
图片来源@视觉中国
文 | 追问nextquestion
自ChatGPT问世以来,“Transformer模型”始终以超高频率出现在各个AI新产品模块当中。比如,大家所熟知的GPT-4、Midjourney、GitHub Copilot等,它们的优越性能都得益于Transformer的诞生。
Transformer最早于2017年由谷歌(Google)研究团队提出,主要用于处理自然语言。与传统的深度学习方法相比,Transformer采用了一种被称为自注意力机制(Self-Attention)的方法,在捕捉长距离依赖关系层面具有独特优势。近些年来,Transformer已在文本内容解析、目标检测、视觉分割等领域表现出色。
▷
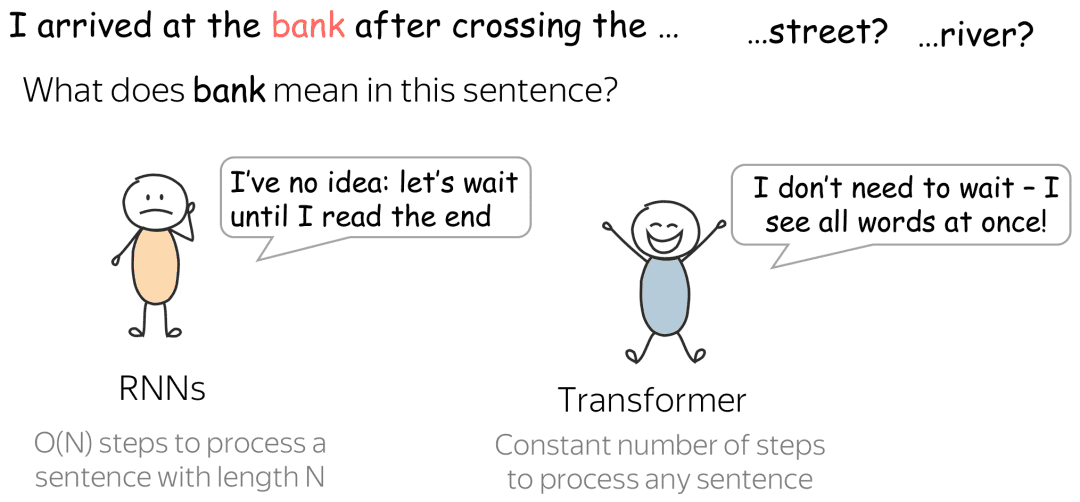
图1:Transformer与循环神经网络(RNNs)比较。图片来源:
https://lena-voita.github.io/resources/lectures/seq2seq/transformer/rnn_vs_transformer_river-min.png反观大脑,它是生物最复杂和神秘的器官。对大脑结构和功能机制研究的脑科学被誉为人类探索自然科学的“终极疆域”。那么,如果将Transformer应用到脑科学的前沿研究中,“强强联合”,两者会碰撞出怎样的火花?
最近,来自北京科技大学的陈诚博士和北京天坛医院的赵继宗院士团队就在一篇综述中全面介绍了Transformer在脑科学领域最具代表性的研究工作,涉及脑疾病诊断,脑年龄预测,脑异常检测等八个应用领域,涵盖了数据、模型、性能指标等内容。该文目前已发表在Brain-X上,题为Understanding the Brain with Attention: A Survey of Transformers in Brain Sciences。
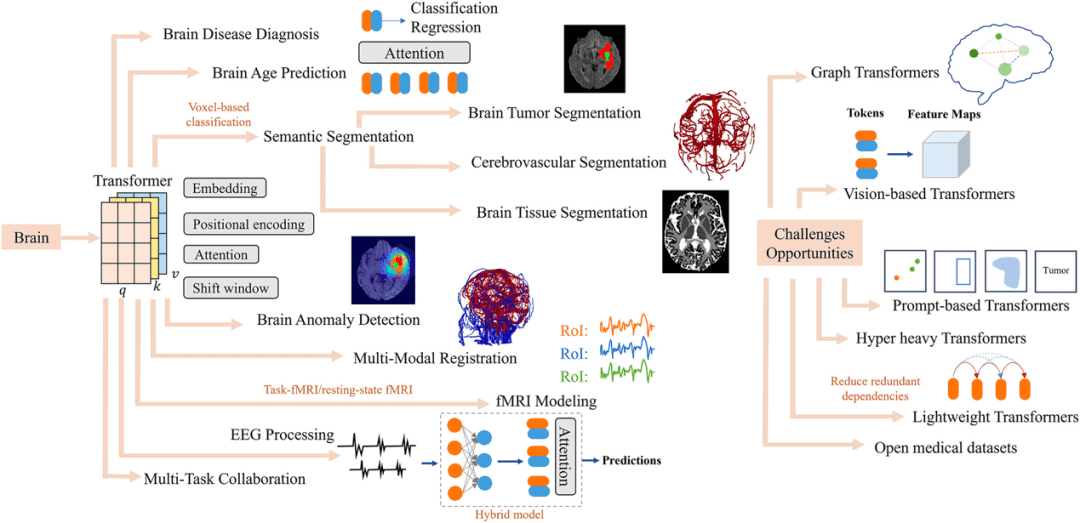
▷图2:Transformer模型在脑科学研究中的应用图谱。图源:参考文献[1]
从经典架构了解Transformer
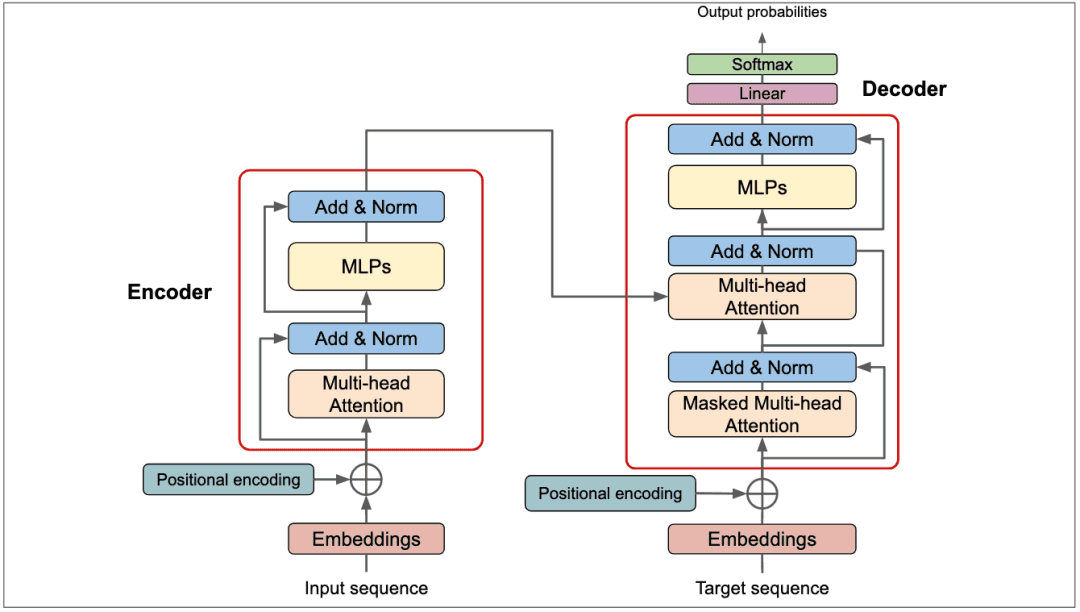
▷
图3:Transformer核心架构。图片来源:
https://deeprevision.github.io/posts/001-transformer/(一)输入嵌入
俗话说,入乡随俗。计算机模型不能直接理解人类语言,那么此时就需要输入嵌入(Input embedding)这个环节来做个衔接,也就是将输入数据转换为模型更好理解和处理的向量表示。按照输入数据的形式,目前主要可以分为词嵌入和图像嵌入,这篇论文中所指的即为词嵌入。而对于图像这种高维数据,在输入Transformer前,需要首先对其进行分割和压平,即图像嵌入。就像牛排太大生吞无味,切成小块细嚼慢咽才是硬道理。这里图像嵌入比较常用的处理方法,就是块嵌入(Patch embedding)。
(二)位置编码
“我爱过他”和“他爱过我”这两句话,虽包含的词语完全一致,但语序有别。假如放到自然语言的语境中,可能是两段完全不同的苦情往事。由此可见,词语的顺序在句义当中尤为重要。然而,Transformer的自注意力机制本身并不能感知词语的顺序信息。这时,Transformer就需要引入一种称为位置编码( Positional Encoding)的环节。位置编码就是在输入序列中的每个词语后面追加一个位置标记来表征它在句子中的位置信息。
(三)自注意力机制
千呼万唤始出来,自注意力机制在前文已被多次提及。那么,Transformer最引以为傲的自注意力机制是什么?
自注意力机制(Self-Attention Mechanism)是注意力机制的一个特例。注意力机制类似于人类的注意力,能够根据任务的需要分配不同权重给输入序列中的不同部分。自注意力机制则更像是一种“全知”的能力,系统可以同时关注输入序列中的所有位置,而不受序列中位置的限制。
自注意力机制的公式如下图所示。相比于传统模型,自注意力机制具有理论上的无限窗口和计算空间,使其能够更有效地捕捉输入序列的长距离依赖关系。注意力模块通过创建查询(Q)、键(K)和值(V)向量,并进行点积运算生成得分矩阵,再经过缩放和softmax激活处理,最终使用注意力权重对查询向量进行加权,生成增强的输出向量。这一过程使得模型能够从全局的角度理解并处理输入序列中单词之间的关联。
▷图4:自注意力机制的公式。
(四)多头注意力和掩蔽多头注意力
多头注意力机制(Multi-Head Attention)是注意力机制的一种扩展形式。多头注意力允许模型使用多组查询(Q)、键(K)、值(V),每个注意力头都有自己的一组参数,独立学习如何关注输入序列。这使得模型能够同时关注序列中的多个方面,从而更好地捕捉不同位置和语义之间的关系。最后,各个头的输出会被合并,形成最终的多头注意力输出。
由于Transformer可以一下子掌握所有的信息,在某些情况下,为了避免模型看到未来的信息,通常有必要将序列中未来的位置的信息设为不可见。掩蔽多头注意力机制(Masked Multi-head Attention)就是在训练任务中,我们只能使用当前位置之前的信息,而不能使用当前位置及之后的信息,以避免信息泄漏。
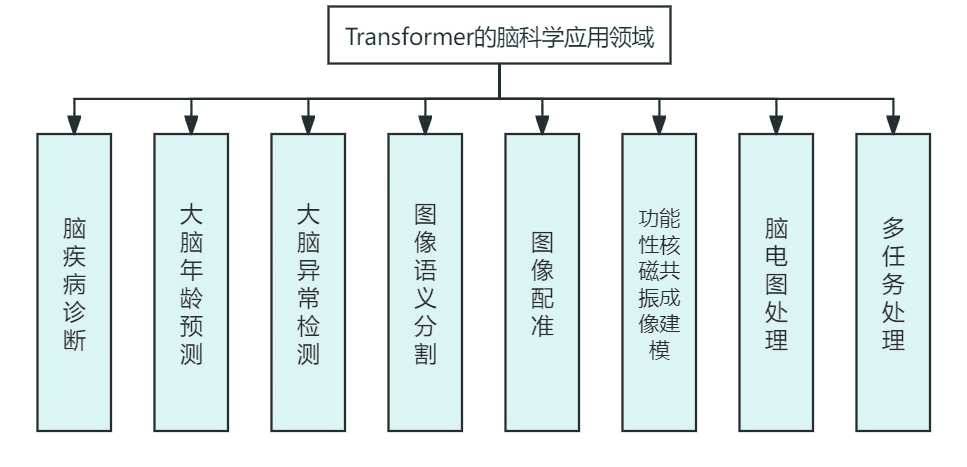
▷图5:Transformer在脑科学中的应用领域。图源:由追问编辑部制作
“Transformer+脑科学”的八大应用
(一)脑疾病诊断
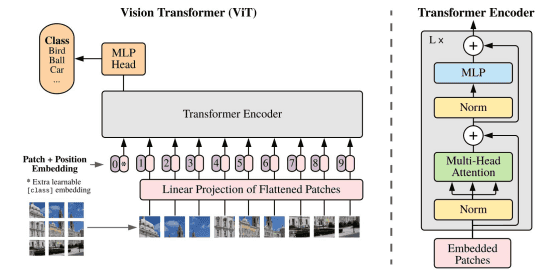
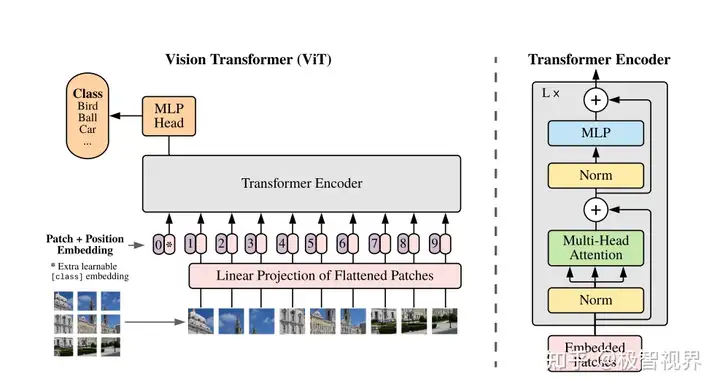
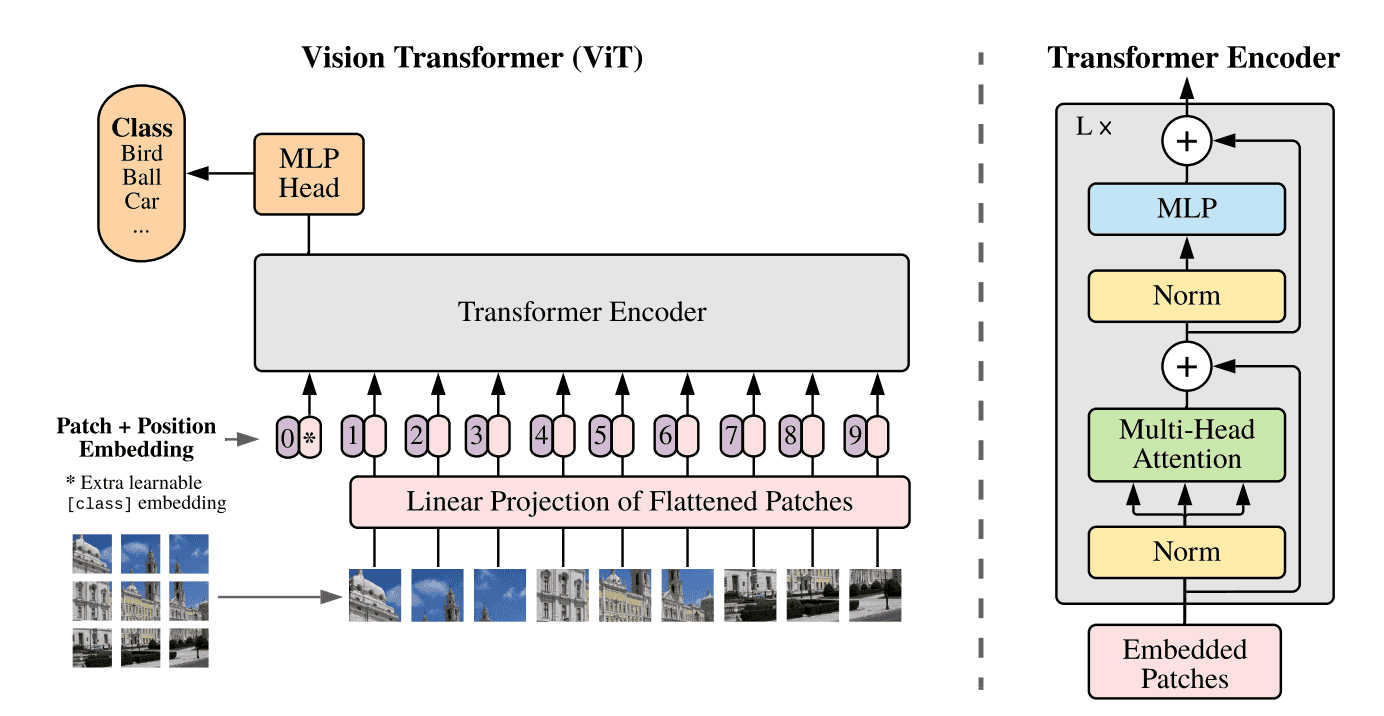
磁共振成像(MRI)*是一种在临床上常用的成像技术,通过对磁共振图像信息进行分析,医生能够发现和诊断脑疾病。Transformer,特别是在计算机视觉中首次引入的Vision Transformer(ViT)图像分类模型,目前已被成功应用于建立复杂的映射关系,如在磁共振图像与脑疾病之间建立关联。自2020年ViT的提出以来,越来越多的研究基于这一框架,致力于肿瘤和阿尔茨海默病等脑疾病的诊断。表格1归纳了以往研究中具有代表性的用于脑疾病诊断的Transformer模型信息。
*磁共振成像(MRI):是一种非侵入性的医学成像技术,通过利用磁场和无害的无线电波来生成详细的内部器官图像,特别适用于脑部结构和异常的检测。与一些其他成像技术(如CT扫描)相比,MRI避免了辐射暴露的风险,同时提供了更为详细的解剖学信息。此外,由于不涉及使用放射性物质,不引起过敏反应的风险,MRI成为了许多神经学和神经科学领域中首选的成像方法。通常具有T1,T1-CE,T2以及磁共振成像液体衰减反转(FLAIR)四种模态。
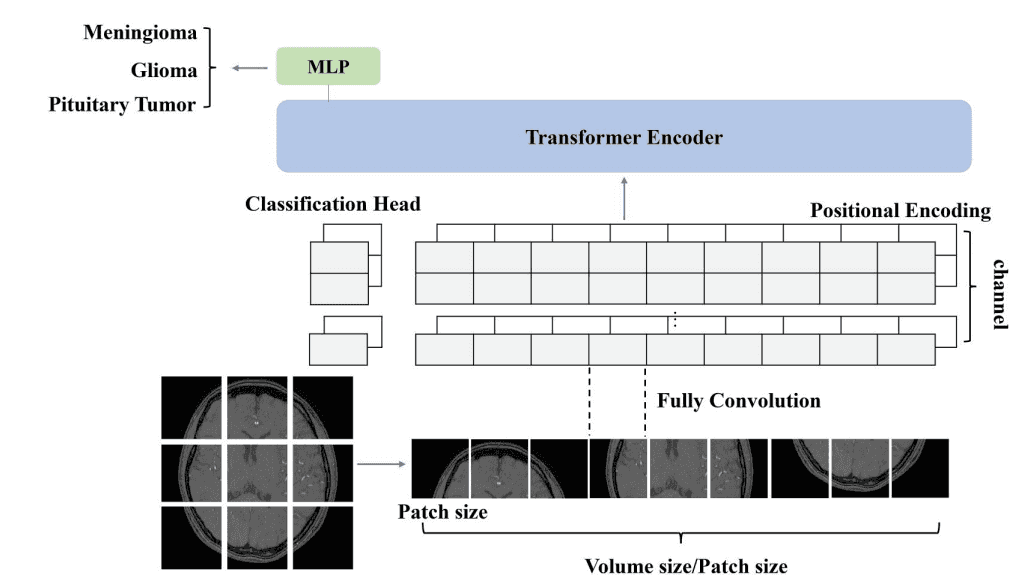
▷图7:ViT计算框架。图源:参考文献[1]
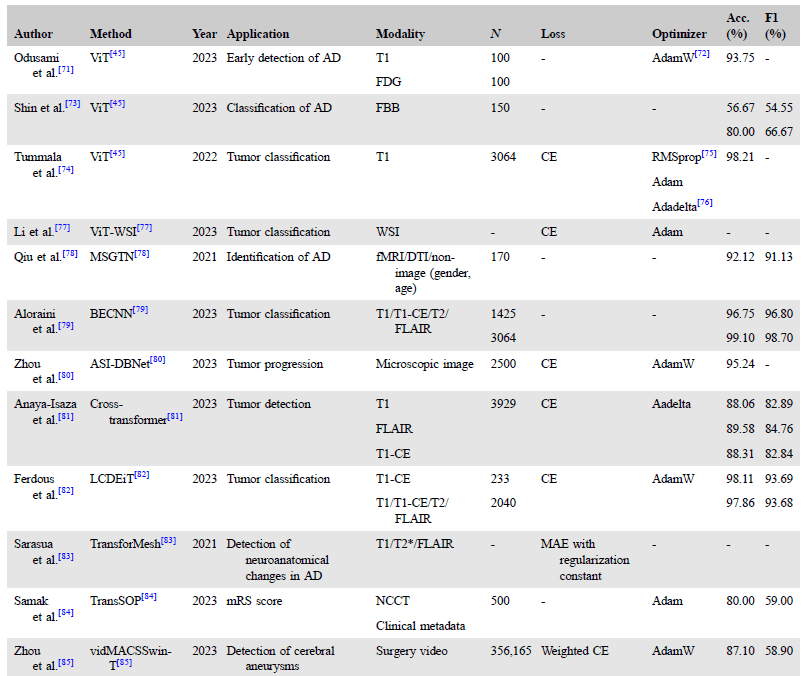
▷表格1:用于脑疾病诊断的Transformers的技术细节。图源:参考文献[1]
(二)大脑年龄预测
大脑年龄是指对一个人脑部结构和功能相较于其实际年龄状态的评估。通过使用一些神经学和认知学方法,如脑部成像、认知测试和神经生物学标志物,可以估算大脑年龄。估算大脑年龄对于研究认知功能的衰退、神经退行性疾病和其他与年龄相关的神经学问题至关重要。近年来,Transformer已成功应用于大脑结构和年龄之间的建模,为更好理解的大脑健康和老化过程以及开发相关疾病的预防和治疗方法提供了新途径。表格2中总结了大脑年龄预测方法主要的技术细节。
▷表格 2:用于推断大脑年龄的Transformers的技术细节。图源:参考文献[1]
(三)大脑异常检测
大脑异常检测是一类旨在快速且准确地定位脑部病变区域的任务。目前用于大脑异常检测的Transformer模型主要分为基于边界框的模型和重构模型。
1.基于边界框的模型(The bounding box-based model):这类模型使用边界框描述异常对象的空间位置。代表性的方法是VD-Former。VD-Former通过模拟对比度和空间一致性,准确定位了大脑中损伤的区域。
2.重构模型(The reconstruction model):通过预训练模型生成脑特征,将这些特征转移到学习正常样本的表示,从而实现对未知病理区域的异常检测*。一个代表性的模型是基于U-Transformer的异常检测模型(UTRAD)。UTRAD选择在特征分布中学习重建特征,相较于原始图像,这个过程模型获取了更多的特征,从而得以实现对异常区域的识别。
*异常检测与疾病诊断在中文语义上容易混淆。疾病诊断更倾向于是一个分类的任务,区分健康组和疾病组。而异常检测则更倾向于在图像上确定病变的存在,并定位其大致的边界。
(四)图像语义分割
图像语义分割是对目标区域进行像素级分类的过程。该任务要求模型对图像中的每个像素进行标签预测。与目标检测不同,像素级分类关注的是图像的细粒度信息,即对每个像素进行标注,以便了解图像中的每个区域属于哪个类别。传统的卷积神经网络(CNNs)能够建模局部特征,但在建模全局特征方面,Transformer则更为擅长。对于像语义分割这样的复杂任务,全局特征建模尤为重要。
脑部成像的语义分割涵盖了脑肿瘤分割、脑血管分割和脑组织分割等方面。在医学图像分析中,准确描述和分类这些结构,对于精确的疾病诊断和治疗至关重要。总的来说,通过引入Transformer,特别是在处理全局信息和复杂分割任务方面,脑部成像的语义分割有望取得更为准确和精细的结果,从而提高医学影像分析的水平。表格3列举了目前用于肿瘤区域分割的Transformer的技术细节,供读者参考。
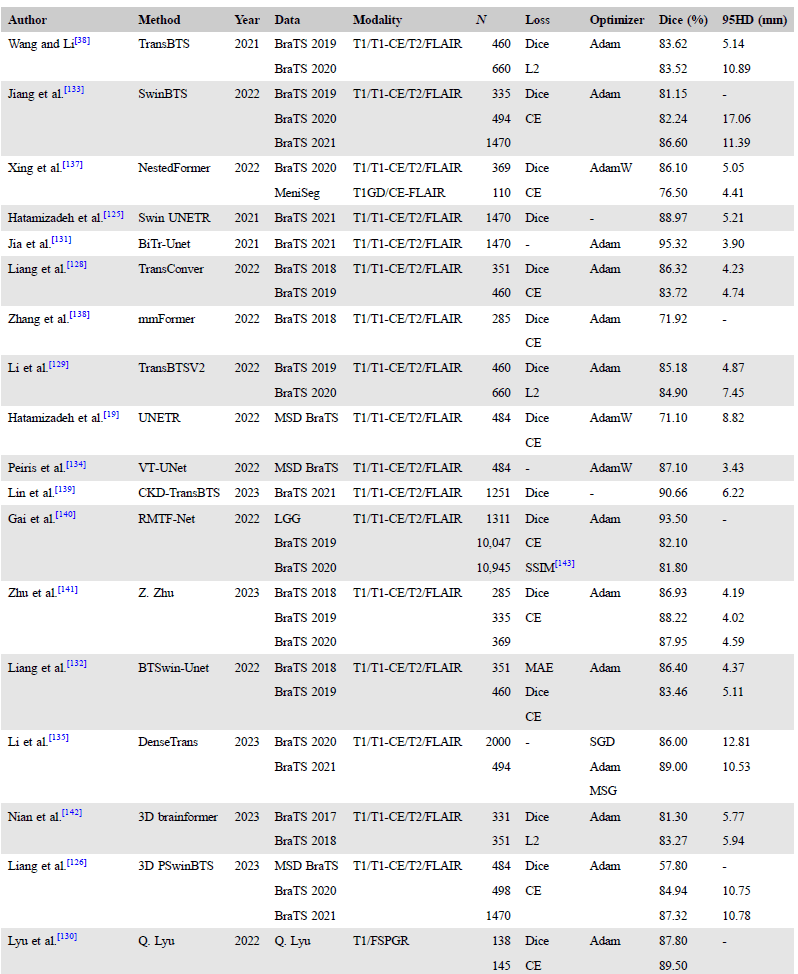
▷表格3:用于肿瘤区域分割的Transformers的技术细节。图源:参考文献[1]
(五)图像配准
图像配准是一种将两幅或多幅图像对齐的过程,以保持它们在空间或特定方面的一致性。在医学影像领域,图像配准是一项关键技术,用于整合或比较不同时间、传感器或模态下获得的图像。传统的图像配准依赖于特征检测和匹配,而基于深度学习的配准,则通过模型学习构建全局函数来获得对齐表示。研究表明,Transformer在图像配准中表现出色,特别是在长距离空间对应关系的建模方面。目前对于图像配准的研究主要分为位移场配准和微分同胚配准方法。
1.位移场配准(displacement field registration):它的目标是找到两幅或多幅图像之间的空间变换关系,以便将它们对齐。例如,研究人员使用Swin Transformer构建了仿射变换网络(TransMorph),实现了高效的图像变换。该模型利用混合的Transformer-ConvNet架构建立了远距离空间对应关系,生成将移动图像与固定图像对齐的变换参数。
2.微分同胚图像配准(diffeomorphic registration):这是一种保持图像局部形状和结构连续性的方法,通过优化微分同胚变换以对准图像,通常在流形空间和变分框架下实现。例如, 基于Swin Transformer的Swin-VoxelMorph模型,通过最小化图像差异并估计变换,实现了对称无监督学习。
(六)功能性核磁共振成像(fMRI)建模
基于Transformer的方法在解决fMRI中远距离依赖性关系方面也取得了显著突破。如结合血液氧合水平变化的时间序列和功能连接网络的Transformer,成功地学习了fMRI中的时空上下文信息。如ST-Transformer通过线性空间-时间多头注意单元,在数据平衡后计算fMRI中的空间和时间表示,用于孤独症谱系障碍(ASD)的诊断。综上,Transformer为深度解析脑功能区域和时间序列特征关系提供了新的解决方案。
*功能性核磁共振成像(fMRI)和磁共振成像(MRI)的区别:
fMRI和MRI是两种不同但密切相关的成像技术,它们在医学和神经科学中广泛用于研究和临床应用。
1. MRI:MRI是一种用于获取高分辨率体内组织结构图像的成像技术。它基于原子核在强磁场中的共振现象,通过测量不同组织对磁场的响应来生成图像。MRI可以显示组织的结构、器官的位置和大小,对于检测肿瘤、脑部解剖和其他结构方面非常有用。
2. fMRI:与MRI不同,fMRI关注的是测量脑部血流和代谢的变化,以推断不同脑区域的活动水平。fMRI通过检测脑血液氧合水平的变化(BOLD信号)来间接测量神经活动。它主要用于研究大脑在执行任务、处理刺激或进行特定认知功能时的活动。
3. fMRI使用BOLD信号作为衡量脑部活动的指标,而MRI则主要关注组织的结构。BOLD信号是基于血氧水平在神经活动期间的变化。MRI提供了关于脑结构的详细信息,而fMRI提供了有关脑功能的信息。通过结合这两种技术,研究人员可以更全面地理解大脑的结构和功能,并研究它们之间的关联。
(七)脑电图处理
近年来,脑电图(EEG)信号处理也逐渐摒弃传统的基于循环神经网络(RNNs)的方法,转而关注Transformer模型。研究者们引入Transformer模型,如S3T和EEGformer,通过对时空相关性的建模和自注意力机制的应用,为处理EEG信号提供了更灵活、更强大的工具。这些新方法不仅克服了传统方法在并行计算等方面的不足,还为更深入地理解和利用EEG信号提供了前景广阔的研究方向。表格4列举了目前用于EEG数据处理的Transformer的技术细节,供读者参考。
*脑电图(EEG):是一种无创性生理学技术,通过在头皮上放置电极记录和测量大脑电活动。这种方法具有无创性、实时性和高时间分辨率的特点,适用于临床医学、神经科学研究和脑机接口等领域。通过频率分析,EEG信号被分为不同频带,如δ波、θ波、α波、β波和γ波,每个频带与不同的脑状态和活动相关。在临床上,EEG被用于诊断癫痫、睡眠障碍和其他神经系统疾病。总体而言,EEG为理解脑部功能和神经活动提供了重要的信息。
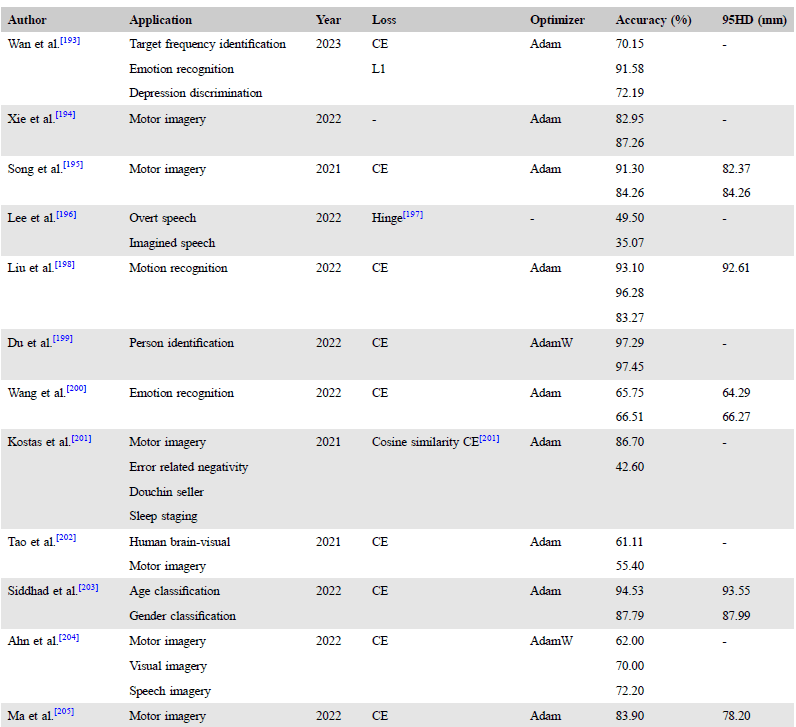
▷表格4:处理EEG数据的Transformers模型细节。图源:参考文献[1]
(八)多任务处理
随着深度学习模型参数规模的扩大,研究者们借助堆叠的多头注意力机制开发了适用于协同多任务的Transformer。比如,多视角嵌入的医学Transformer,通过在轴向、矢状和冠状方向对MRI序列进行采样,使用预训练的卷积编码器进行向量提取,后Transformer被应用于在不同方向上实现自注意力增强。这种方法可应用于预测脑疾病、估计大脑年龄和脑肿瘤分割等任务;Trans-ResNet,则整合了CNN和Transformer,通过可靠的梯度传递,实现对注意力模块的高效特征学习,也可应用于预测脑疾病和估计大脑年龄。
展望未来
尽管Transformer在各个的领域中表现卓越,但仍面临计算复杂度大,参数数量多等诸多局限。因此,在论文中作者总结了未来Transformer模型发展的可能方向。
1.基于图结构的Transformer:作为非结构化数据的代表,图(graph)由点和边组成,有效建构对象内部的依赖关系。比如, GraformerDIR和TRSF-Net将特征图中不同的空间分布建模为各种图结构。基于图结构的Transformer是未来发展的重要方向。期待不久的将来,基于图的Transformer模型能够更灵活地建模和学习远距离依赖关系,解析复杂的脑科学任务。
2. 基于视觉的Transformer:Transformer最初是应用于自然语言处理任务。在视觉任务中,类似于文本,图像嵌入时会被压平处理为一维的最小语义单元。但这样处理会带来一些局限,比如,将富含语义的特征空间压缩成一维的最小语义单元,会破坏语义完整性。基于视觉的Transformer需要生成2D甚至3D专门用于基于视觉的Transformer的变量。
3. 基于Prompt的Transformer:基于Prompt的学习是深度学习模型新的范式。基于Prompt的Transformer可以嵌入更专业的语义,甚至可以引导用户添加先验知识,显著提高模型的学习能力。
*Prompt:一段文本或语句,用于指导机器学习模型生成特定类型、主题或格式的输出。在自然语言处理领域中,Prompt 通常由一个问题或任务描述组成,例如“请将上面的文字翻译成中文”。在图像识别领域中,Prompt 则可以是一个图片描述、标签或分类信息。
4. 超重型Transformer:研究表明,当用于训练的数据集和参数增多时,Transformer的性能有望得到提升。目前一些超重型Transformer确实在复杂场景中表现出色,但随之而来的是更多计算资源的需求。因此,模型压缩和技术微调也许是超重型Transformer的下一关键的优化方向。
5. 轻型Transformer:相较于超重型Transformer,适用于一般用户和移动终端的轻型Transformer的研究也很必要。但从架构上讲,Transformer的多头注意力机制不可避免地会带来海量的参数,因此在不牺牲性能的前提下,研发出较少参数的轻型Transformer将是未来发展的重要方向。
6. 开放的医疗数据集:大模型性能的提升在某种程度上依赖于海量的训练数据集。但目前由于医学数据使用的伦理限制,大规模获取医疗数据非常困难,这也是Transformer应用于医疗领域可能面临的挑战。但相信随着医学数据声明的完善,将有更多的数据集向研究人员公开。
数据集简介
数据集链接
脑肿瘤图像
https://www.synapse.org/#!Synapse:syn51156910/wiki/622351
健康受试者大脑的脑部图像
(100个)
https://data.kitware.com/#collection/591086ee8d777f16d01e0724/folder/58a372e38d777f0721a64dc6
健康受试者大脑的MRI图像
(600张)
IXI Dataset
个体的32通道脑电图数据
(14个)
https://openneuro.org/datasets/ds002680/versions/1.2.0
无血管痉挛的脑动脉瘤图像
(200张)
https://cada.grand-challenge.org/Dataset/
▷表格5. 脑科学领域相关的公共数据集,可复制网址查看。来源:追问编辑部整理
参考资料:
[1]Chen, C. et al. (2023) ‘Understanding the brain with attention: A survey of transformers in Brain Sciences’,Brain‐X, 1(3). doi:10.1002/brx2.29.[2]Vaswani, A. et al. (2023) ‘Attention Is All You Need’,arXiv [Preprint]. doi: https://doi.org/10.48550/arXiv.1706.03762.[3] Sequence to sequence (seq2seq) and attention (no date)Seq2seq and Attention. Available at: https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html (Accessed: 07 December 2023).

















暂无评论内容