
作者丨小源
来源丨数源AI
编辑丨极市平台

论文链接:https://arxiv.org/pdf/2401.03540.pdf
引言
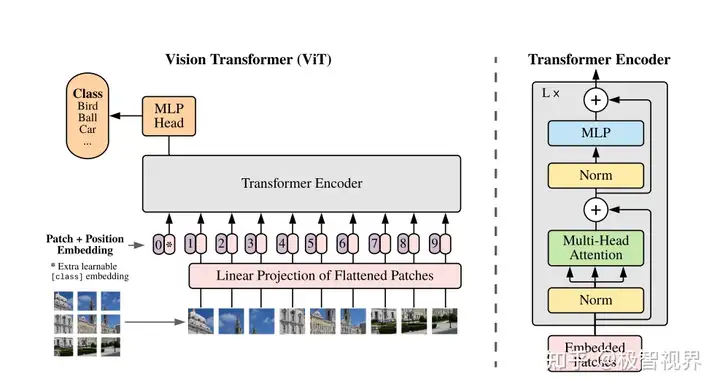
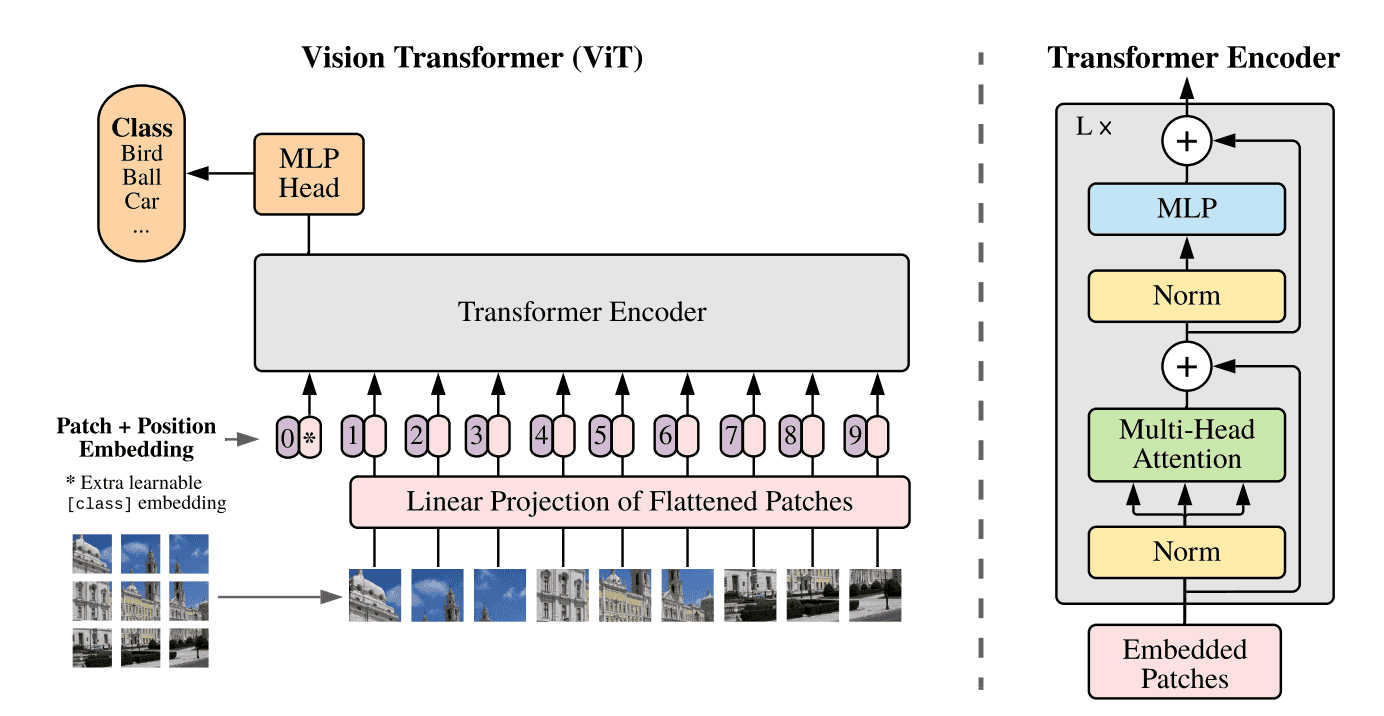
Transformer最初是用于自然语言处理(NLP)的技术,在视觉领域得到了显著的流行,这要归功于Vision Transformer(ViT)的开创性工作它的优势已经在各种视觉任务中得到了证明,包括图像分类、目标检测、分割等。对于捕获长距离依赖关系,点积自注意力(DPSA)与softmax归一化在transformer中起着至关重要的作用。然而,该模型的计算导致了二次时间和内存复杂度,使得训练长序列模型变得困难。
简介
本文提出了SeTformer,一种新的transformer,其中DPSA完全被Self-optimal Transport (SeT)取代,以实现更好的性能和计算效率。SeT基于两个基本的softmax属性:保持非负的注意力矩阵和使用非线性的重新加权机制来强调输入序列中重要的标记。通过引入一个用于最优传输的核成本函数,SeTformer有效地满足了这些属性。特别是,在小型和基准尺寸模型下,SeTformer在ImageNet-1K上实现了令人印象深刻的84.7%和86.2%的top-1准确率。在目标检测方面, SeTformer-base相比FocalNet同类产品超出2.2 mAP, 使用的参数和浮点运算数分别减少了38%和29%。在语义分割方面, 我们的基准模型相比NAT超出了3.5 mIoU,并且参数减少了33%。SeTformer在GLUE基准测试中也取得了最先进的语言建模结果。这些发现凸显了SeTformer在视觉和语言任务中的适用性。
方法与模型
我们的目标是开发一种强大而高效的自注意力模型,尤其注重简单性。我们不添加任何复杂模块,如卷积、平移窗口或注意力偏置,以提高视觉任务的性能。事实上,我们采用了不同的策略。SeT利用了softmax的重要性质,包括非负性和重新加权机制,同时在设计中也注重了效率。使用具有正定(PD)核的RKHS避免了聚合负相关信息。SeT通过OT引入了非线性的重新加权方案。这涉及在RKHS中计算输入和参考集之间的对齐得分。这个过程引入了对齐得分的非线性,给元素分配权重以突出它们的重要性。这有助于模型捕捉复杂关系并强调局部相关性。
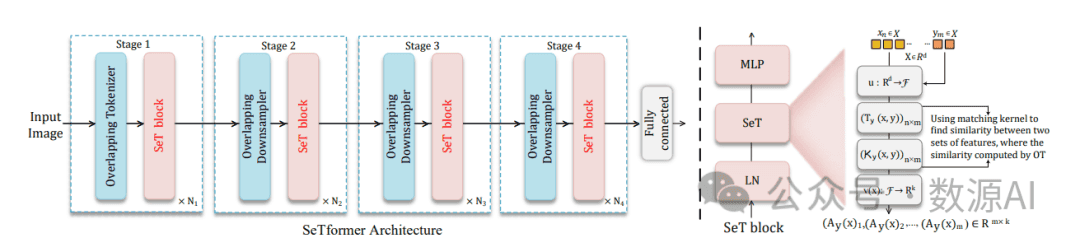
SeTformer 架构首先是一个下采样的卷积层,然后是包含多个 SeT 块的四个序列阶段。连续的阶段通过降采样层相连,降低空间尺寸同时加倍深度。在右边,我们展示了我们的注意力计算:将 x 和 y 元素映射到RKHS,然后通过 x 和 y 之间的 OT 计算聚合 x 特征,如果它们与相应的参考对齐良好。
我们使用Swin作为我们的基线模型,用我们的SeT模块替换其自注意力。我们的模型由四个阶段组成,每个阶段具有不同的空间分辨率,结果是输入图像的1/4大小。输入使用两层3×3卷积和2×2步幅进行嵌入。在每个阶段之后,除了最后一层外,都有一个通过3×3卷积和2×2步幅进行下采样的模块。这与Swin不同,Swin使用的是非重叠的2×2卷积。
1 Representing local image neighborhoods in an RKHS
为 了 保 持 线 性 计 算, 我 们 将 输 入 特 征 向 量 嵌 入到 一 个RKHS中, 其 中 点 评 估 采 用 线 性 函 数 的 形式。核方法使我们能够通过一个正定核函数K,将数据从其原始空间X映射到一个高维希尔伯特空间(特征空间)F中。对于函数u:X → F(特征映射),正定核函数表示为K(x, x′) = ⟨u(x), u(x′)⟩F。鉴于u(x)可以是无穷维的,核技术允 许 从Rk中 导 出 一 个 有 限 维 度 的 表 示v(x),其 中 内 积⟨v(xi), v(x′j)⟩表 示K(x, x′)。正 如所示,如果K是正定的,对于任意的x和x′,我们有K(x, x′) ≥ 0,这与softmax算子的非负性质一致。
2Optimal transport (OT)
我们模型中的一个基本作用是通过学习它们之间的映射将相关令牌进行聚合。我们的加权聚合依赖于被视为不同测度或加权点云的元素x和x′之间的输运计划。OT在对齐问题中得到了广泛应用,并且具有捕捉数据几何形状的出色能力。在本文中,我们专注于Kantorovich形式的OT ´ ,其中使用熵正则化来平滑输运计划
3Self-optimal Transport (SeT)
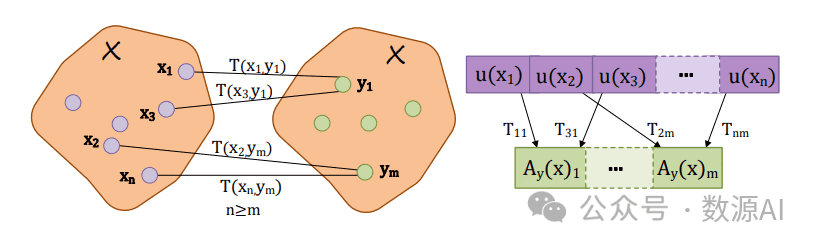
对 于 一 个 输 入 特 征 向 量x和 一 个 位 于X中 的 参考ym,我们进行以下步骤:(i)将特征向量x和y表示为RKHSF中 的 元 素, (ii)使 用OT将x的 元 素 与y对 齐,(iii)对x的元素进行加权聚合,得到一个对齐矩阵A。我们使用参考y来实现高效的元素聚合。参考集合中的每个元素都作为一个”对齐单元”,输入特征通过加权求和在这些单元中进行聚合。这些权重指示了输入和参考之间的对应关系,通过OT计算得出。假设我们有一个输入特征向量x = {x1, . . . , xn},其中x属于X ∈ Rd,是从输入图像中随机提取的。在Nystrom¨ 近似方法的背景下,y的样本是通过对训练集X中的特征向量进行K-means聚类来获得的质心,从而我们得到y = {y1, . . . , ym},其中m ≤ n。使用参考集合有助于优化计算过程,并使模型能够有效地处理更长的输入序列。设k是一个正定的核函数,如定义在RKHS上的高斯核函数,以及映射u : Rd → F。我们创建一个大小为n × m的矩阵k,用于存储比较k(xi, yj )的结果。接下来,我们根据公式(2)计算x和y之间的传输计划,得到大小为n × m的矩阵T(x, y)。传输计划找到将输入特征与参考元素对齐的最佳方法,同时最小化对齐成本。
4Projecting onto a linear subspace
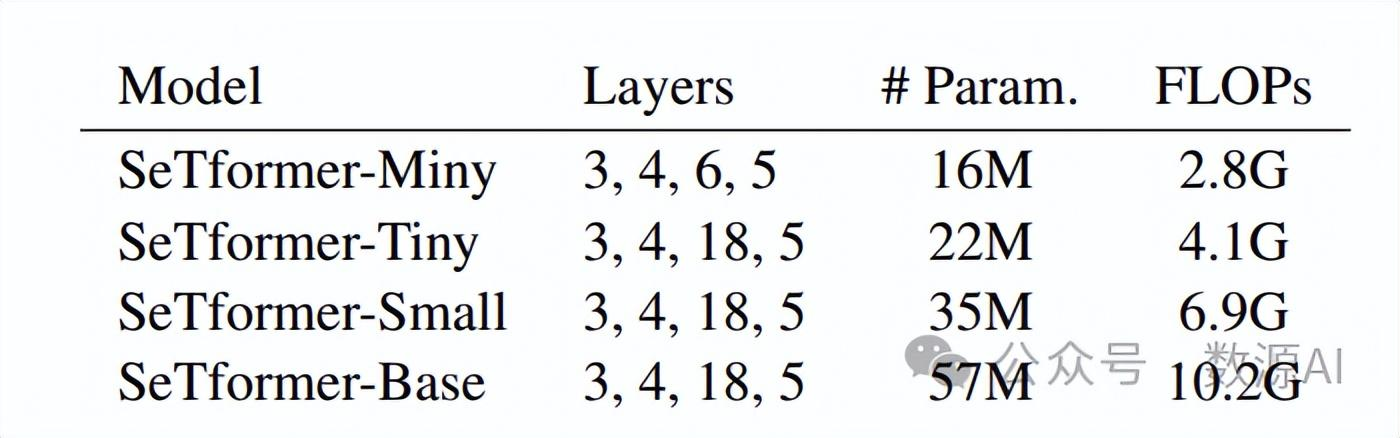
当处理有限维度的u(x)时, Ay(x)可 以 直 接 计 算, 而 不 会 引 起 重 大的计算开销。对于无限维或高维的u(x),Nystrom¨ 算法提 供了 一 种 有 效 的 近 似 方 法 来 嵌 入væRd → Rk。Nystrom¨ 算 法 通 过 对 列 和 行 进 行 采 样, 并 将 输 入从 特 征 空 间F投 影 到 线 性 子 空 间F1上 来 近 似 计 算传 输 计 划, 从 而 得 到 嵌 入⟨v(xi), v(x′j)⟩F1。子 空间F1由k个中心u(z1), . . . , u(zk)张成。显式公式v(xi) =k(z, z)−1/2k(z, xi)表示将z = z1, . . . , zk作为中心来进行新的嵌入。这种高效的方法只需要执行K-means聚类并计算逆平方根矩阵。
5Linear positional encoding
为了将位置信息融入我们的模型中,我们采用了的方法,在输入集和参考集之间的相似性上应用了指数惩罚,基于它们的位置距离。这涉及到对T(v(x), y)与一个距离矩阵M进行乘法运算,其中Mij = e(− 1τ2)(α−β)2,其中α = i/n,β = j/m,τ表示平滑参数。我们考虑了内容和位置信息的相似性权重与其他位置编码方法相比取得了优秀的性能。
实验与结果
我 们 在 图 像 和 语 言 领 域 进 行 了 实 验, 包括ImageNet、COCO和ADE20K,以及GLUE,以展示我们的模型的影响。我们对超参数进行了微调,例如参考数量(m),OT中的熵正则化ϵ,以及位置嵌入中的τ。我们观察到ϵ和τ在任务之间表现稳定,但对于值m的选
224×224分辨率ImageNet-1K的分类准确率
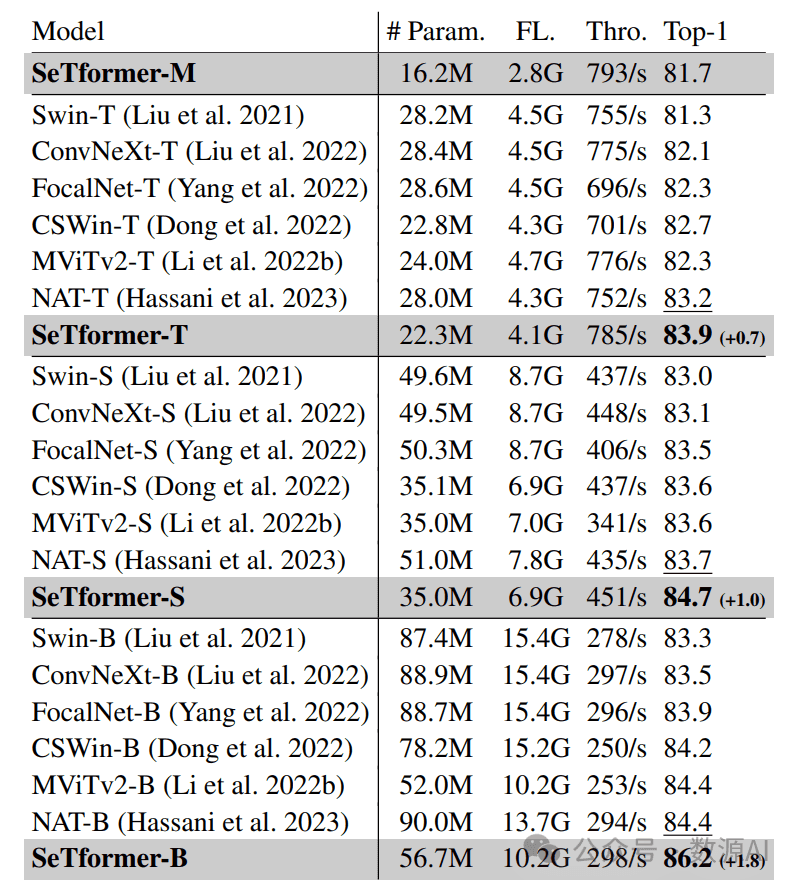
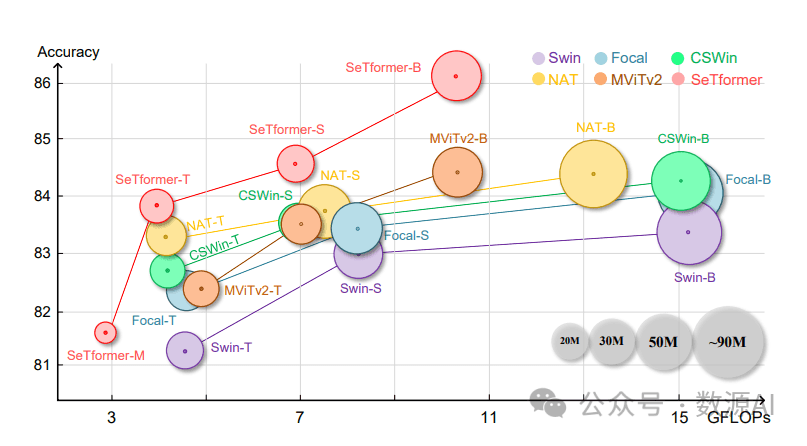
SeTformer模型以较小的模型大小、Flops和吞吐量稳定优于ConvNeXt。我们的Mini模型的准确率超过Swin-T模型0.4%,参数量减少40%(28M → 16M),Flops减少37%。我们的Tiny模型(83.9%)在性能上超过CSWin 1.2%,并具有类似的模型大小,速度提升12%(从701/s到785/s)。与FocalNet-T模型相比,它在性能上表现更优,提高了1.6%。使用更大的模型,我们在较少的参数和较低的计算成本下实现了最先进的性能。例如,SeTformer-B模型在超过24%和36%的Flops和参数减少的情况下,将NAT-B模型(84.4%)的准确率提高了1.8%。我们还注意到,吞吐量是在V100 GPU上测量的。
COCO数据集上Mask R-CNN目标检测结果
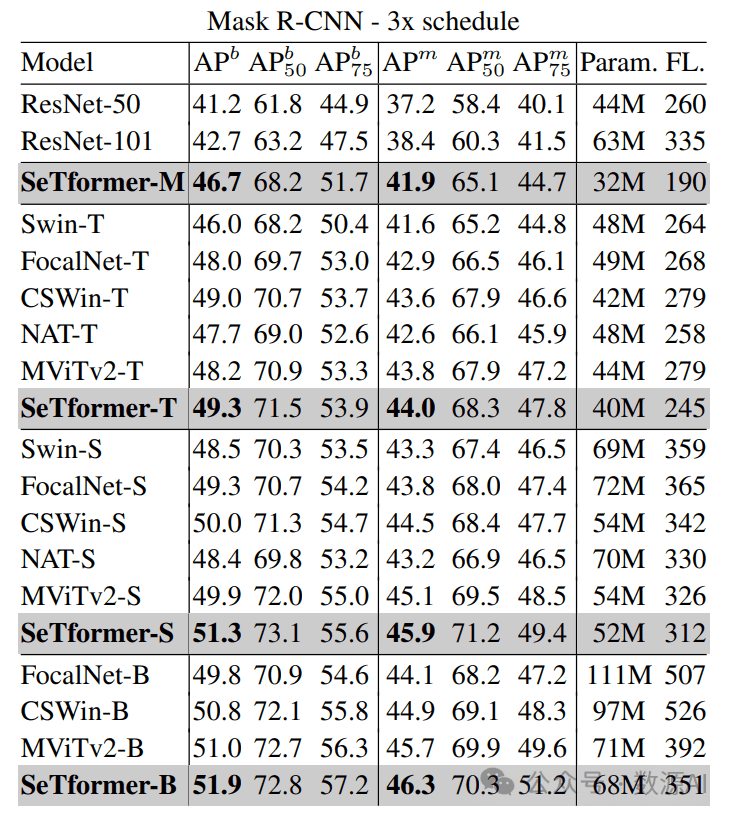
SeTformer在卷积神经网络(如ResNet)和Transformer骨 干 网 络 (如CSWin、 NAT、 MViTv2)方 面 表 现 优 异。例 如, SeTformer-T的APb为49.3,APm为44.0, 相 较 于NAT-T增 加 了1.6和1.4个 百 分 点,同时计算量更小, 模型尺寸更小。在扩展规模方面,SeTformer-B的APb为51.9,相比于CSWin-B的50.8,增加了1.1个百分点,同时参数减少28%,计算量减少33%。
ADE20K数据集上的语义分割结果
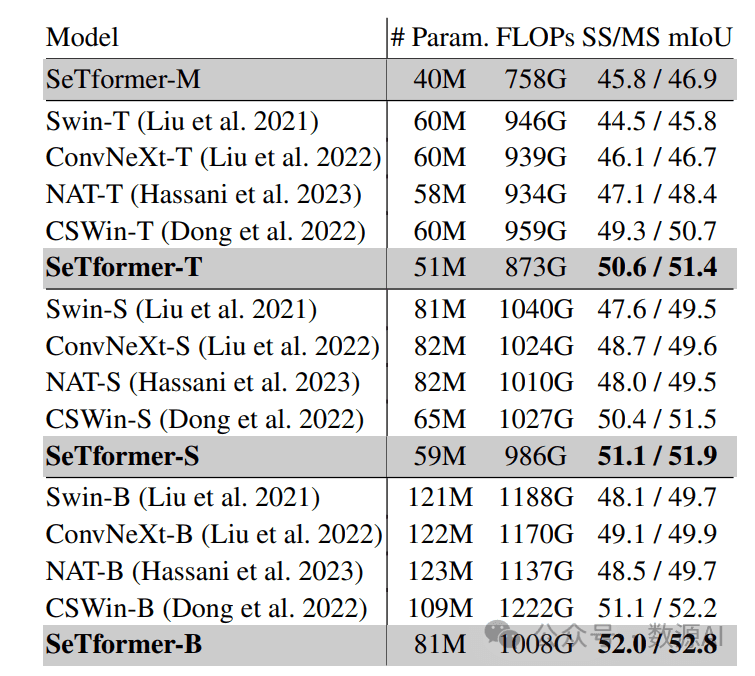
语义分割任务上我们的模型优于现有最先进的方法;例如,相比于CSWin的对应模型,SeTformer-T和SeTformer-S的mIoU(SS/MS)分别提高了+1.3 / +0.7和+0.7 / +0.4,同时具有更轻、更低复杂度的优势。

















暂无评论内容