
Hello 小伙伴们大家好,最近在做多模态的工作,然后发现现在NLP和CV的预训练模型结构逐渐趋同,可以说是transformer占据了半壁江山,为了让大家更好的了解这些模型的结构以及实现方法,所以我打算出一系列论文讲解的文章,希望能够帮助大家很好的理解这些模型。
模型结构
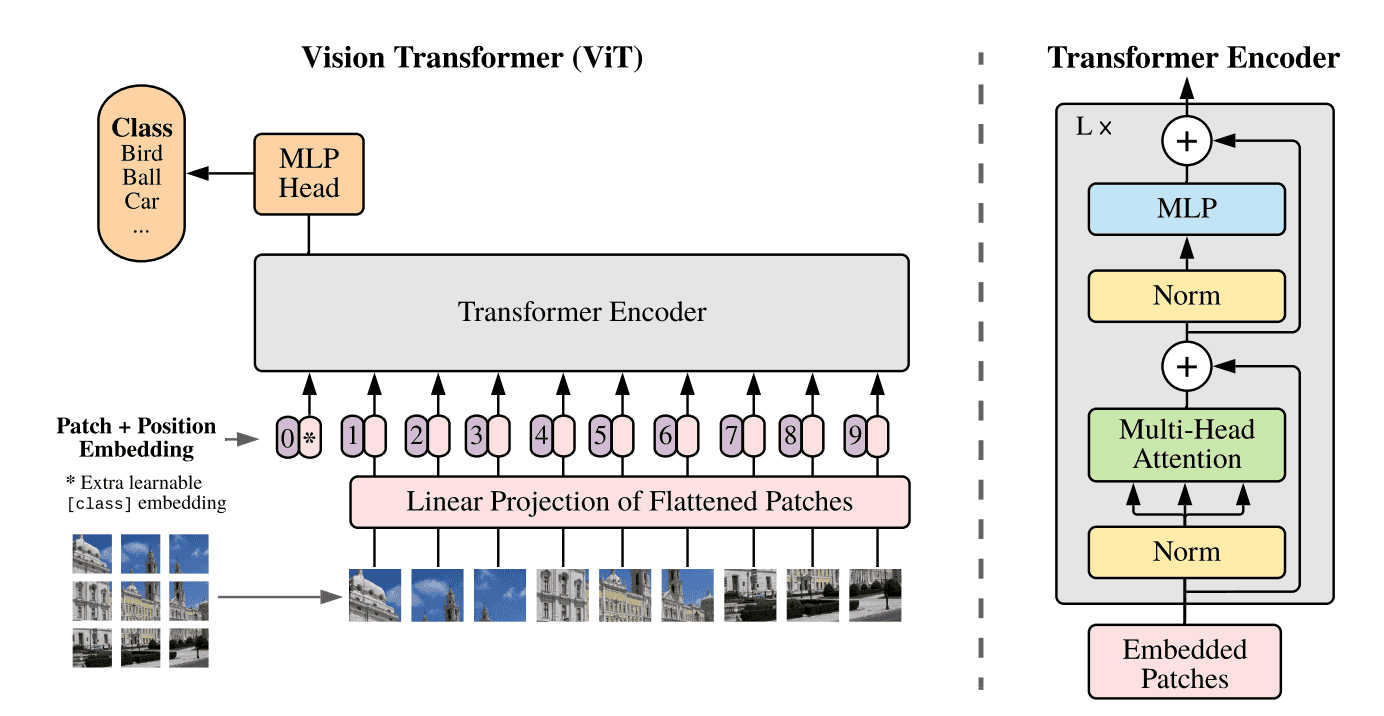
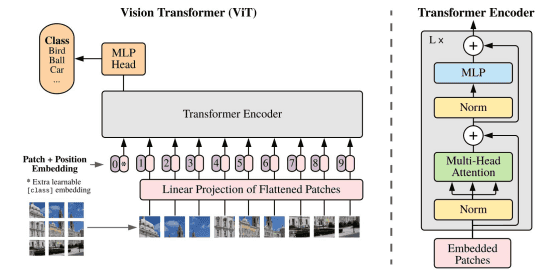
ViT的模型结构实际上就是Transformer的Encoder,主要由三部分组成:ViT Embedding, ViT Attention以及最后的MLP。
ViT Embedding
ViT Embedding主要用来生成图像的patch embedding和每个patch的position embedding,这里的图像patch可以看成是一整张图片的token,patch的生成逻辑也比较简单,就是直接网格划分,例如一张224*224的图像,如果我们设定patch的高和宽都是16,那一张图片可以生成196个patch(224/16的平方嘛),类比于NLP,就相当于一句话由196个词组成一个道理。
得到了一张图像的patch,我们接下来需要做的就是生成这些patch的embedding,生成patch embedding的逻辑也很简单,直接在每个patch后接一个Linear Projection,将16*16的patch映射到一个固定维度的向量空间,假设patch embedding size为1024,那么经过Linear Projection后我们会得到一个196*1024的二维矩阵,矩阵的每一行对应一个patch的embedding,我们总共有196个patch。
Position embedding的生成也比较简单,因为我们有196个patch,我们可以给每个patch打上序号,0,1,2,…,196,代表每个patch在图像中的位置,然后我们就可以随机初始化一个196*1024(position embedding的size也是1024)的二维矩阵,这样在训练的时候模型就会自己学习到每个patch的位置信息。
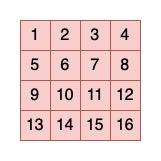
Patch Generation
有了patch embedding和position embedding,我们就可以构建出ViT的输入了。我们现在有两个196*1024的二维矩阵,一个是patch embeddings,一个是position embeddings,两个二维矩阵按行相加就得到了ViT的input,实际上我们还需要再加一个额外的“patch”,也就是BERT中的cls token,用来表示一整张图片的embedding,以便用它进行图像分类任务,所以最终ViT的input是一个197*1024的二维矩阵(196个patch+1个cls token),如果我们设定batch size为32,那ViT的input就是一个32*197*1024的三维tensor。
ViT Attention
ViT attention实际上就是一个multi-head self-attention,self-attention的结构也比较简单,说白了就是加权求和,权重就是attention acore,attention score就是通过query向量和key向量点乘得来的。
首先我们需要对输入的每一个patch,也就是上文提到的197*1024的二维矩阵的每一行生成一个query向量,key向量和value向量,由于这三个向量都是通过patch自身生成的,所以叫self-attention,生成的方法也比较简单,就是linear projection,就是对197*1024的二维矩阵的每一行乘以一个二维参数矩阵,假设query,key,value的维度为128,我们需要乘的这个二维参数矩阵维度就是1024*128,针对于query,key,value我们都有这样的一个参数矩阵,通过矩阵相乘我们就得到了query,key,value,他们的维度都是197*128,每一行代表每个patch对应的Q(K/V)。
我们有了每个patch的query,key,value,接下来就可以算各个patch的attention score了,通过Q和K的点乘我们就得到了各个patch的attention score.
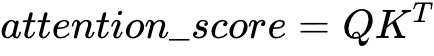
也就是矩阵[197,128].[128,197],最后得到attention score是一个197*197的二维矩阵,矩阵的每一行代表每一个patch相对于其他所有的patch的attention score。
得到attention score后需要对每一行的score分别进行softmax归一化。
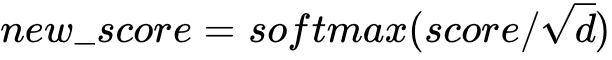
这里的d代表的就是query,key,value的长度,也就是上文提到的128,也就是attention head size。
得到归一化的attention score后就可以跟value加权求和了,转化为矩阵运算就是归一化后的attention score矩阵乘以value矩阵,也就是[197,197].[197,128],最后得到一个197*128的隐状态矩阵,这个隐状态矩阵就是attention过后的值矩阵。
上面我们说的是single head,multi-head就是针对每一个patch生成多个query,key,value,然后算多个attention score矩阵,最后分别加权求和。在具体实现过程中,需要我们指定一下hidden_dim和the number of head,例如我们假设hidden_dim=768,head=12,那每个query,key,value的长度就是64,针对每一个attention head我们都会得到一个197*64的隐状态矩阵,所以最终的隐状态矩阵就是一个197*768的矩阵,因为我们有12个attention head。具体实现可以参考视频ViT 代码逐行解读,这里只跟大家介绍大致逻辑。
MLP
通过上文ViT Attention的解读,我们知道最终multi-head attention的输出是一个197*768的矩阵,矩阵的每一行代表每个patch的隐状态向量。Encoder的最后一个组件就是MLP,一个简单的全连接网络,针对于隐状态矩阵的每一行也就是每个patch的隐状态向量我们都会在其后接一个全连接网络,如果这个全连接网络的输出维度是1024,那么最终我们会得到一个197*1024的矩阵。
以上ViT encoder layer的三个主要部分就讲解完了,剩下的两个就是残差连接和Layer Normalization。我们将上述结构总结如下:
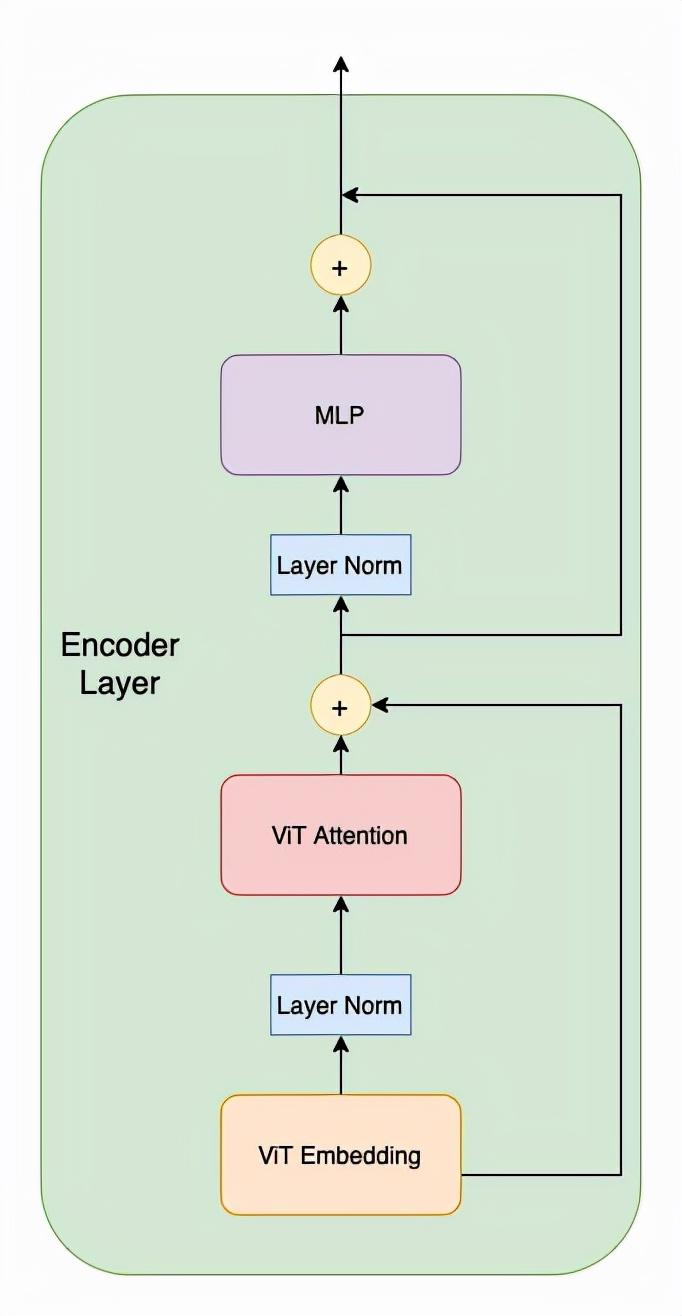
事实上ViT就是由多个Encoder Layer堆叠而成。如果大家还有不清楚的地方欢迎评论区留言,或者观看视频讲解以及ViT代码逐行讲解。


















暂无评论内容