
文章来源:AIGC开放社区

图片来源:由无界AI生成
4月18日,著名开源大模型平台Stability.ai在官网宣布,最新文生图模型Stable Diffusion 3 (简称“SD3”)和 SD3 Turbo可以在API中使用。
据悉,本次继续由知名API管理平台Fireworks AI提供服务。与前两代相比,SD3除了生成的图片质量更高之外,可以更好地理解提示文本中嵌入到图片中的文字。
例如,一个色彩缤纷的魔法世界,天空的中央写着“欢迎来到魔法世界”。
前两个模型版本可能无法将“欢迎来到魔法世界”精准嵌入到图片的指定位置或出现扭曲的文字,而SD3可以轻松实现。
此外,SD3的模型权重将很快向Stability AI会员提供,可以在本地部署、运行SD3。
API地址:https://platform.stability.ai/docs/api-reference?_gl=1*1ldjred*_ga*ODY1NjAxMzA1LjE3MDcyNTYwMTM.*_ga_W4CMY55YQZ*MTcxMzM5NDE4OS40NC4xLjE3MTMzOTQyNTUuMC4wLjA.#tag/Generate/paths/~1v2beta~1stable-image~1generate~1sd3/post
Stable Diffusion 3架构简单介绍
今年2月22日,Stability.ai在官网首次展示了SD3并开启候补测试。随后3月5日在arxiv上公布了其论文。
根据其论文介绍,SD3与前两代相比最大技术创新在于,使用了MM-DiT和Flow Matching两种方法来增强模型的输出、训练、优化等,同时支持文本或图像作为提示实现多模态能力。

通常多数文生图模型在生成的过程中,只考虑图像本身而没有充分利用文本信息,所以,输出结果时经常出现“驴头不对马嘴”的情况,甚至是一些无法理解的乱码或者扭曲的图像。
而MM-DiT通过结合Transformer的自注意力机制强大的文本和图像序列处理能力,帮助模型在生成图像时能与文本实现更好的匹配。
当用户输入文本或图像提示时,首先被转换为嵌入表示。文本通过预训练的文本模型编码,而图像则通过预训练的自动编码器转换为潜在空间表示。
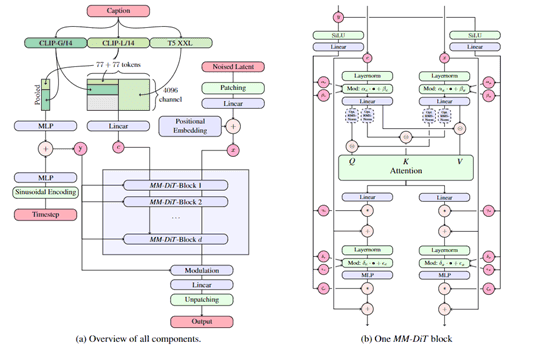
MM-DiT会使用一种调制机制来整合时间步和文本条件信息,会将时间步和文本嵌入与图像的潜在表示进行整合。
接着,MM-DiT会利用一系列的调制注意力和多层感知力进一步混合文本和图像特征。这些块允许模型在保留各自模态特征的同时,进行跨模态的信息交流。
为了帮助SD3更好地处理多模态数据,MM-DiT采用了多头注意力机制,允许模型在不同的表示子空间中并行处理信息。
这也是SD3能深度理解文本提示中的嵌入文字主要原因,MMDiT不仅能将文字转换成图片,还能确保图片能够反映出文字中的所有细节。
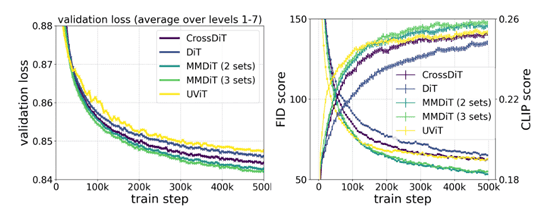
根据测试数据显示,与DiT、CrossDiT、UViT等方法相比,MM-DiT所有指标上表现都非常出色,并且在内部共享权重集。
Flow Matching是一种用于训练Rectified Flow模型的方法,通过最小化生成路径上的误差来改善模型性能,同时帮助模型学习从随机噪声快速转换到目标图像。
在训练过程中,Flow Matching会先定义一个从数据分布到噪声分布的前向过程,这个过程通过一系列的时间步骤来模拟,每个步骤都对应着数据向噪声的逐渐转变。
接着,通过对每个时间步的噪声样本生成一个向量场,可以在概率空间中模拟数据到噪声的转换。
最后,Flow Matching通过最小化一个目标函数来优化生成向量场。该目标函数的作用是帮助模型预测的向量场和真实向量场之间的差异。优化的过程中会尽量减小这个差异,从而提高模型的生成图像预测准确性。
关于SD3更详细的技术解读,小伙伴们可以查看论文。
SD3生成图片展示
根据Stability.ai展示的效果,SD3生成的图片有一些甚至比Midjourney更好,尤其是文字嵌入方面。
一座白色建筑顶部放着一张红色沙发。涂鸦强上写着“城市最佳景观”。

一个印有“他们说在这里思考不好”的纸板箱,纸板箱很大,放在剧场舞台上。

半透明的猪,肚子里有一只更小的猪。

一只奶酪制作的螃蟹,在盘子中。

在山顶上有一位巫师创作了一幅令人惊叹的艺术作品,他用魔法创造了文字”Stable Diffusion 3 API”。

本文素材来源Stability.ai官网、SD3论文,如有侵权请联系删除返回搜狐,查看更多
责任编辑:



















暂无评论内容