
允中 发自 凹非寺
量子位 | 公众号 QbitAI
视觉领域的GPT-3时刻,真的要来了?
Meta分割一切的SAM(SegmentAnything Model)刚炸完场,几乎同时,国内的智源研究院视觉团队也提出了通用分割模型SegGPT——
Segment Everything in Context,首个利用视觉上下文完成各种分割任务的通用视觉模型。
就像这样,在一张画面中标注出彩虹,就能批量分割其他画面中的彩虹。

和 SAM 相比,视觉模型的 In-context 能力是最大差异点 :
SegGPT “一通百通”:可使用一个或几个示例图片和对应的掩码即可分割大量测试图片。用户在画面上标注识别一类物体,即可批量化识别分割出其他所有同类物体,无论是在当前画面还是其他画面或视频环境中。SAM“一触即通”:通过一个点、边界框或一句话,在待预测图片上给出交互提示,识别分割画面上的指定物体。这也就意味着,SAM的精细标注能力,与SegGPT的批量化标注分割能力,还能进一步相结合,产生全新的CV应用。

具体而言,SegGPT 是智源通用视觉模型 Painter 的衍生模型,针对分割一切物体的目标做出优化。
SegGPT 训练完成后无需微调,只需提供示例即可自动推理并完成对应分割任务,包括图像和视频中的实例、类别、零部件、轮廓、文本、人脸等等。
该模型具有以下优势能力:
通用能力:SegGPT具有上下文推理能力,模型能够根据上下文(prompt)中提供掩码,对预测进行自适应的调整,实现对“everything”的分割,包括实例、类别、零部件、轮廓、文本、人脸、医学图像等。灵活推理能力:支持任意数量的prompt;支持针对特定场景的tuned prompt;可以用不同颜色的mask表示不同目标,实现并行分割推理。自动视频分割和追踪能力:以第一帧图像和对应的物体掩码作为上下文示例,SegGPT能够自动对后续视频帧进行分割,并且可以用掩码的颜色作为物体的ID,实现自动追踪。更多案例展示
作者在广泛的任务上对SegGPT进行了评估,包括少样本语义分割、视频对象分割、语义分割和全景分割。下图中具体展示了SegGPT在实例、类别、零部件、轮廓、文本和任意形状物体上的分割结果。

用画笔大致圈出行星环带(左图),在预测图中准确输出目标图像中的行星环带(右图)。

SegGPT能够根据用户提供的宇航员头盔掩码这一上下文(左图),在新的图片中预测出对应的宇航员头盔区域(右图)。

训练方法
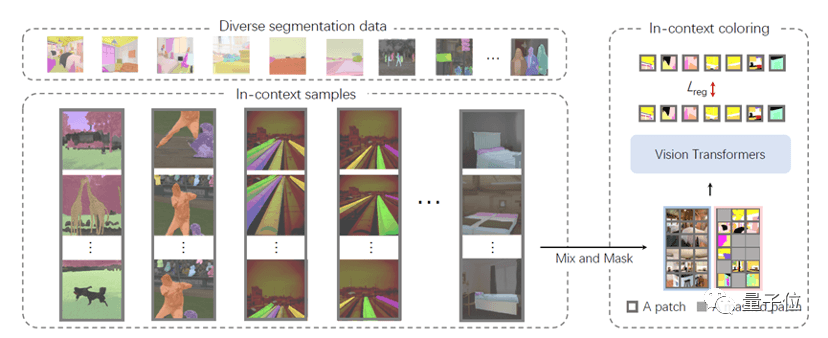
SegGPT将不同的分割任务统一到一个通用的上下文学习框架中,通过将各类分割数据转换为相同格式的图像来统一各式各样的数据形式。
具体来说,SegGPT的训练被定义为一个上下文着色问题,对于每个数据样本都有随机的颜色映射。
目标是根据上下文完成各种任务,而不是依赖于特定的颜色。训练后,SegGPT可以通过上下文推理在图像或视频中执行任意分割任务,例如实例、类别、零部件、轮廓、文本等。
论文地址:https://arxiv.org/abs/2211.07636
代码地址:https://github.com/baaivision/Painter
Demo:https://huggingface.co/spaces/BAAI/SegGPT
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态



















暂无评论内容