
打通的壁垒
回顾一下,在Transformer中,计算自注意力权重的时候,需要序列中的元素两两计算相似度(或者叫相容性函数),其计算复杂度是 O(n2)O( n^{2} )。所以,如果序列长度太长的话,计算复杂度很可能承受不了。
所以说想要直接将Transformer应用到CV领域,直接将一张图片拉直后将每个像素都看做一个序列中的点,就算一个224X224像素的图片,那么序列长度就会有5w+,这个时候再平方,也太大了,更不要提高清图片了。
怎么办呢?有几种思路:
1、限制注意力计算的范围:
只对元素前后附近的像素计算相似度。
只对小窗口内的像素计算相似度。
只按轴计算相似度,图片中的同一行、同一列元素。
计算注意力的时候用稀疏的方式,采样一定的元素进行计算,可以做k次,复杂度从O(n2)O( n^{2} ) 降到 k∗(n/k)2k*(n/k)^{2}2、想办法将维度降下来:
比如先用CNN提取feature map,再在上面使用自注意力机制。这种方案是CNN和transformer的混用。
3、直接将图片划分成小格子,再进行embedding后将其视为nlp中的word。
这样直接可以只用transformer,不用CNN。同时,格子划分的粗细大小能够让我们控制序列的长度。这几种方式当然都有人想到过并有一些文章出来。不过要说革掉CNN的命,显然第4种方案更加的彻底。同时,仅用transformer还带来一个长远的好处,就是将cv和nlp领域的基本模型骨架统一了,这样也激发了很多对于多模态混合任务的创新。
ViT的做法
ViT就是其中比较知名的作品,它是一个图像分类的模型,自然仍然是有监督学习的方式。
ViT可以说是充分利用了前人的工作(这么说并不有损其工作的重要性),其基础的思路已经有人提出过。包括在实现上,在ViT提出的时间点,模型底层也有很多很高效的实现,也免去了很多魔改模型、需要自己实现高效算子的麻烦。
ViT实现中尽量保持了原始的transformer编码器结构,只在少数地方(比如位置编码的部分)进行了改动。所以熟悉transformer的看到下面的模型结构图,可能就理解大体在做什么了。
论文:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
原文代码:https://github.com/google-research/vision_transformer
推荐观看:ViT论文逐段精读【论文精读】
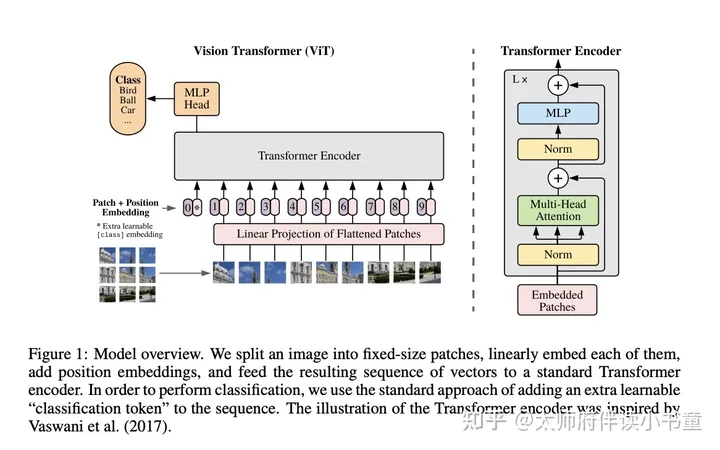
模型结构大体流程如下:
1、先将图片切成一个个的小块(patch)
2、将每个patch拉平后经过投影层获得embedding
3、在embedding的基础上添加位置编码信息,从1开始编号
4、添加一个初始的空patch,位置编号为0,用于对接预测输出
5、进过标准的transformer encoder
6、将0号位置的patch输出接上一个mlp进行分类:
由于transformer中的元素是两两交互的,所以0这个元素能够“看到”后面图片所有元素,所以能提取到整张图的信息。
7、输出分类结果,计算损失作者为了尽量采用原始的transformer结构,更多只是在transformer block的前后多了一些适配工作。作者们最想证明的就是,即便不用针对cv领域做魔改,transformer本身就能够很好的应用在cv领域。
在其中多了不少对比实验,比


















暂无评论内容