
Transformer 问世后被广泛地用在 NLP 的各种任务中,但是却很少出现在计算机视觉领域中。目前计算机视觉主流的模型依然是 CNN,各种 attention 操作也是在 CNN 结构上进行。本文介绍 Vision Transformer (ViT),把图片的区块序列传入 Transformer 进行预测。ViT 首先在大规模的图片数据集上进行预训练,然后再迁移到目标数据集上,得到的分类效果可以和当前最好的 CNN 模型相媲美,但是所需的计算资源大大减少。
1.概述
Transformer 是 2017 年提出的模型,主要基于 Self-Attention 结构,对 Transformer 不熟悉的童鞋可以参考一下之前的文章《Transformer 模型详解》。Transformer 具有较高的计算效率和很好的扩展性,可以支持训练超过 100B 参数的模型。
目前 Transformer 已成为 NLP 领域的主流,衍生出了 BERT、GPT 等模型,但是在计算机视觉领域,Transformer 的应用却很少。本文介绍 Google 在 2020 年的一篇论文《An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale》,论文中提出了 Vision Transformer (ViT),能直接利用 Transformer 对图像进行分类,而不需要卷积网络。为了让 ViT 模型可以处理图片,首先要把图片划分为很多个区块 (类似 NLP 中的 token),然后把区块序列传入 ViT。
论文地址:https://arxiv.org/pdf/2010.11929.pdf
代码地址:https://github.com/google-research/vision_transformer
实验发现,在中等大小的数据集 (如 ImageNet) 上训练得到的 ViT 模型准确率比 SOTA 模型 ResNet (CNN 模型) 低了几个百分点。论文作者认为这是因为 CNN 模型具有平移不变性和局部性等归纳偏好 (inductive biases),而 Transformer 并没有这种归纳偏好,因此在数据量不足的时候准确率不如 CNN 模型。但是如果在大规模的图像数据集 (14M-300M 图片) 上预训练 ViT 再迁移到小规模数据,则 ViT 可以取得非常好的效果,甚至可以超过当前图片识别的最好结果。
2.Vision Transformer

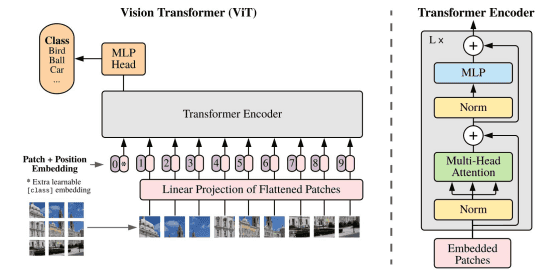
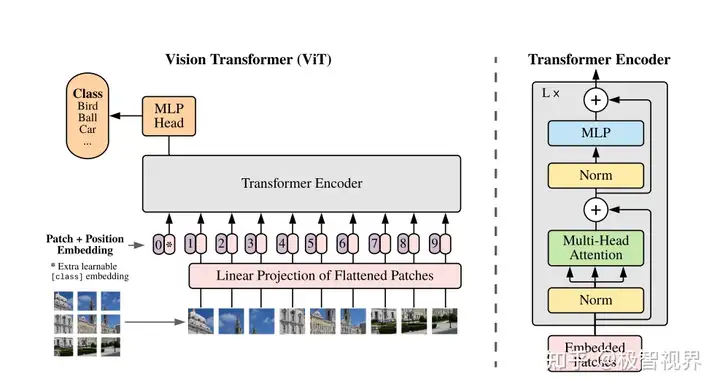
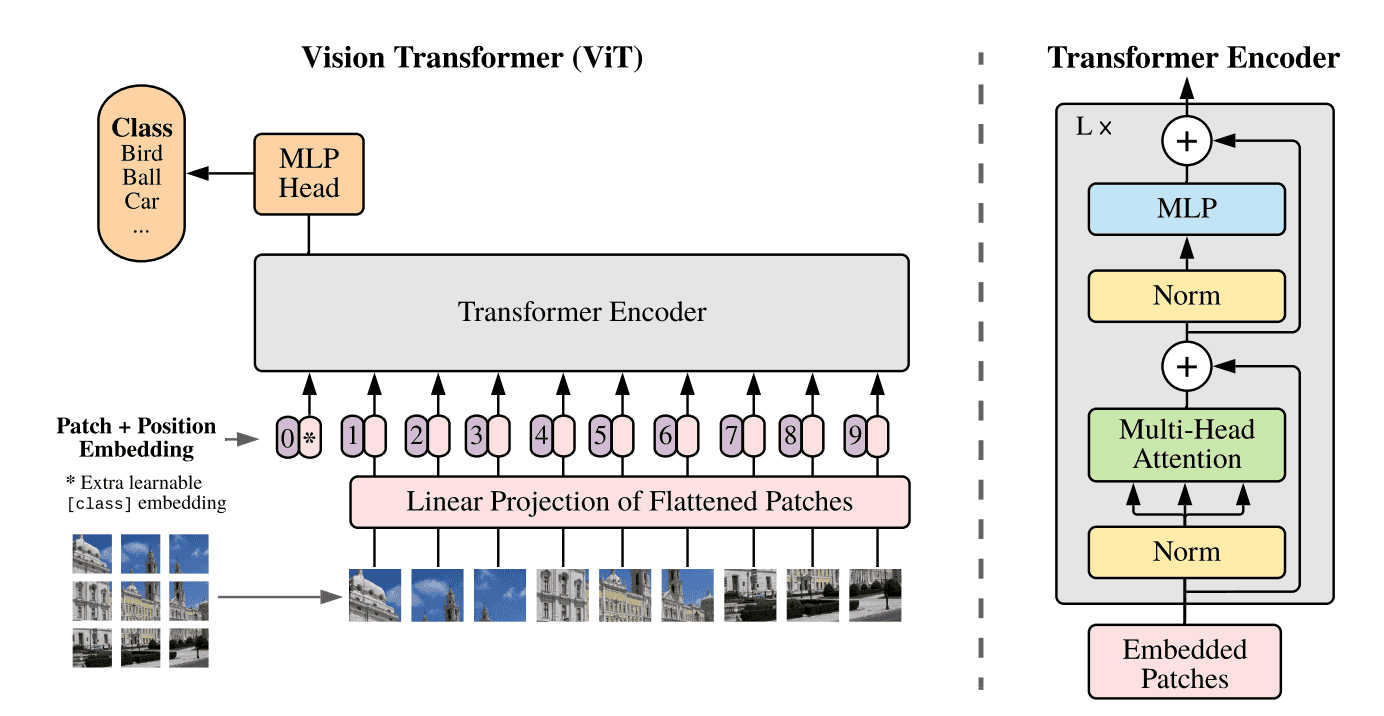
ViT 模型结构图
2.1 ViT 模型
上图是 ViT 的结构,传统的 Transformer 输入时一维的 token embedding 序列,为了处理二维的图像,需要把图像分为几个区块 (patch)。给定一个 H×W×C 的图像以及区块大小 P,可以把图像划分为 N 个 P×P×C 的区块,N=H×W/(P×P)。得到区块后要使用线性变换转为 D 维特征向量,再加上位置编码向量即可。和 BERT 类似,ViT 在序列之前也加入了一个分类标志位 [class]。ViT 输入序列z 如下面的公式所示,其中 x 表示一个图像区块。
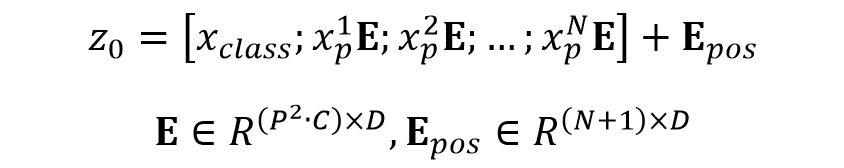
输入序列 z 计算公式
ViT 模型和 Transformer 基本一样,输入序列传入 ViT,然后利用 [class] 标志位的最终输出特征进行分类。ViT 主要由 MSA (多头自注意力) 和 MLP (两层使用 GELU 激活函数的全连接网络) 组成,在 MSA 和 MLP 之前加上 LayerNorm 和残差连接。ViT 的公式如下:
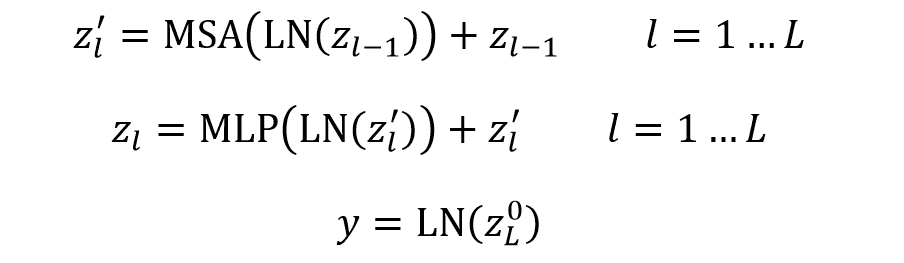
ViT 公式
2.2 ViT 和 CNN 混合结构
可以使用 CNN 输出的 feature map 代替原始图片的区块序列,将 feature map 划分为多个区块,然后用线性映射矩阵E 进行映射。甚至可以把 feature map 划分为多个 1×1 的区块,这相当于直接把 feature map 展开,然后再映射。
2.3 微调和高分辨率
ViT 通常在大数据集上预训练,然后再使用目标数据集微调。因为预训练数据集和目标数据集类别个数不同,因此需要把最后一层预测层移除,换为初始值为 0 的 D×K 全连接层,K 是目标数据集的类别个数。
在微调阶段数据集分辨率比预训练时高通常有比较好的效果。当微调时传入高分辨率的图片,需要保持区块 (patch) 的大小不变,此时序列长度会变长,这会导致预训练得到的 Position Embedding 失去意义。为了解决这个问题,作者采用了插值的方法,根据图像的位置,在预训练得到的 Position Embedding 中插值。插值过程如下图所示。
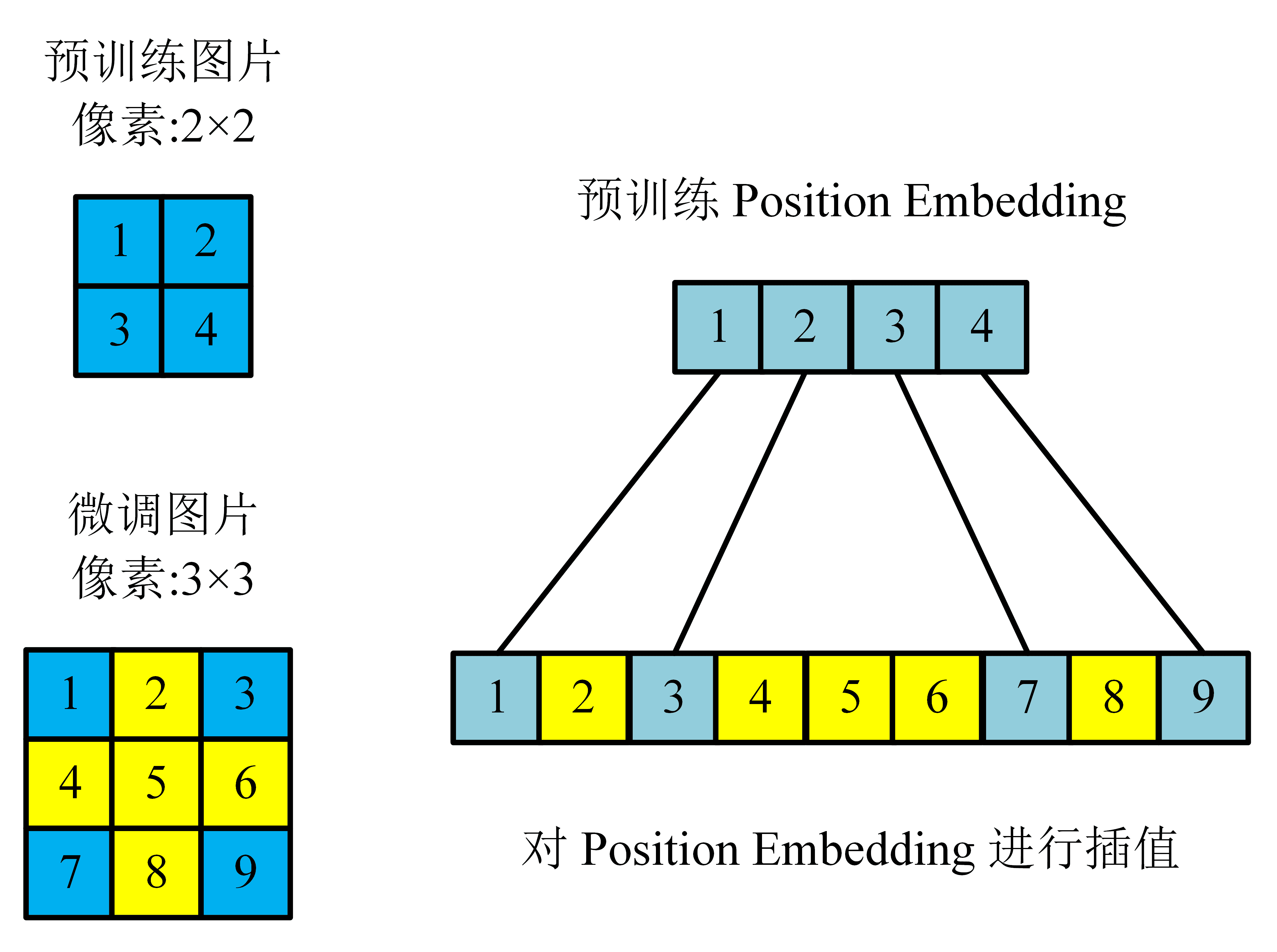
插值过程示意图
3.实验效果
作者使用了三种规模的 ViT 模型,分别是 Base、Large、Huge,参数量如下表所示。用 ViT-L/16 表示 ViT Large 模型,图片区块 (patch) 大小时 16×16。
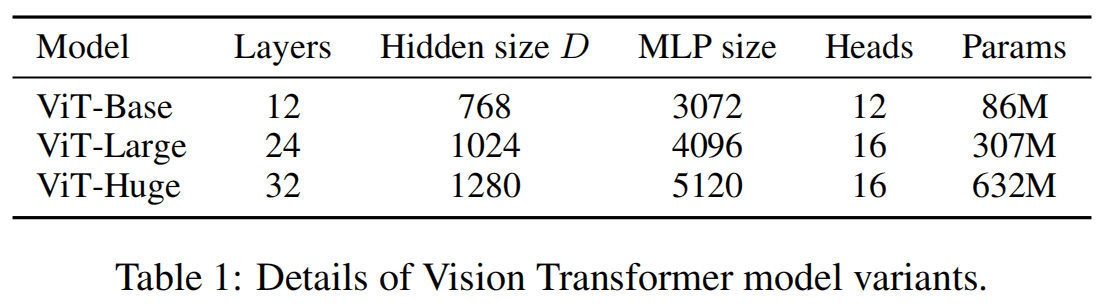
三种规模的 ViT
作者对比了 ViT 和 SOTA 模型 (ResNet) 的分类效果,结果如下表所示,表中 ViT-H/14 使用 JFT-300M 预训练,ViT-L/16 使用 JFT-300M 和 ImageNet-21K 分别进行预训练,ResNet 使用 JFT-300M 预训练。可以看到用 JFT 预训练的 ViT-L/16 在后续所有分类数据集上的性能都可以与 ResNet 媲美,有些甚至超越了 ResNet,并且 ViT-L 的计算效率远远高于 ResNet。
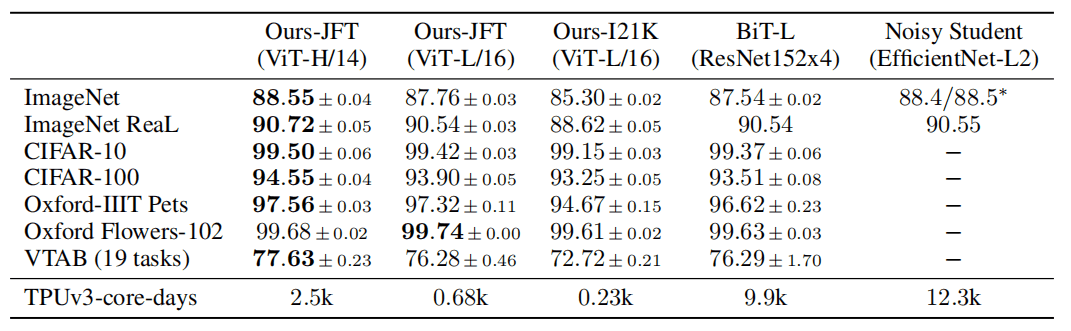
和 SOTA 模型比较实验
作者进行实验测试预训练数据量对 ViT 性能的影响,结果如下图所示。使用了三种不同大小的数据集进行预训练,数据集从小到大排列为 ImageNet、ImageNet-21k、JFT-300M。灰色的部分是不同规模的 BiT (ResNet) 模型所得到的性能区间。可以看到在预训练数据集比较小的时候,BiT 比 ViT 更好,但是随着预训练数据集变大,ViT 模型会超过 BiT 模型。
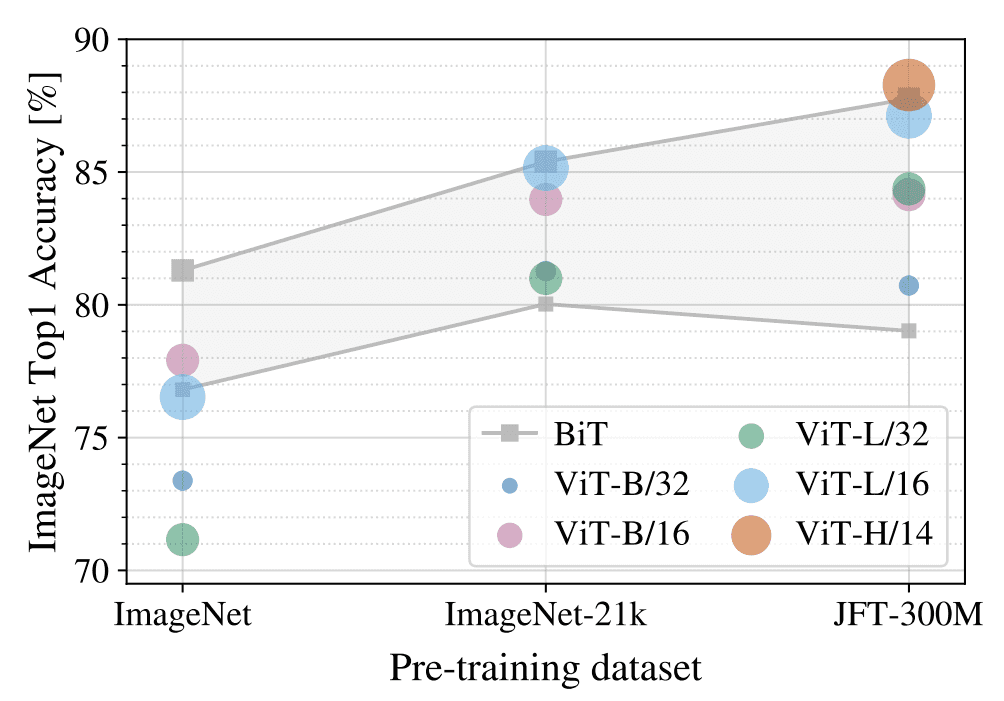
预训练数据量对模型性能的影响
作者还对比了预训练计算量对迁移效果的影响,结果如下图所示。Hybrid 指 ViT 和 ResNet 的混合模型。在算力和性能对比中发现 ViT 明显优于 ResNet,可以用更少的算力得到媲美 ResNet 的性能。在算力较小时 Hybrid 模型优于 ViT,但是随着算力增大,这一现象会消失。
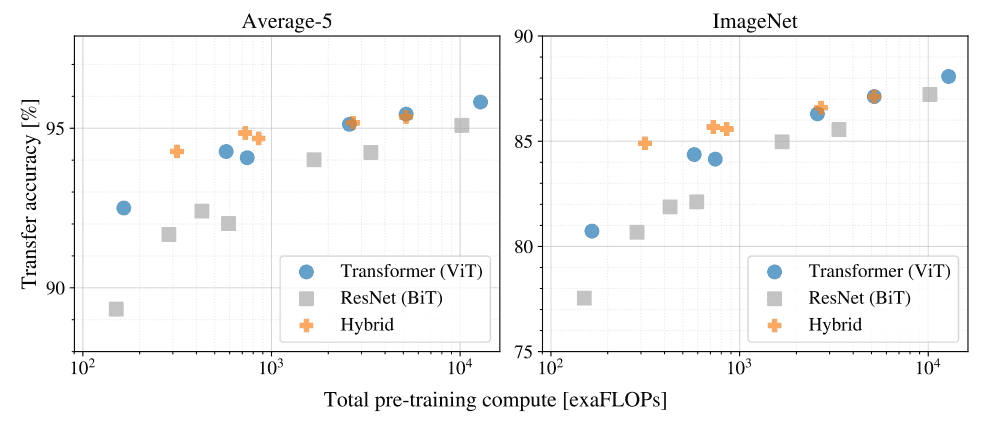
预训练计算量对迁移效果的影响
查看 ViT 的 Attention,可以发现 ViT 能够很好地关注与分类相关的区域,如下图所示。

ViT 模型的 Attention
4.参考文献
An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale
















暂无评论内容