
Meta“AI超车”大动作,一切皆可分割
2023-04-08 21:56·红都财经资讯
最近的新技术真是层出不穷,搜索、办公、金融、游戏、电商……AI+似乎正在席卷千行百业。
除以上这些行业外,又有一行业出现新进展,这一次是CV(计算机视觉)领域正迎来“GPT时刻”。
“CV”是指计算机视觉(Computer Vision),它是一门研究如何使机器“看”的科学,目的是让计算机从数字图像或视频中获得高层次的理解,实现对目标的识别、跟踪、测量、分割、生成等功能。
打个比方的话,如果说人理解这个世界是通过双眼与大脑的组合运作,那么CV可以当作就是给人类大脑的计算机装上了两只眼睛。

4 月 6 日,根据 Meta AI 官方博客,Meta AI 宣布推出了一个 AI 模型 Segment Anything Model(SAM,分割一切模型)。他们在博客中介绍说,「SAM 已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』上即开即用,无需额外的训练。」在深度学习领域,这种能力通常被称为零样本迁移,这也是 GPT-4 震惊世人的一大原因。
英伟达人工智能科学家 Jim Fan 表示:「对于 Meta 的这项研究,我认为是计算机视觉领域的 GPT-3 时刻之一。它已经了解了物体的一般概念,即使对于未知对象、不熟悉的场景(例如水下图像)和模棱两可的情况下也能进行很好的图像分割。最重要的是,模型和数据都是开源的。恕我直言,Segment-Anything 已经把所有事情(分割)都做的很好了。」

一, SAM 的核心目标是什么?
Segment Anything 项目的核心目标,就是减少特定任务对于建模专业往右、训练计算量和图像分割中自定义数据标注的需求。为了实现这个目标,Meta AI 团队希望建立一套图像分割基础模型:这是一个可提示模型,在不同数据集上接受训练并能够适应特定任务,类似于在自然语言处理模型中通过揭示词进行生成的方式。但与互联网上丰富的图像、视频和文本形成鲜明反差,训练图像分割模型所需要的数据在网上并不容易获取。因此,研究人员在 Segment Anything 项目中还同步开发了一套通用的可提示分割模型,用它创建出一套规模空前的分割数据集。
SAM 已经能够理解对象的一般概念,可以为任意图像或视频中的任何对象生成掩码,甚至支持它在训练期间从未见过的对象和图像类型。SAM 的通用性足以涵盖广泛用例,并可开箱即用于新的图像“领域”——包括水下照片和细胞显微镜图像,无需任何额外训练(即所谓「零样本迁移」)。


二,SAM 的工作原理:提示分割
在自然语言处理和最近的计算机视觉领域,最令人兴奋的发展成果之一在于基础模型。这些基础模型能够使用“提示”技术对新数据集和任务执行零样本和少样本学习。Meta AI 团队也从这方面进展中汲取了灵感。
经过训练,SAM 能够根据任何提示返回有效的分割掩码,包括前景 / 背景点、粗框或掩码、自由格式文本等一切能够指示图像内分割内容的信息。即使提示不够明确且可能指代多个对象(例如指向衬衫上的一个点可能代表衬衫本体,也可能代表穿着衬衫的人),输出也应合理有效。Meta AI 团队通过这项任务对模型进行预训练,引导其通过提示解决常规的下游分割任务。
研究人员观察到,预训练任务和交互式数据集对模型设计施加了特定约束。具体来讲,该模型需要在网络浏览器的 CPU 上实时运行,这样标注者才能与 SAM 实时交互并高效进行标注。虽然运行时约束意味着要在质量和运行时间之间取得权衡,但他们发现简单的设计在实践中能够取得良好结果。
在工作原理层面,图像编码器会为图像生成一次性嵌入,而轻量级编码器则将所有提示实时转换为嵌入向量。之后,将这两个信息源组合在一个负责预测分割掩码的轻量级解码器内。在计算图像嵌入之后,SAM 能够在 50 毫秒内根据网络浏览器中的任意提示生成相应分割。
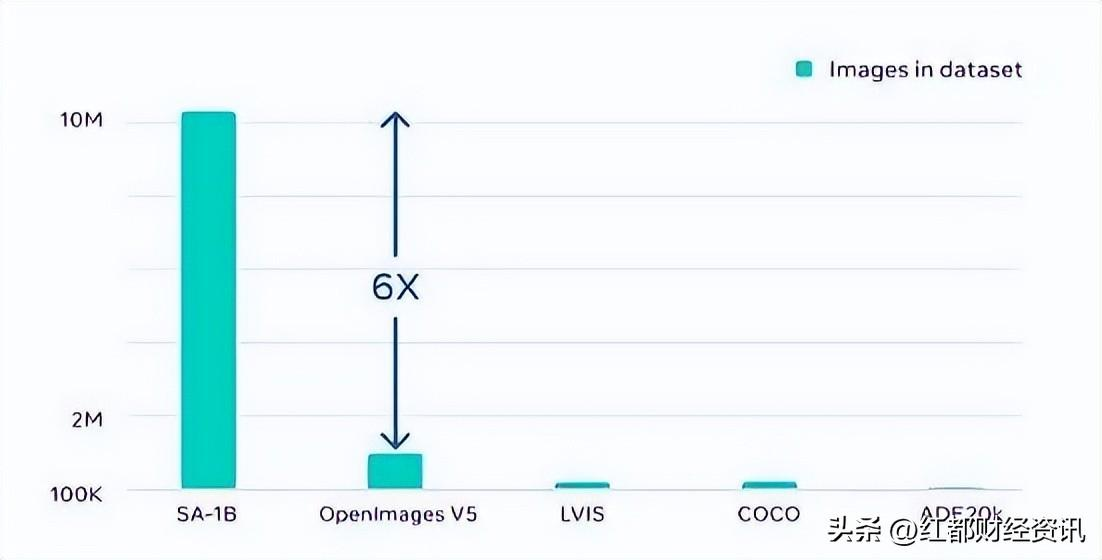
Segment Anything 的功能,是利用数据引擎收集的数百万张图像与掩码进行训练的结果。最终成果是一套包含超 10 亿个分割掩码的数据集,比以往任何分割数据集都要大出 400 倍。


三,AI商业化落地进程最快的赛道
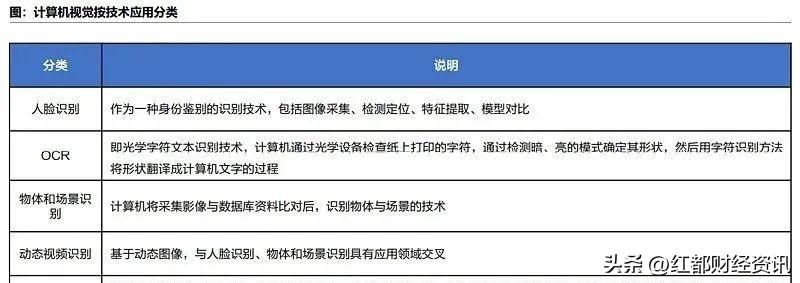
据《人工智能行业研究框架》报告,从技术的应用分类来看,计算机视觉可以分为人脸识别、OCR、物体和场景识别、动态视频识别和姿态识别。
报告指出,人类从外界接受到的各种信息中有超过80%是通过视觉获得的,计算机视觉为人工智能领域中占比最大的分支领域,也是人工智能商业化落地进程最快的赛道,2020年我国计算机视觉产品的市场规模占整个人工智能行业的57%。2021年,中国计算机视觉核心产品的市场规模已接近千亿元大关。此外,与计算机视觉相关的计算机通信设备销售、工程建设、传统业务效益转化等带动相关产业规模超过3000亿元。

国海证券也指出,计算机视觉是计算机模拟甚至超越人类视觉,是人工智能技术层中应用最为广泛、市场占比最高的核心技术。
应用方面,计算机视觉技术在泛安防、金融、互联网、医疗、工业、政务等领域得到广泛应用。
具体来看,出于政策和财政支持等原因,计算机视觉产品技术在泛安防(包括公安、交通、社区、文教卫等多个领域)仍是计算机视觉乃至整个国内人工智能产业实际落地的重要基石,2021年国内泛安防领域计算机视觉核心产品占计算机视觉总核心产品规模的70.7%。
此外,医疗领域现阶段市场规模仍较小,部分场景已经成熟,随着以计算机视觉为核心的AI医学影像辅助诊断产品及新型智能医疗器械在各级医院及医疗机构的铺开,潜力较大。
总体来看,国海证券认为计算机视觉商业化尚处黎明之前。

四,相关产业链
资料显示,计算机视觉行业的产业链上游为视觉传感器、芯片、算法框架、IaaS平台,中游为计算机视觉解决方案厂商,向产业链上下游延展,持续拓宽下游应用领域边界下游包括制造业、金融服务、公共服务业等在内的各个行业。
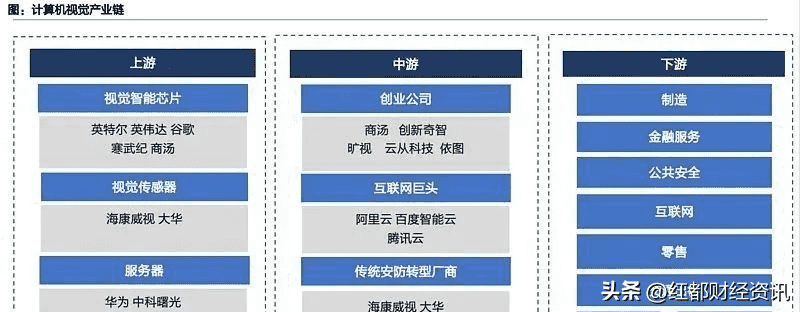
从产业链格局来看,计算机视觉领域已形成三大阵营:
1)以商汤、旷视、依图、云从四小龙为首的初创企业,凭借先进的算法逐步向各领域拓展;
2)以海康、大华、宇视为代表的传统安防巨头,保持原有优势的同时积极引入或自研相关算法,提高竞争力;
3)以BAT、华为等互联网、ICT领域的巨头,通过技术输出和资本扩大布局。
学术领域,计算机视觉已从过去的理论研究逐步转向应用,仍为以谷歌、微软、Meta等为首的海外主导,国内商汤、百度集团、腾讯控股、阿里巴巴也颇有建树。
五,展望未来
可以预计,在未来,在任何需要在图像中查找和分割对象的应用中,都有SAM的用武之地。SAM可以成为更大的AI系统的一部分,对世界进行更通用的多模态理解,
比如,理解网页的视觉和文本内容。
比如在AR/VR领域,SAM可以根据用户的视线选择对象,然后把对象「提升」为3D。
对于内容创作者,SAM可以提取图像区域进行拼贴,或者视频编辑。SAM还可以在视频中定位、跟踪动物或物体,有助于自然科学和天文学研究。
CV领域诸如电动车的自动驾驶功能、电力行业的线缆检测报警、流水线机器人分拣等等估计会发生跃迁式升级。
未来,SAM 可通过 AR 眼镜识别日常物品,并向用户发出提醒和提示。

SAM 拥有广泛的潜在影响范围,也许有一天能帮助农牧业和生物学家开展研究。
AI分割一切!智源提出通用分割模型SegGPT,「一通百通」的那种
2023-04-09 13:46·量子位
允中 发自 凹非寺
量子位 | 公众号 QbitAI
视觉领域的GPT-3时刻,真的要来了?
Meta分割一切的SAM(SegmentAnything Model)刚炸完场,几乎同时,国内的智源研究院视觉团队也提出了通用分割模型SegGPT——
Segment Everything in Context,首个利用视觉上下文完成各种分割任务的通用视觉模型。
就像这样,在一张画面中标注出彩虹,就能批量分割其他画面中的彩虹。

和 SAM 相比,视觉模型的 In-context 能力是最大差异点 :
SegGPT “一通百通”:可使用一个或几个示例图片和对应的掩码即可分割大量测试图片。用户在画面上标注识别一类物体,即可批量化识别分割出其他所有同类物体,无论是在当前画面还是其他画面或视频环境中。SAM“一触即通”:通过一个点、边界框或一句话,在待预测图片上给出交互提示,识别分割画面上的指定物体。这也就意味着,SAM的精细标注能力,与SegGPT的批量化标注分割能力,还能进一步相结合,产生全新的CV应用。

具体而言,SegGPT 是智源通用视觉模型 Painter 的衍生模型,针对分割一切物体的目标做出优化。
SegGPT 训练完成后无需微调,只需提供示例即可自动推理并完成对应分割任务,包括图像和视频中的实例、类别、零部件、轮廓、文本、人脸等等。
该模型具有以下优势能力:
通用能力:SegGPT具有上下文推理能力,模型能够根据上下文(prompt)中提供掩码,对预测进行自适应的调整,实现对“everything”的分割,包括实例、类别、零部件、轮廓、文本、人脸、医学图像等。灵活推理能力:支持任意数量的prompt;支持针对特定场景的tuned prompt;可以用不同颜色的mask表示不同目标,实现并行分割推理。自动视频分割和追踪能力:以第一帧图像和对应的物体掩码作为上下文示例,SegGPT能够自动对后续视频帧进行分割,并且可以用掩码的颜色作为物体的ID,实现自动追踪。更多案例展示
作者在广泛的任务上对SegGPT进行了评估,包括少样本语义分割、视频对象分割、语义分割和全景分割。下图中具体展示了SegGPT在实例、类别、零部件、轮廓、文本和任意形状物体上的分割结果。

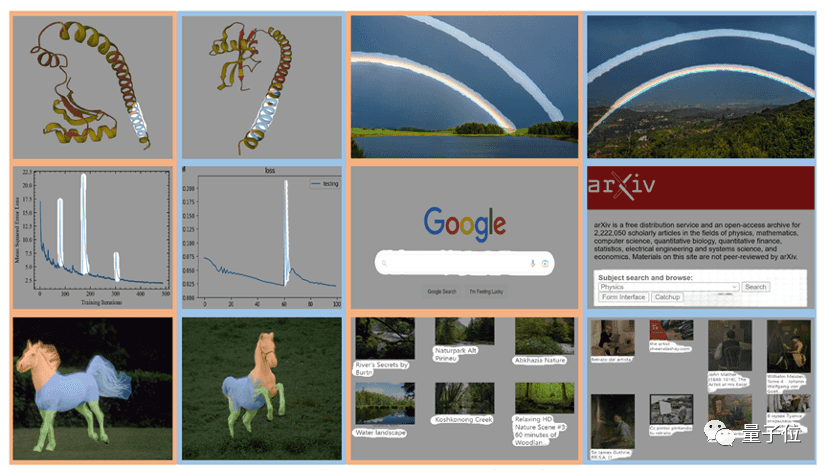
用画笔大致圈出行星环带(左图),在预测图中准确输出目标图像中的行星环带(右图)。

SegGPT能够根据用户提供的宇航员头盔掩码这一上下文(左图),在新的图片中预测出对应的宇航员头盔区域(右图)。

训练方法
SegGPT将不同的分割任务统一到一个通用的上下文学习框架中,通过将各类分割数据转换为相同格式的图像来统一各式各样的数据形式。
具体来说,SegGPT的训练被定义为一个上下文着色问题,对于每个数据样本都有随机的颜色映射。
目标是根据上下文完成各种任务,而不是依赖于特定的颜色。训练后,SegGPT可以通过上下文推理在图像或视频中执行任意分割任务,例如实例、类别、零部件、轮廓、文本等。

论文地址:https://arxiv.org/abs/2211.07636
代码地址:https://github.com/baaivision/Painter
Demo:https://huggingface.co/spaces/BAAI/SegGPT
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
Meta“分割一切”!IDEA领衔国内团队打造:检测、分割、生成一切
2023-04-10 15:57·新智元
编辑:桃子 好困
【新智元导读】Meta的SAM「分割一切」模型刚发布,国内团队就进行了二创,打造了一个最强的零样本视觉应用Grounded-SAM,不仅能分割一切,还能检测一切,生成一切。
Meta的「分割一切」模型横空出世后,已经让圈内人惊呼CV不存在了。
就在SAM发布后一天,国内团队在此基础上搞出了一个进化版本「Grounded-SAM」。

注:项目的logo是团队用Midjourney花了一个小时做的
Grounded-SAM把SAM和BLIP、Stable Diffusion集成在一起,将图片「分割」、「检测」和「生成」三种能力合一,成为最强Zero-Shot视觉应用。
网友纷纷表示,太卷了!
谷歌大脑的研究科学家、滑铁卢大学计算机科学助理教授Wenhu Chen表示「这也太快了」。
AI大佬沈向洋也向大家推荐了这一最新项目:
Grounded-Segment-Anything:自动检测、分割和生成任何有图像和文本输入的东西。边缘分割可以进一步改进。
截至目前,这个项目在GitHub上已经狂揽2k星。
检测一切,分割一切,生成一切
上周,SAM的发布让CV迎来了GPT-3时刻。甚至,Meta AI声称这是史上首个图像分割基础模型。
该模型可以在统一的框架prompt encoder内,指定一个点、一个边界框、一句话,直接一键分割出任何物体。
SAM具有广泛的通用性,即具有了零样本迁移的能力,足以涵盖各种用例,不需要额外训练,就可以开箱即用地用于新的图像领域,无论是水下照片,还是细胞显微镜。
由此可见,SAM可以说是强到发指。
而现在,国内研究者基于这个模型想到了新的点子,将强大的零样本目标检测器Grounding DINO与之结合,便能通过文本输入,检测和分割一切。
借助Grounding DINO强大的零样本检测能力,Grounded SAM可以通过文本描述就可以找到图片中的任意物体,然后通过SAM强大的分割能力,细粒度的分割出mas。
最后,还可以利用Stable Diffusion对分割出来的区域做可控的文图生成。
再Grounded-SAM具体实践中,研究者将Segment-Anything与3个强大的零样本模型相结合,构建了一个自动标注系统的流程,并展示出非常非常令人印象深刻的结果!
这一项目结合了以下模型:
· BLIP:强大的图像标注模型
· Grounding DINO:最先进的零样本检测器
· Segment-Anything:强大的零样本分割模型
· Stable-Diffusion:出色的生成模型
所有的模型既可以组合使用,也可以独立使用。组建出强大的视觉工作流模型。整个工作流拥有了检测一切,分割一切,生成一切的能力。
该系统的功能包括:
BLIP+Grounded-SAM=自动标注器
使用BLIP模型生成标题,提取标签,并使用Ground-SAM生成框和掩码:
· 半自动标注系统:检测输入的文本,并提供精确的框标注和掩码标注。
· 全自动标注系统:
首先使用BLIP模型为输入图像生成可靠的标注,然后让Grounding DINO检测标注中的实体,接着使用SAM在其框提示上进行实例分割。
Stable Diffusion+Grounded-SAM=数据工厂
· 用作数据工厂生成新数据:可以使用扩散修复模型根据掩码生成新数据。
Segment Anything+HumanEditing
在这个分支中,作者使用Segment Anything来编辑人的头发/面部。
· SAM+头发编辑
· SAM+时尚编辑
作者对于Grounded-SAM模型提出了一些未来可能的研究方向:
自动生成图像以构建新的数据集;分割预训练的更强大的基础模型;与(Chat-)GPT模型的合作;一个完整的管道,用于自动标注图像(包括边界框和掩码),并生成新图像。
作者介绍
Grounded-SAM项目其中的一位研究者是清华大学计算机系的三年级博士生刘世隆。
他近日在GitHub上介绍了自己和团队一起做出的最新项目,并称目前还在完善中。
现在,刘世隆是粤港澳大湾区数字经济研究院(IDEA研究院),计算机视觉与机器人研究中心的实习生,由张磊教授指导,主要研究方向为目标检测,多模态学习。
在此之前,他于2020年获得了清华大学工业工程系的学士学位,并于2019年在旷视实习过一段时间。
个人主页:http://www.lsl.zone/
顺便提一句,刘世隆也是今年3月份发布的目标检测模型Grounding DINO的一作。
此外,他的4篇论文中了CVPR 2023,2篇论文被ICLR 2023接收,1篇论文被AAAI 2023接收。
论文地址:https://arxiv.org/pdf/2303.05499.pdf
而刘世隆提到的那位大佬——任天和,目前在IDEA研究院担任计算机视觉算法工程师,也由张磊教授指导,主要研究方向为目标检测和多模态。
此外,项目的合作者还有,中国科学院大学博士三年级学生黎昆昌,主要研究方向为视频理解和多模态学习;IDEA研究院计算机视觉与机器人研究中心实习生曹赫,主要研究方向为生成模型;以及阿里云高级算法工程师陈佳禹。
任天和、刘世隆
安装运行
项目需要安装python 3.8及以上版本,pytorch 1.7及以上版本和torchvision 0.8及以上版本。此外,作者强烈建议安装支持CUDA的PyTorch和TorchVision。
安装Segment Anything:
python-m pip install -e segment_anything安装GroundingDINO:
python -m pip install -e GroundingDINO安装diffusers:
pip install –upgrade diffusers[torch]安装掩码后处理、以COCO格式保存掩码、example notebook和以ONNX格式导出模型所需的可选依赖。同时,项目还需要jupyter来运行example notebook。
pipinstall opencv-python pycocotools matplotlib onnxruntime onnx ipykernelGrounding DINO演示
下载groundingdino检查点:
cd Grounded-Segment-Anything wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth运行demo:
export CUDA_VISIBLE_DEVICES=0 python grounding_dino_demo.py \ –config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \ –grounded_checkpoint groundingdino_swint_ogc.pth \ –input_image assets/demo1.jpg \ –output_dir “outputs” \ –box_threshold 0.3 \ –text_threshold 0.25 \ –text_prompt “bear” \ –device “cuda”模型预测可视化将保存在output_dir中,如下所示:
Grounded-Segment-Anything+BLIP演示
自动生成伪标签很简单:
1. 使用BLIP(或其他标注模型)来生成一个标注。
2. 从标注中提取标签,并使用ChatGPT来处理潜在的复杂句子。
3. 使用Grounded-Segment-Anything来生成框和掩码。
export CUDA_VISIBLE_DEVICES=0 python automatic_label_demo.py \ –config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \ –grounded_checkpoint groundingdino_swint_ogc.pth \ –sam_checkpoint sam_vit_h_4b8939.pth \ –input_image assets/demo3.jpg \ –output_dir “outputs” \ –openai_key your_openai_key \ –box_threshold 0.25 \ –text_threshold 0.2 \ –iou_threshold 0.5 \ –device “cuda”伪标签和模型预测可视化将保存在output_dir中,如下所示:
Grounded-Segment-Anything+Inpainting演示
CUDA_VISIBLE_DEVICES=0 python grounded_sam_inpainting_demo.py \ –config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \ –grounded_checkpoint groundingdino_swint_ogc.pth \ –sam_checkpoint sam_vit_h_4b8939.pth \ –input_image assets/inpaint_demo.jpg \ –output_dir “outputs” \ –box_threshold 0.3 \ –text_threshold 0.25 \ –det_prompt “bench” \ –inpaint_prompt “A sofa, high quality, detailed” \ –device “cuda”Grounded-Segment-Anything+Inpainting Gradio APP
python gradio_app.py作者在此提供了可视化网页,可以更方便的尝试各种例子。
网友评论
对于这个项目logo,还有个深层的含义:
一只坐在地上的马赛克风格的熊。坐在地面上是因为ground有地面的含义,然后分割后的图片可以认为是一种马赛克风格,而且马塞克谐音mask,之所以用熊作为logo主体,是因为作者主要示例的图片是熊。
看到Grounded-SAM后,网友表示,知道要来,但没想到来的这么快。
项目作者任天和称,「我们用的Zero-Shot检测器是目前来说最好的。」
未来,还会有web demo上线。
最后,作者表示,这个项目未来还可以基于生成模型做更多的拓展应用,例如多领域精细化编辑、高质量可信的数据工厂的构建等等。欢迎各个领域的人多多参与。
参考资料:
https://github.com/IDEA-Research/Grounded-Segment-Anything
https://www.reddit.com/r/MachineLearning/comments/12gnnfs/r_groundedsegmentanything_automatically_detect/
https://zhuanlan.zhihu.com/p/620271321



















暂无评论内容