
欢迎关注我,获取我的更多笔记分享
大家好,我是极智视界,本文详细介绍一下 ViT 算法的设计与实现,包括代码。
ViT 全称 Vision Transformer,是 transformer 在 CV 领域应用表现好的开始,而在此之前,CV 领域一直是 CNN 的天下,虽然 ViT 主要用于图像分类这个简单的任务,但它说到底挑战了自从 2012 年 AlexNet 出世以来,卷积神经网络在计算机领域绝对统治的地位。ViT 的重要性不只在于证明了 transformer 在图像分类上也能 work 的很好,其贡献还在于它给大家挖了个大坑,并随之而来井喷出了大量 ViT 变种以及其他视觉任务的应用,如目标检测 (DETR)、语义分割 (SETR)、图像生成 (GANsformer) 、多模态应用 (CLIP) 等。
本文不止会介绍 ViT 的原理,还会介绍 ViT 的实现,包括代码。下面开始。
参考 Paper:《An Image is Worth 16×16 words Transformers for image recognition at scale》。
1 ViT 算法原理
用 CNN 来提图像特征是大家所熟悉的,CNN 里最重要的算子是 卷积,卷积具有两个很重要的特性:translation equivariance 平移等价性 和 locality 局部性。来解释一下:
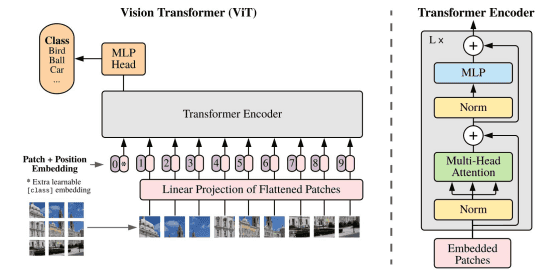
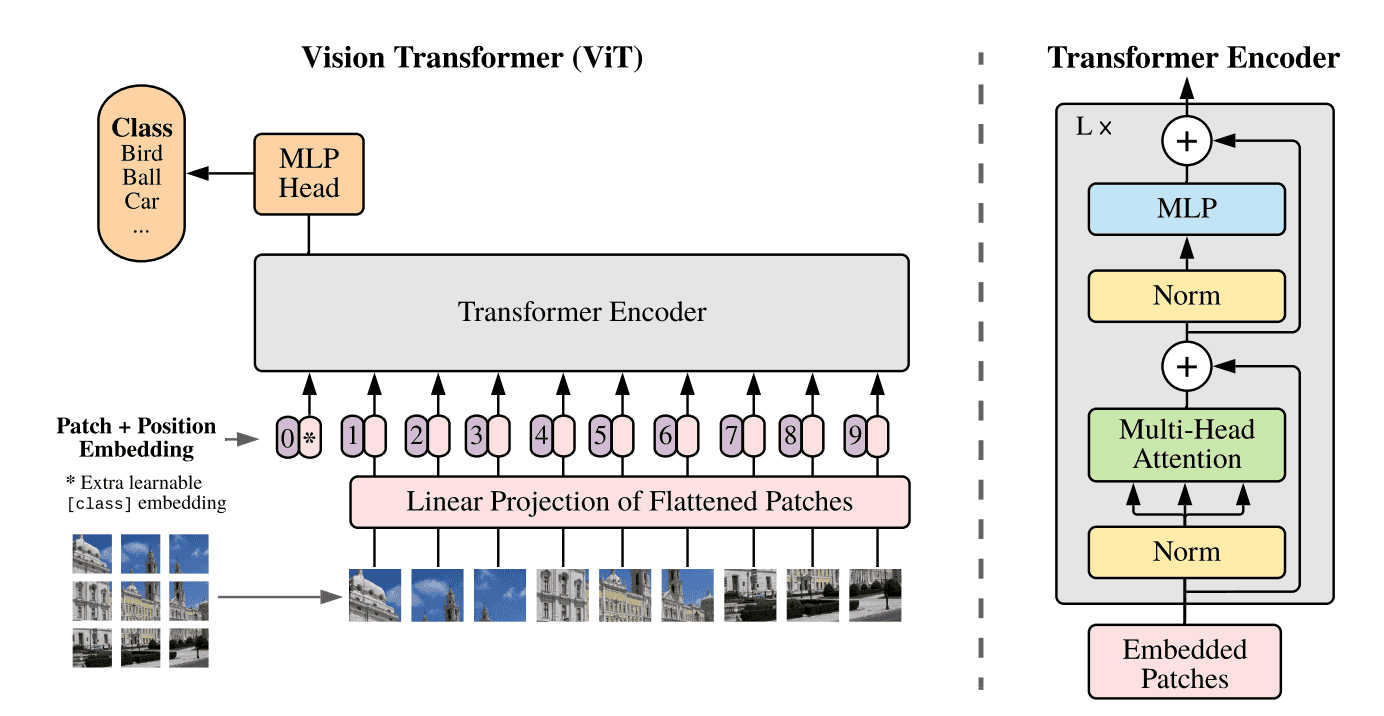
translation equivariance 平移等价性:卷积是个滑窗的过程,每次的滑窗会对应一次矩阵乘,平移等价性的意思是你先做矩阵乘还是先平移滑窗,对卷积结果是不影响的,这最大的好处就是很容易进行并行化,以加速推理;locality 局部性:一般卷积核大小用 3 x 3 的比较多,3 x 3 卷积的感受野是有限的,只能 看 到局部区域,而不能一下子看到全局区域,所以卷积侧重关注在提取局部区域特征的关联,而不能很好的做全局特征的联系,这当然有好有坏;ViT 里面的提特征方法和 CNN 的不一样,套用了 NLP Transformer 的方式,具体是怎么做的呢,用下面这个图可以很好的解释:
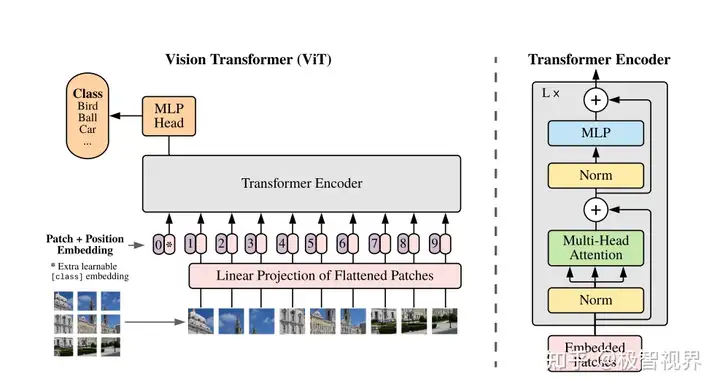
首先思考在 NLP 里,句子都是一维的,而图像数据是二维的,那怎么把二维的图像数据套成跟 NLP 一样一维的呢,有几种方法:
按像素展开,每个像素就是一个patch (一个 patch 类比 NLP 中的一个词),这样的话,如果以 224*224 的输入尺寸来说,patch数 = 224 x 224 = 50176。这样的做的缺点就是 patch数 太大了,是不可接受的,拿 BERT 对比一下,BERT 具有 4810 亿个参数,在 2048 块 TPUv4 下需要训练 20 个小时,而 BERT 的 patch数 也不过 512 而已,所以这显然不行;用特征图作为 Transformer 的输入,比如先接一个 resnet50,出来 14×14 的特征图,即 patch数 = 14×14 = 196,再输入 Transformer;按轴展开,这种是做了两次的自注意力,一次是横轴的自注意力,另一次是纵轴的自注意力,把 H x W 的复杂度 拆成了 H + W 的复杂度;把窗口块作为一个 patch,思想就像卷积那样;ViT
THE END


















暂无评论内容