
介绍
在Sora发布后,各路大佬纷纷猜测它的技术细节。例如:谢赛宁就认为Sora是基于他在ICCV 2023发布的DiT(Diffusion Transformer)技术(或思路)构建的。
添加图片注释,不超过 140 字(可选)
在Sora技术报告里面披露的技术内容包括:
将视觉数据转化为补丁(Turning visual data into patches)
研究人员受到大型语言模型的启发,它们通过在互联网规模的数据上进行训练而获得了通用能力。LLM范式的成功部分得益于优雅地统一了文本、代码、数学和各种自然语言等不同形式的令牌。在这项工作中,研究人员考虑了生成视觉数据模型如何继承这些优势。而LLMs具有文本令牌,Sora则具有视觉补丁。研究表明,补丁是模型视觉数据的一种有效表示。研究人员发现,补丁是用于训练生成模型的多种类型视频和图像的高度可扩展且有效的表示。

添加图片注释,不超过 140 字(可选)
在较高层面上,研究人员通过首先将视频压缩到低维潜空间,然后将表示分解为时空补丁来将视频转换为补丁。
视频压缩网络(Video compression network)
研究人员训练了一个降低视觉数据维度的网络。这个网络以原始视频为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并在此空间内生成视频。研究人员还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。
时空潜在补丁(Spacetime Latent Patches)(译者:应该翻译成“潜在”还是“潜空间”?)
给定一个压缩的输入视频,研究人员提取一系列时空补丁,这些补丁充当Transformer令牌。这种方案对图像也适用,因为图像只是具有单帧的视频。研究人员基于补丁的表示使得Sora能够训练各种分辨率、持续时间和长宽比的视频和图像。在推理时,研究人员可以通过将随机初始化的补丁排列成适当大小的网格来控制生成视频的大小。
扩展Transformers用于视频生成(Scaling transformers for video generation)
Sora是一个扩散模型;给定输入的噪声补丁(和文本提示等条件信息),它被训练来预测原始的“干净”补丁。重要的是,Sora是一个扩散Transformer(diffusiontransformer)。Transformers已经在各种领域展现出了显著的扩展性能,包括语言建模、计算机视觉和图像生成。

添加图片注释,不超过 140 字(可选)
因为在Sora的技术报告里面有这么一句“Importantly, Sora is a diffusiontransformer.”
而且在Reference里面有:
Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.”Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.↩︎
所以大佬的话是对的,的确使用了DiT技术。那么DiT技术到底是什么呢?
以下内容来自论文
论文链接:Scalable Diffusion Models with Transformers

添加图片注释,不超过 140 字(可选)
官网:Scalable Diffusion Models with Transformers

添加图片注释,不超过 140 字(可选)
随着人工智能技术的不断发展,图像生成领域正经历着一场深刻的变革。近年来,扩散模型在图像生成领域取得了令人瞩目的进展,其中尤以基于变分自编码器(VAE)的隐变量空间的扩散模型最为出色。本文将为您介绍一种全新的基于Transformer的扩散模型,它不仅能够实现媲美GAN的图像生成质量,而且具有更好的扩展性和计算效率。
添加图片注释,不超过 140 字(可选)
扩散(Diffusion)模型是一类基于深度学习的图像生成模型,它通过学习噪声图像到真实图像的逆过程,从而生成高质量的真实图像。传统的扩散模型通常采用卷积神经网络作为其主干网络,但本文提出了一种基于Transformer的新型扩散模型,即Diffusion Transformer(DiT)。
DiT(Diffusion Transformer)
基础概念:
Denoising Diffusion Probabilistic Models (DDPMs):通过逐步添加噪声来模拟数据分布,然后学习逆向过程去除噪声,以生成新的数据。DiT是DDPM在图像生成中的应用。
Latent Diffusion Models (LDMs):使用变分自编码器将图像压缩到低维表示,然后在低维空间中训练DDPM。这样可以降低计算成本,并使DiT成为基于Transformer的DDPM的适用框架。
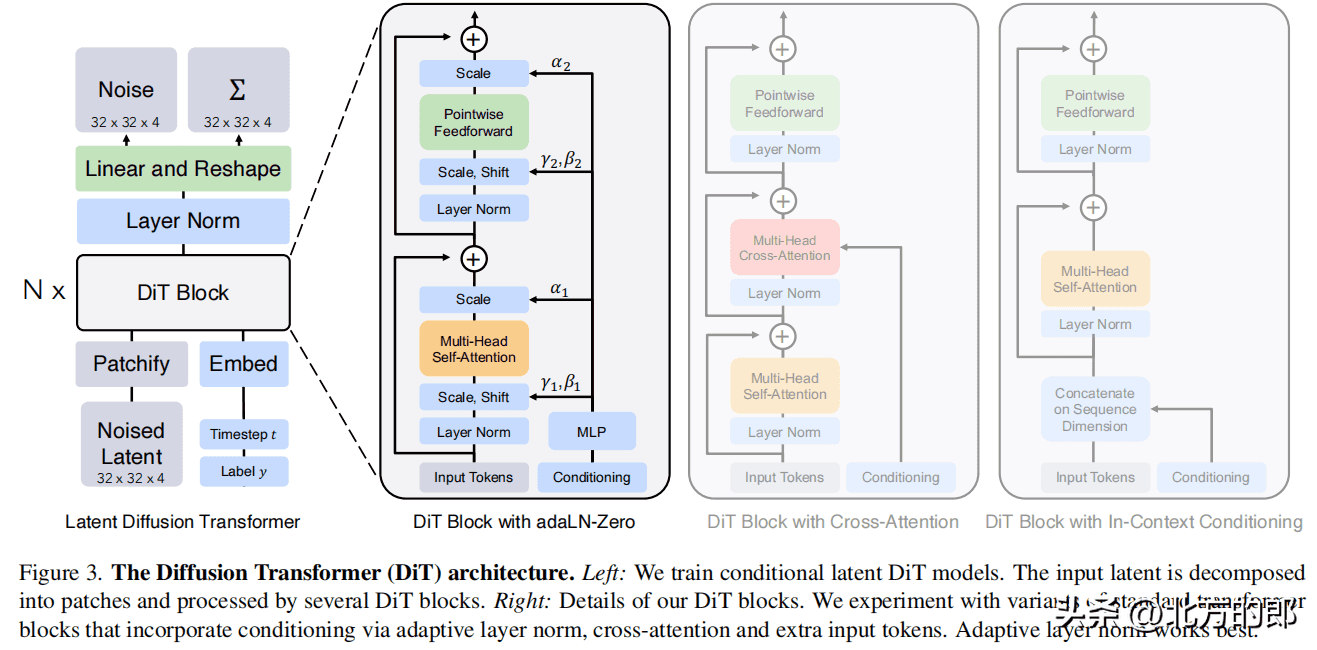
DiT的架构:
添加图片注释,不超过 140 字(可选)
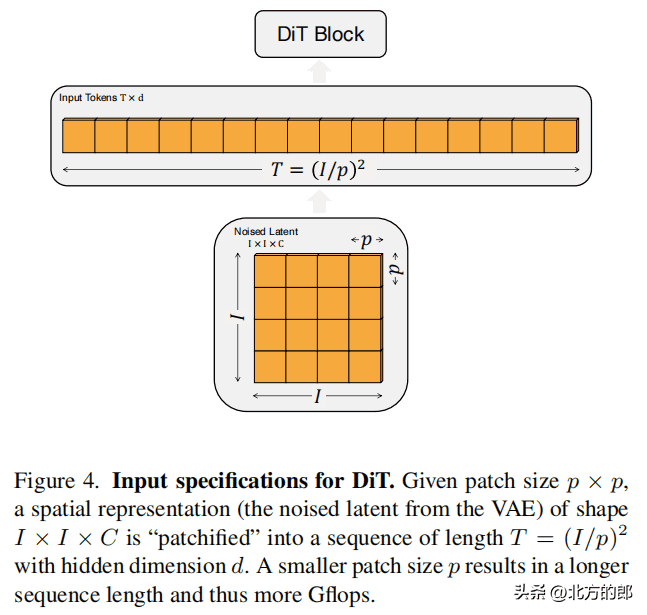
Patchify层:将图像切分成多个大小为p x p的patches,并转换为长度为T的序列作为Transformer的输入。具体来说,当图像大小为I x I x C时,Patchify层将图像切分成大小为p x p的patches,并将每个patch转换为长度为T的序列。序列长度T的计算公式为:T = (I/p)²。例如,当图像大小为32 x 32 x 4,patch大小为2时,T为1024;当patch大小为8时,T为16。
添加图片注释,不超过 140 字(可选)
DiT block:DiT block包含自注意力层、层规范层、前馈网络层。文档中提到了四种变体,分别为:
in-context conditioning:将噪声时间步和类别标签的嵌入向量作为额外的输入token,与图像token一起输入。cross-attention:将噪声时间步和类别标签的嵌入拼接为一个长度为2的序列,与图像序列分开,并在block中增加一个cross-attention层。adaptive layer norm (adaLN):使用自适应层规范层代替标准层规范层,并从噪声时间步和类别标签的嵌入向量中回归出尺度参数和偏置参数。adaLN-Zero:在adaLN的基础上,对每个block的最后一个层规范层进行初始化,使其初始为恒等函数。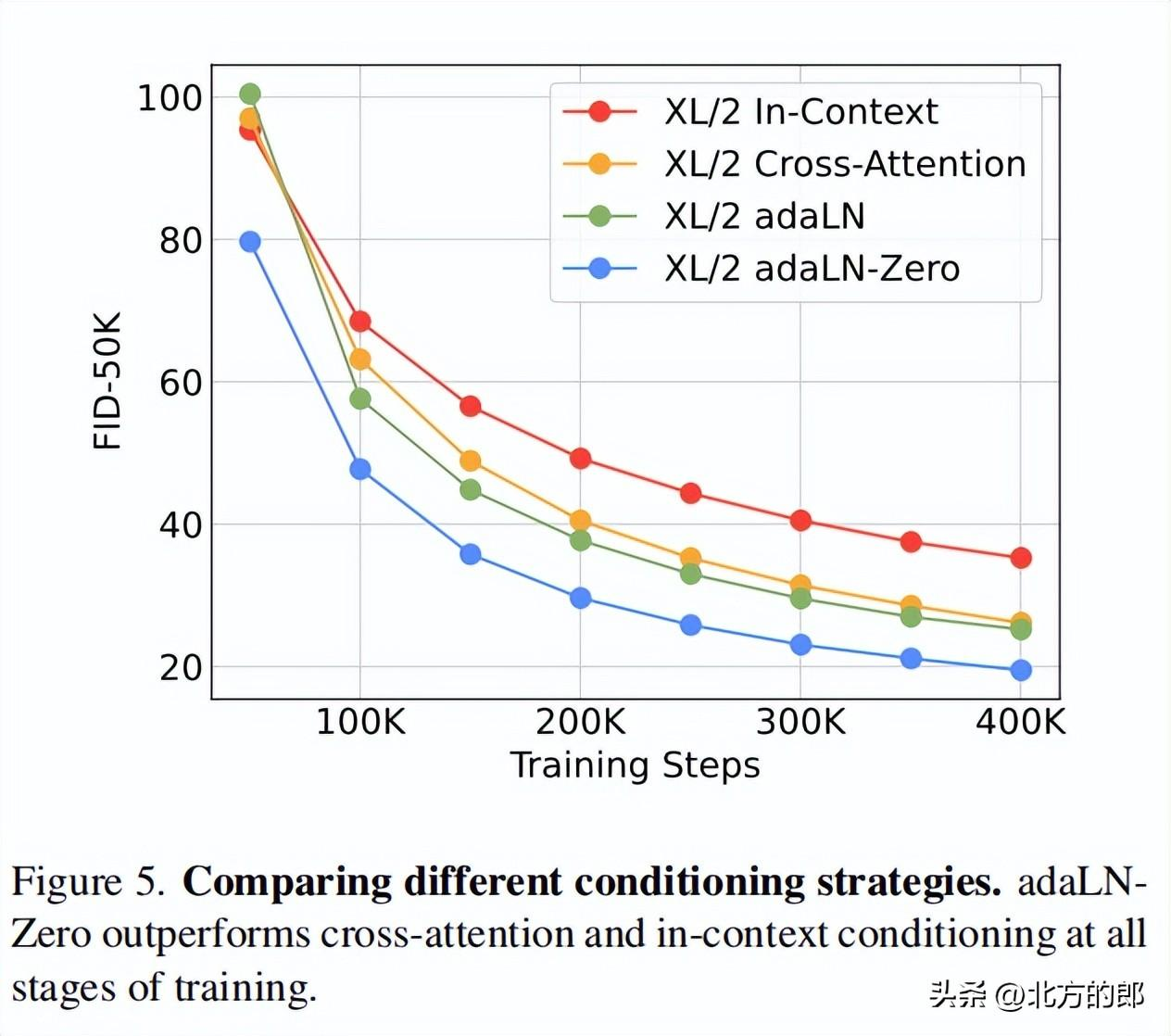
添加图片注释,不超过 140 字(可选)
最有效的是adaLN-Zero。
模型大小:
添加图片注释,不超过 140 字(可选)
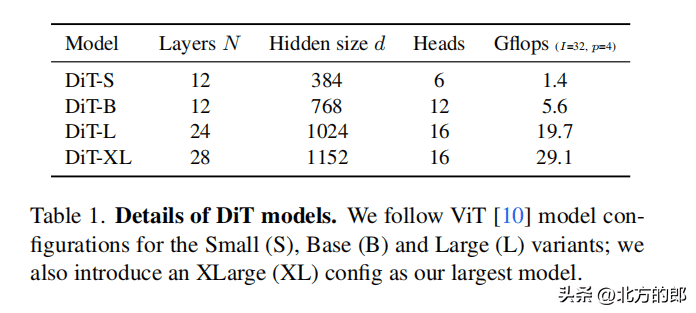
DiT有四种配置,分别为DiT-S、DiT-B、DiT-L和DiT-XL。
DiT-S包含12层,隐藏维度为384,6个注意力头,计算量为1.4 Gflops。DiT-B包含12层,隐藏维度为768,12个注意力头,计算量为5.6 Gflops。DiT-L包含24层,隐藏维度为1024,16个注意力头,计算量为19.7 Gflops。DiT-XL包含28层,隐藏维度为1152,16个注意力头,计算量为29.1 Gflops。实验设置
添加图片注释,不超过 140 字(可选)
训练:
在ImageNet数据集上训练类条件DiT模型,分辨率为256 x 256和512 x 512。使用AdamW优化器,学习率为1 x 10^-4,权重衰减为0,批量大小为256。数据增强仅使用水平翻转。训练过程中维护DiT权重的指数移动平均(EMA),衰减率为0.9999。扩散:
使用预训练的变分自编码器(VAE)将图像编码为低维表示。在VAE的潜在空间中训练DiT模型。使用ADM的扩散超参数。评估指标:
使用Fréchet Inception Distance (FID)评估模型性能。使用Inception Score、sFID和Precision/Recall作为辅助指标。计算资源:
使用JAX实现所有模型,并在TPU v3 pods上进行训练。实验结果
添加图片注释,不超过 140 字(可选)
DiT block设计:
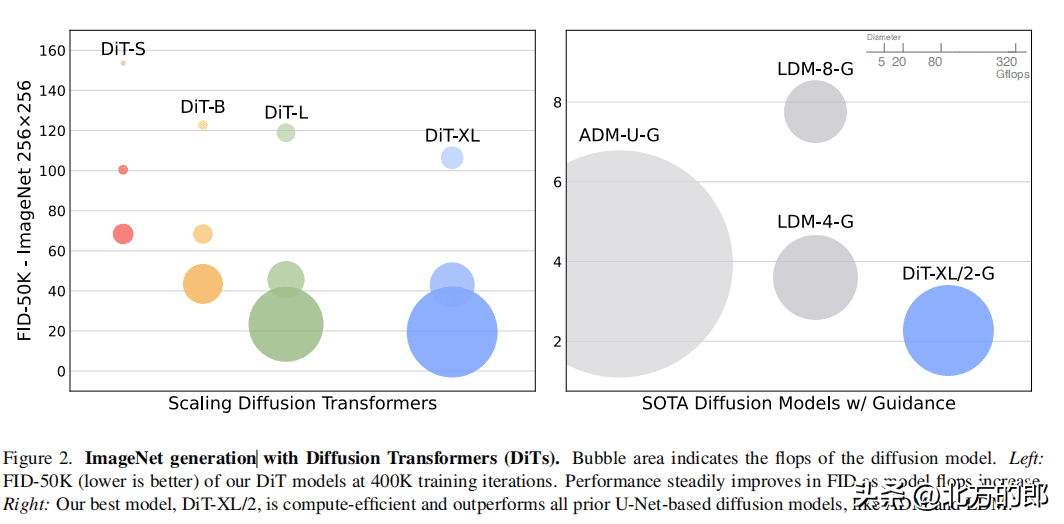
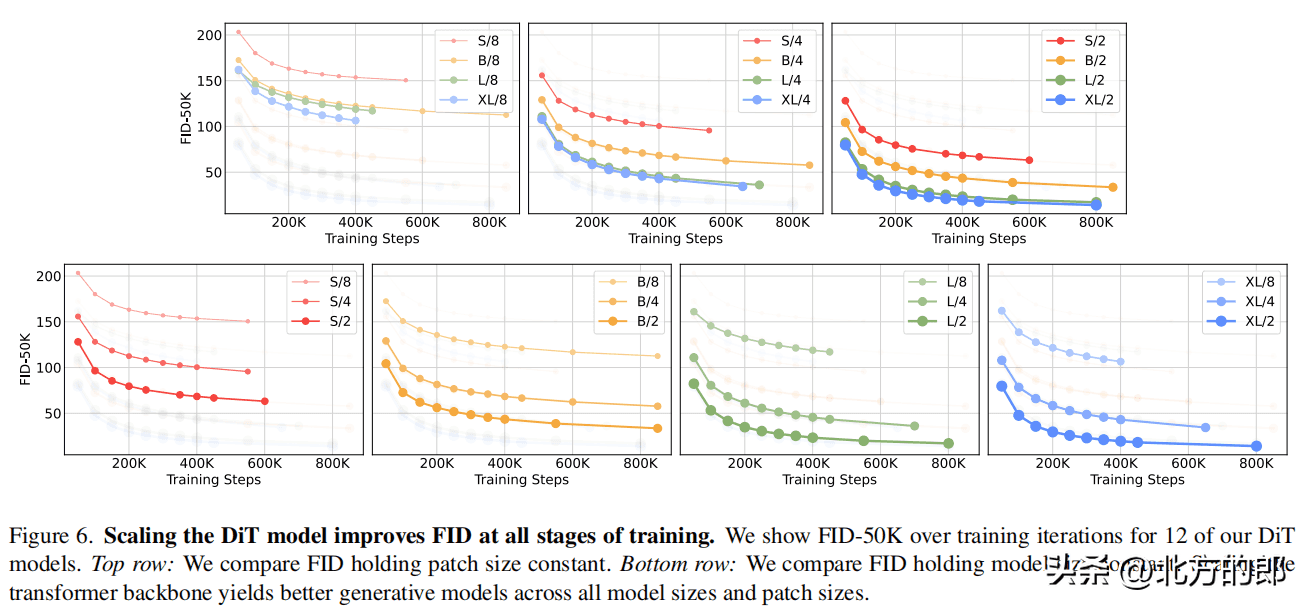
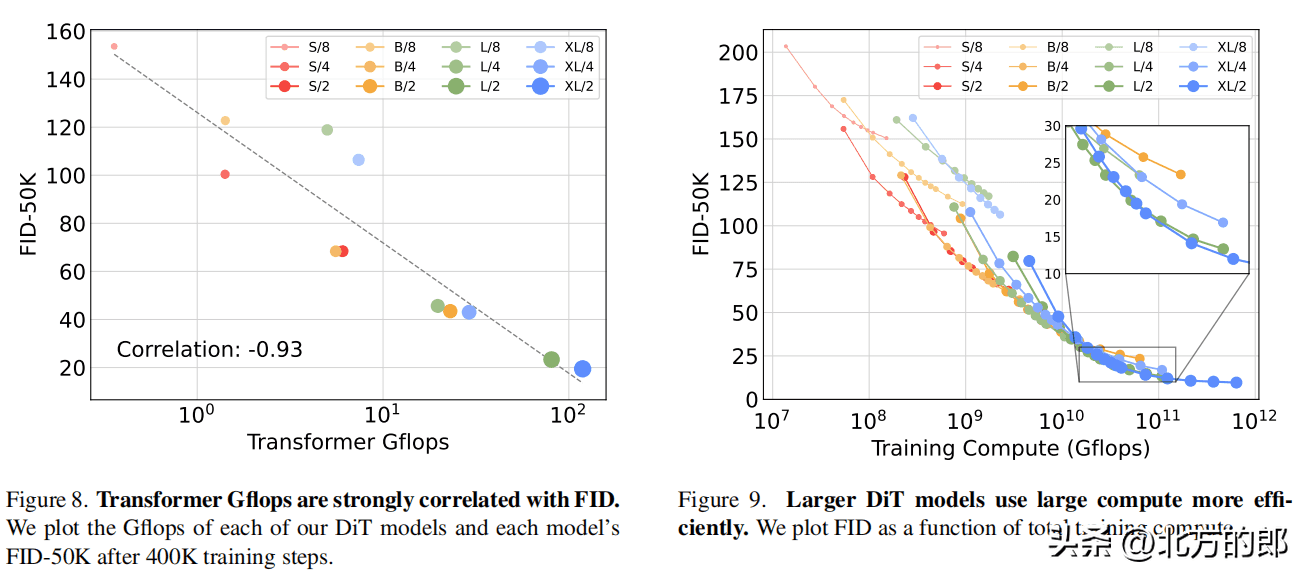
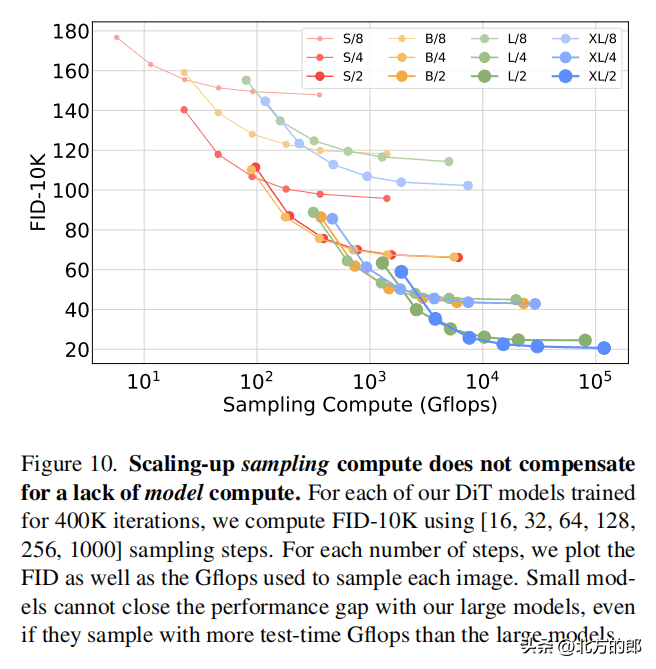
在相同计算量下,adaLN-Zero block的FID明显低于其他三种block设计,性能最优。模型大小和patch size:增加模型大小和减小patch size都可以显著提升DiT的性能。模型计算量(Gflops)与FID负相关,与参数数量相比,模型计算量是影响性能的关键。计算效率:
大模型在使用更多计算资源时能获得更好的性能提升,小模型即使使用更多计算资源也难以赶上大模型。256×256分辨率:DiT-XL/2获得state-of-the-art的FID 2.27,优于LDM的3.60。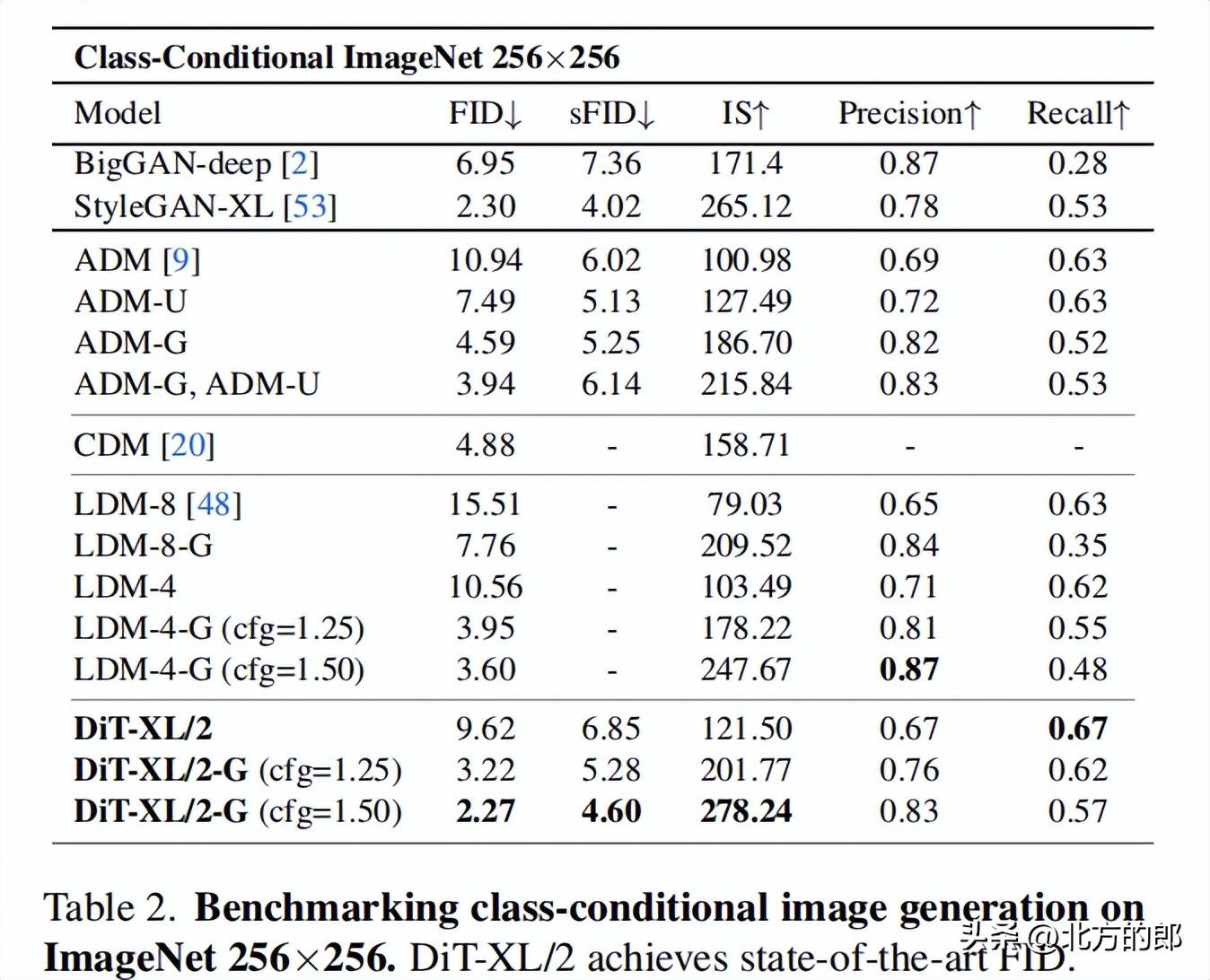
添加图片注释,不超过 140 字(可选)
512×512分辨率:DiT-XL/2同样获得state-of-the-art的FID 3.04,优于ADM的3.85。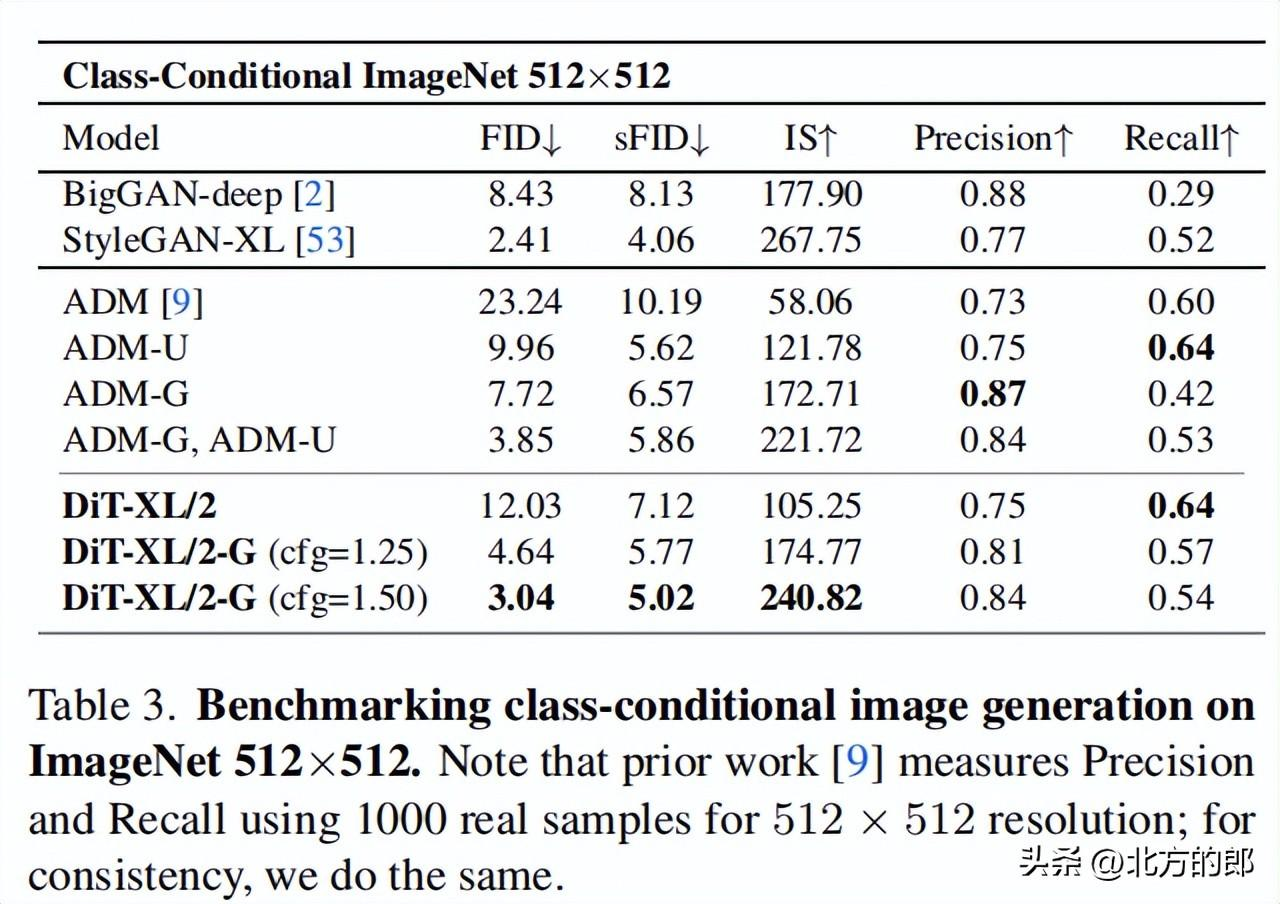
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
DiT的出现为图像生成领域带来了新的思路和可能性。它不仅展现出媲美GAN的生成质量,而且还具有更好的扩展性和计算效率。对比Sora与其他视频生成模型,感觉DiT的确是它效果胜出的一个原因。



















暂无评论内容