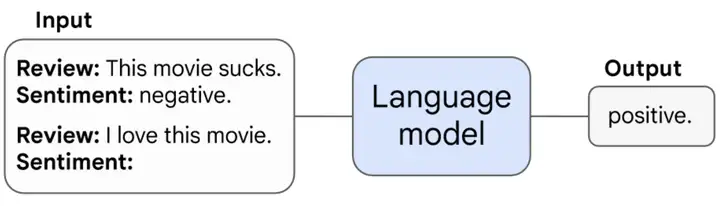
大型语言模型系列解读(一):大语言模型涌现的新能力
语言模型是根据已知文本生成未知文本的模型。自GPT-3以来,大型语言模型展现出了惊人的zero-shot和few-shot能力,即不改变参数仅改变输入的in-context learning。这是与此前流行的finetune范式...

参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」
编辑:Cris 【新智元导读】谷歌的这项研究,很可能是我们迈向AGI的一大步。 由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。 当扩展...
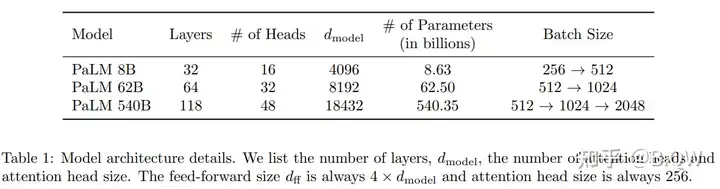
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
《PaLM: Scaling Language Modeling with Pathways》 论文地址:https://arxiv.org/pdf/2204.02311.pdf 一、简介 近些年,超大型神经网络在语言理解和生成的广泛任务上实现了令人惊讶的效果。这...

