


Spark从入门到精通(07):Spark SQL和DataSet
了解更多推荐系统、大数据、机器学习、AI等硬核技术,可以关注我的知乎,或同名微信公众号在前面两篇文章中,我们讨论了Spark SQL和DataFrame API。我们研究了如何连接到内置和外部数据源,查看...

Spark流式数据处理——Spark Streaming
Spark Streaming简介 Spark Streaming是Spark核心API的一个扩展,可以实现实时数据的可拓展,高吞吐量,容错机制的实时流处理框架。 Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flum...
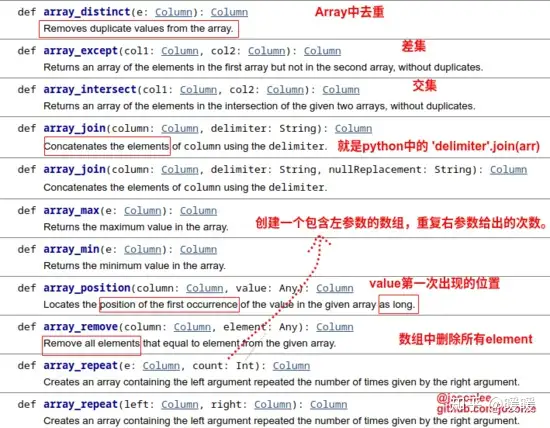
用Spark处理复杂数据类型
转载 用 Spark 处理复杂数据类型(Struct、Array、Map、JSON字符串等) 处理 Structs 的方法 scala> val complexDF = df.selectExpr('struct(Description,InvoiceNo) as complex','Descripti...

Spark计算引擎:Spark数据处理模式详解
Spark作为大数据领域受到广泛青睐的一代框架,一方面是相比前代框架Hadoop在计算性能上有了明显的提升,另一方面则是来自于Spark在数据处理上,同时支持批处理与流处理,能够满足更多场景下的需...

PySpark 处理数据和数据建模
安装相关包 from pyspark.sql import SparkSession from pyspark.sql.functions import udf, when, count, countDistinct from pyspark.sql.types import IntegerType,StringType from pyspark....
内存有限的情况下 Spark 如何处理 T 级别的数据?
UPDATE 1 简单起见,下述答案仅就无shuffle的单stage Spark作业做了概要解释。对于多stage任务而言,在内存的使用上还有很多其他重要问题没有覆盖。部分内容请参考评论中 @邵赛赛 给出的补充。S...

