
辰流看完Transformer之后,梦里都是Attention。
谢谢你,nlp。
谢谢你,attention。
谢谢你,transformer。
感谢多了,或许就要流泪了。
俗话说趁热打铁。第五章中的Transformer虽用于nlp领域,但其对序列数据的独创性处理使得它能够让一个位置能够注意到隔得很远的位置,这具有向其他领域扩展的潜力。
这种扩展就包括Vision Transformer(ViT),把attention扩展到图形学领域的应用中,岂不妙哉?
各种意义上,这个提瓦特大陆的构建都依赖于图形学。图形学在教令院的研究中,可不是可有可无的,这类似于所谓“创世学说”的味道。自然,这也是素论派要研究的一个方向。
机械生命……创世……
谁又能保证,自己不是创世者所创造出来的机械生命呢?
不过,现在苦恼这些问题无异于杞人忧天。辰流默默想。
作为创世学说,图形学的覆盖面实际上很广。
简单来说,处理二维图像,处理三维物体。具体地,例如图像分类,图像分割,三维重建,诸如此类。
就算是辰流,或者旅行者,或者草神,严格来说,他们都是提瓦特大陆上的三维物体。
三维物体的表示形式有很多:
点云(Point Cloud):用许多点表示物体,这些点是对物体的采样。
网格(Mesh):一般是三角形网格,这是提瓦特世界的构建方式。实际上,就是很多个三角面片组成的集合。也因而,它由顶点、边、面组成。如果这些面均为三角形,就成为三角网格(Triangle Mesh)。
体素(Voxel):用一些基本三维几何形状去组成目标物体。用的最多的是立方体。MineCraft大概可以理解为体素表示的一个例子(里面的物体均为立方体)。
隐式表示:一个代表性的例子是NeRF(神经辐射场)。这是一种用神经网络去表示场景/物体的形式。
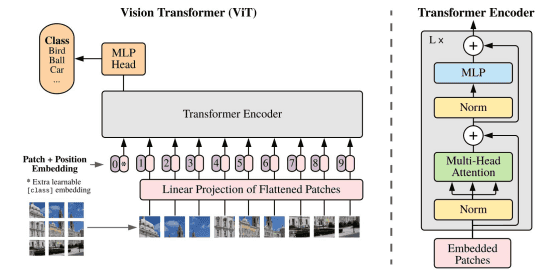
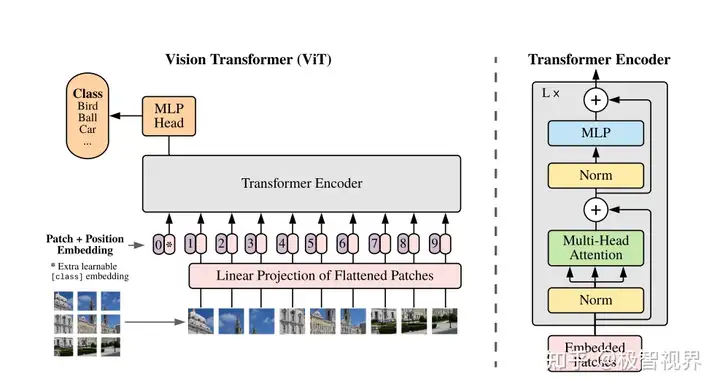
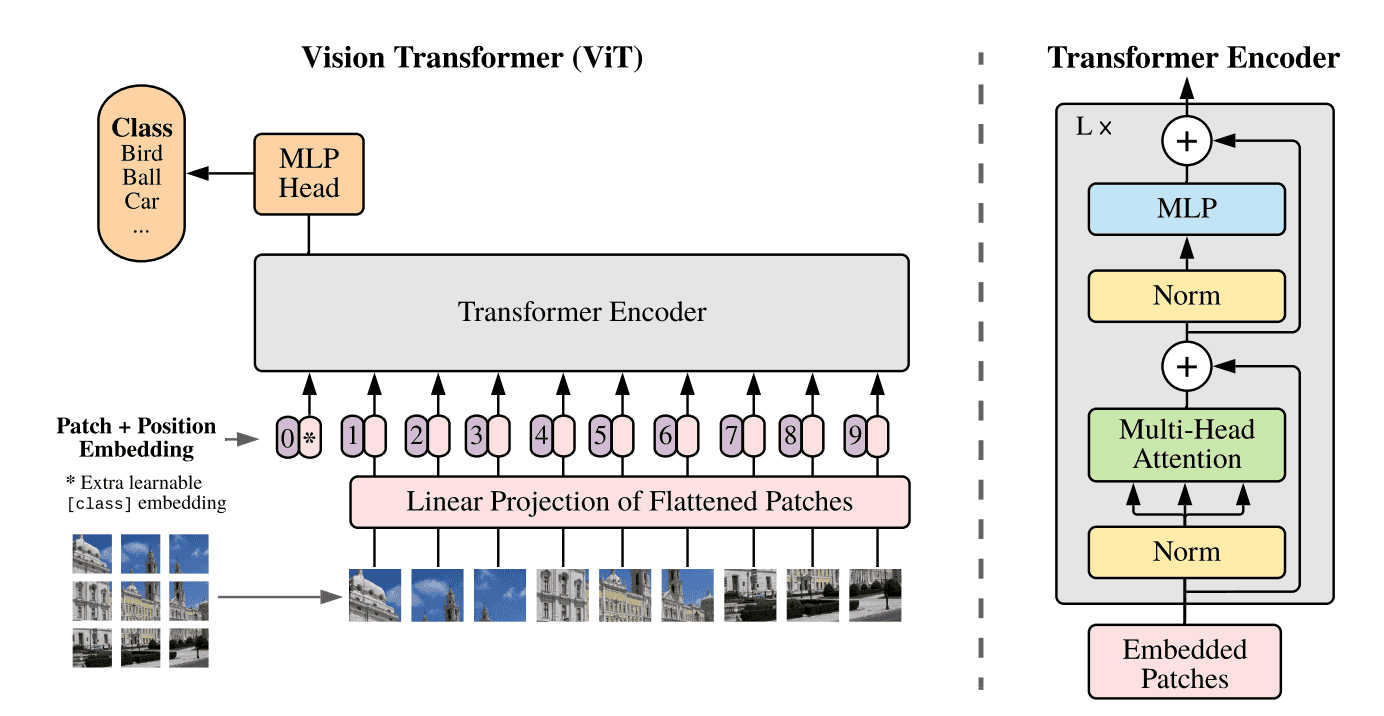
说了那么多,Transformer和图形学究竟会有哪些梦幻联动呢?Vision Transformer(ViT)是怎么构建的?
再次明确,Transformer是处理序列数据的一种方式。
先来看二维图片。注意,序列数据实际上是一维的(排成一队)。同时,如果把图片按照像素直接展平成一维,显然会需要平方级的空间代价。
因此ViT将二维图片分块,把若干个像素(例如,10*10)分成一组,再展平。
这样,二维数据就变成了一维的序列数据。
这就是ViT的基本想法。


















暂无评论内容