
AI创作共554篇 第4页
排序
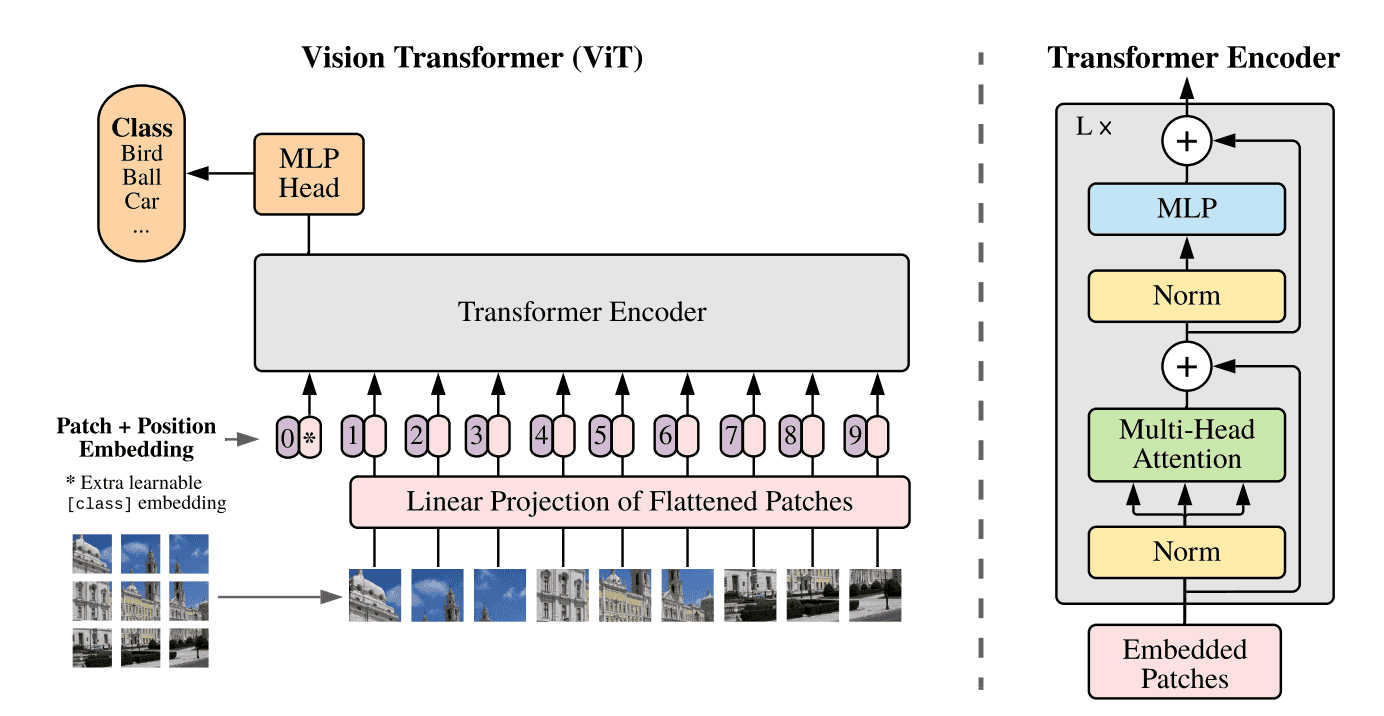
ViT-Vision Transformer 详解
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打...

局部归纳偏置真的有必要吗?探索 Transformer 新范式!
作者丨科技猛兽 编辑丨极市平台 本文目录 1 一个像素就是一个 token!探索 Transformer 新范式 (来自 FAIR, Meta AI,阿姆斯特丹大学) 1 PiT 论文解读 1.1 局部性这个归纳偏置可以在 Transforme...

用 Vision Transformer 进行图像分类
Transformer 问世后被广泛地用在 NLP 的各种任务中,但是却很少出现在计算机视觉领域中。目前计算机视觉主流的模型依然是 CNN,各种 attention 操作也是在 CNN 结构上进行。本文介绍 Vision Tra...
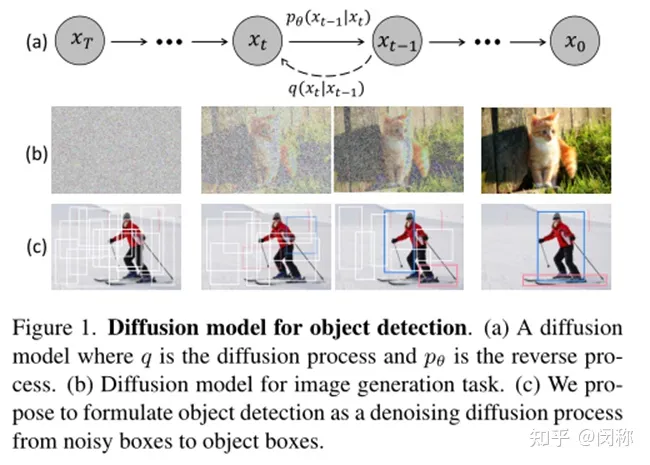
DiffusionDet:基于扩散模型的目标检测框架
扩散模型在生成任务上非常成功,自然就想到将其扩展到其他任务上,果然香港大学的罗平团队就出了这个DiffusionDet。后续是不是可以将其扩展到各种任务上。Denoising Diffusion is all you need...
六、Vision Transformer(ViT)
辰流看完Transformer之后,梦里都是Attention。 谢谢你,nlp。 谢谢你,attention。 谢谢你,transformer。 感谢多了,或许就要流泪了。 俗话说趁热打铁。第五章中的Transformer虽用于nlp领域,...
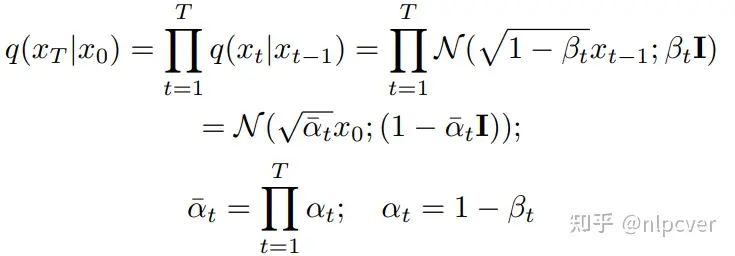
Scalable Diffusion Models with Transformers(DiTs)论文阅读 — 文生视频Sora模型基础结构DiT
文章地址:Scalable Diffusion Models with Transformers 简介 文章提出使用Transformers替换扩散模型中U-Net主干网络,分析发现,这种Diffusion Transformers(DiTs)不仅速度更快(更高的Gflo...
我的面板

看一看

chatgpt使用体验,以及chatgpt注册方法
ChatGPT简介ChatGPT是一款基于AI技术的机器人对话软件,它能够与用户进行智能化的聊天对话,帮助用户解决日常生活中的问题,为用户提供丰富的信息和服务。它集成了海量知识库,能够回答用户的各...
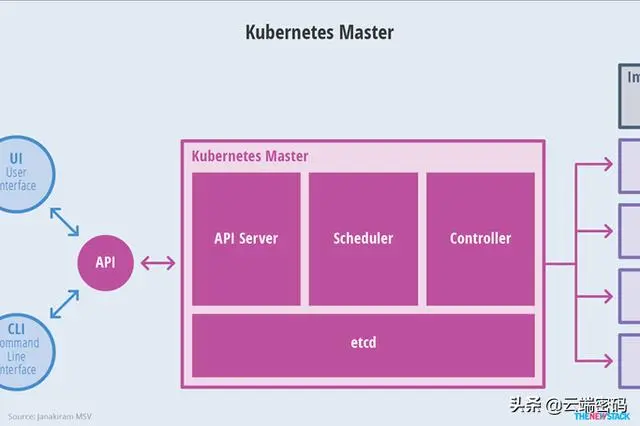
如何正确配置kubernetes集群资源
【本文专栏于[头条号]、[CSDN]同步发布,可关注同名账号订阅相关文章,每周固定更新】 对于大多数刚入门k8s的朋友们来说,k8s强大容器编排功能能让我们把更多的目光聚焦在应用级的系统架构设计...

如何创建高效的Prompt和ChatGPT等大语言模型AI对话
大语言模型,如OpenAI的GPT-4,是一种基于深度学习技术的自然语言处理工具,它可以理解自然语言并为用户提供有价值的回答。然而,要从大语言模型中获得高质量的回答,你需要学会如何高效地提问...

AI绘画使用门槛低普通人也能出佳作 版权归属有待明晰
原标题:零门槛,AI绘画要抢画师饭碗? 本报记者 袁璐 AI(人工智能)绘画火了!只需要输入几个关键词,便能在几十秒内生成一幅精美的画作,还能根据用户偏好的画风调整不同的方案。 2022年被称...
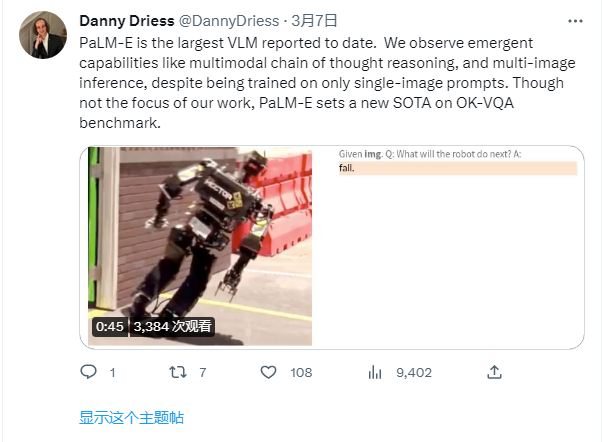
5620亿参数!谷歌发布全球最大视觉语言模型PaLM-E:几乎拥有所有语言能力,能识别图像信息、操控机器人……
过去几个月时间里,由ChatGPT在全球科技巨头之间引发的人工智能热潮推动了大量语言模型的生产力前置。据《华尔街日报》,虽然谷歌早在两年前就做出了类似ChatGPT的人工智能聊天工具,但谷歌对AI...

MEMS技术传感器技术在物联网发展是大势所趋
手机中有多少个单独的组件?陀螺仪和加速度可以检测手机的运动;温度传感器,光传感器,湿度传感器和压力传感器可测量手机的环境;用于连接的RFID、WiFi和蓝牙的传感器,还有用于声音的麦克风和...

