
扩散模型在生成任务上非常成功,自然就想到将其扩展到其他任务上,果然香港大学的罗平团队就出了这个DiffusionDet。后续是不是可以将其扩展到各种任务上。Denoising Diffusion is all you need!
DiffusionSeg,DiffusionDet3D,DiffusionBEV,DiffusionMAE, DiffusionXXX,…, 论文名字已经帮大家起好了,看谁手速快,先到先得。
题目:DiffusionDet: Diffusion Model for Object Detection
作者团队:香港大学和腾讯 Shoufa Chen,Peize Sun,Yibing Song,Ping Luo
文章链接:https://arxiv.org/abs/2211.09788
代码链接:https://github.com/ShoufaChen/DiffusionDet
摘要:
我们提出的DiffusionDet是一个新的目标检测框架,它将目标检测建模为从噪声框(noisy boxes)到目标框(object boxes)的去噪扩散过程。在训练阶段,目标框从真值框(ground-truth boxes)扩散到随机分布,模型学习如何逆转这种向真值标注框添加噪声过程。在推理阶段,模型以渐进的方式将一组随机生成的目标框细化为输出结果。在标准基准(包括MS-COCO和LVIS)的广泛实验表明,与之前成熟的目标检测器相比,DiffusionDet具有良好的性能。我们的工作给出了目标检测方面的两个重要发现:1 随机框(random boxes)虽然与预定义的anchors或learned queries有很大不同,但也是有效的目标候选。2目标检测是代表性的感知任务之一,可以通过生成的方式来解决。
Introduction:
目标检测旨在预测一幅图像中目标对象的一组边界框和相关类别标签。作为一项基本的视觉识别任务,它已成为许多相关识别场景的基础,例如实例分割、姿势估计、动作识别、目标跟踪和视觉关系检测。
目标检测方法随着对象候选的发展而不断发展,即从经验目标先验到可学习对象查询。具体而言,大多数检测器通过定义基于经验设计的对象候选的回归和分类来解决检测任务,例如滑动窗口、区域建议、锚框和参考点。最近,DETR提出了可学习的对象查询,以消除手工设计,并建立端到端的检测框架,开启了对基于查询的检测范式。
虽然这些方法简单有效,但它们仍然依赖于一组固定的可学习查询。很显然的一个问题是:是否有一种更简单的方法,不需要可学习查询的替代品?我们通过设计一个新的框架来回答这个问题,该框架可以从一组随机框中直接检测对象。
我们从纯随机框开始,这些随机框不包含需要在训练中优化的可学习参数,然后希望逐步细化这些框的位置和大小,直到它们完美覆盖目标对象。这种对目标框添加噪声的设计(noise-to-box)不需要启发式的目标先验,也不需要可学习的查询,从而进一步简化了对象候选,并推动了检测架构的发展。
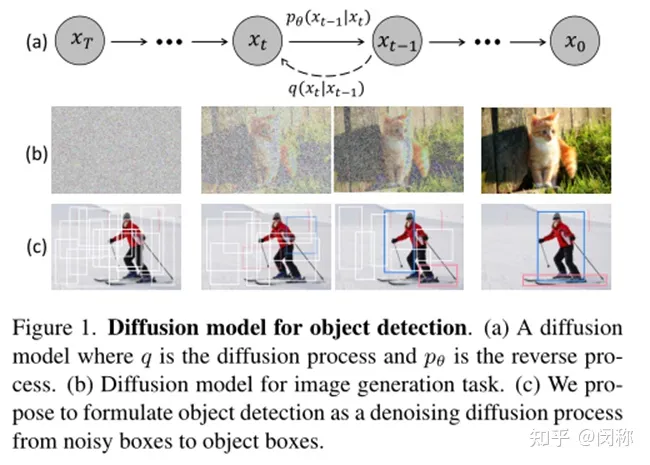
我们的动机如图1所示。我们认为noise-to-box的范式的原理类似于去噪扩散模型中的噪声到图像过程,这是一类基于似然的模型,通过去噪模型从图像中逐渐去除噪声来生成图像。扩散模型在许多生成任务中取得了



















暂无评论内容