
AI领域战火再次升级。这次是人工智能另一重要分支,计算机视觉领域迎来关键转折——
4月5日周三,Meta正式推出模型SAM(Segment Anything Model),称这一模型可用于识别图像和视频中的物体,甚至是从未被训练学习过的物品。技术论文也一并推出,标题甚至只有两个单词——Segment Anything(分割一切)。
消息一出,国内外科研圈齐齐震动,对此,已有人发出了这样的感叹:
——“这是计算机视觉领域的GPT时刻。”
···
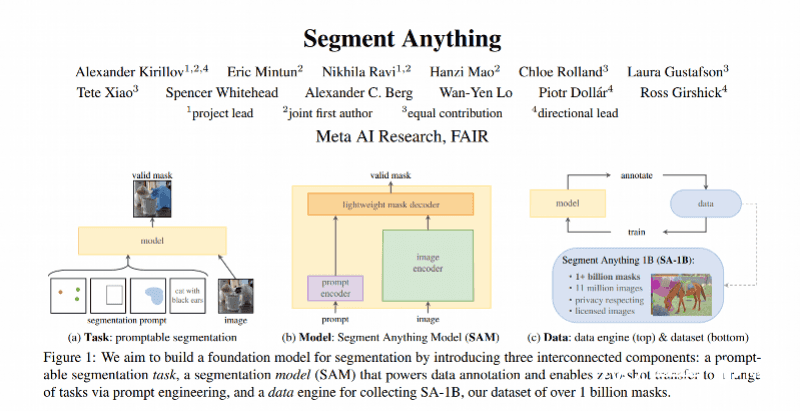
要了解这一模型,首先要明白此次官方介绍中的一个关键词——分割(Segment)。
这是计算机视觉(Computer vision,CV)领域中的核心任务,即识别某一图像像素是否属于某一个对象。相关技术可以应用在自动驾驶的感知系统、医疗影像、图像美化、三维重建等多个领域。
如果说ChatGPT的能力通俗来讲是“说话”,那么这次SAM的能力就是“识图”或“抠图”。而就是在这种看似普通的能力上,双方都展现出了一种“朴素的强大”:
对于任何一张照片,SAM都可以快速识别其中的各个物体并将其标出。根据论文数据,基于单块英伟达V100显卡的算力,模型能在2-3秒内识别出一张1200×800分辨率图像中的所有物体。

不仅是静态图像,SAM也能处理动态视频。在Meta官网的演示中,模型能够快速识别出一段视频中特定物品的名称、种类或其他属性信息。
同时,官方也表示这一功能将在未来与Meta的VR/AR设备相结合,比如用于通过AR眼镜识别日常物品,向用户提示提醒和指示。
上述分割都属于“自动分割”,即让AI按照一定规则自动提取画面中的物体。
论文强调,SAM在各种分割任务上具有较强的零样本(Zero-shot Transfer)能力,也就是说,即使没有任何先验知识或监督,没有在特定领域进行额外训练或微调(Fine Tune),SAM仍能对图像中的特定事物进行分割。
而除了“自动分割”,SAM模型也提供了“即时分割”(或“交互分割”)的能力,即允许用户使用一个可交互的界面,实时地对画面进行操作。
而SAM可接受的输入包括鼠标的悬浮点击、框选或者语言描述。也就是说,用户可以通过这些方式实时定位出画面中具体物体的轮廓。而也像是ChatGPT的持续对话一样——用户也可以不断对SAM下达多个指令,直到选出自己想要的物体。
而对于“抠”出来的图像,也可以再次提取出来,进行二次编辑(改变颜色或进行三维重建)。Meta官方提供的数据显示,基于SAM及相关平台,平均14秒就可以完成“交互分割”,最快可达7秒,而这个速度比之前经典方法快5倍之多。

···
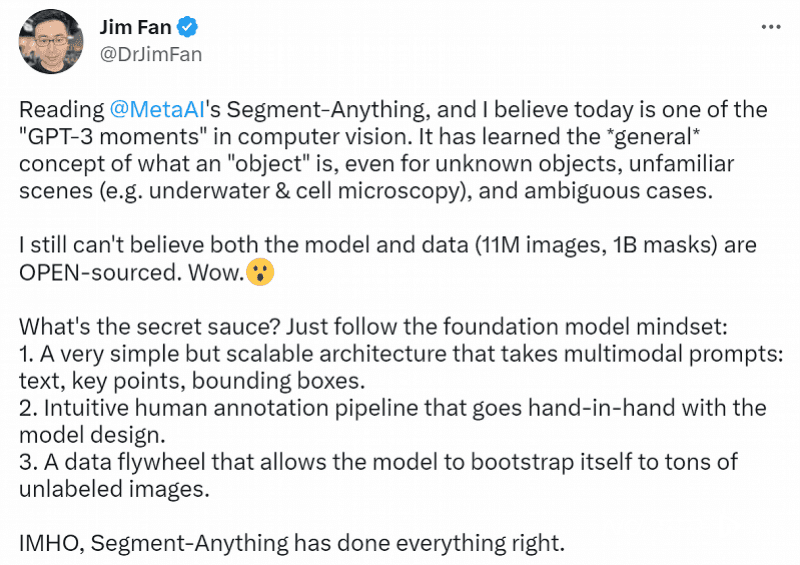
在Meta推出SAM模型当天,英伟达AI科学家Jim Fan发推表示,这是可以被称作计算机视觉领域的“GPT-3时刻”的一天,因为SAM模型已经能理解“物品”或者“对象”的一般概念,即使对于不熟悉的、未知的、模棱两可的画面也能够完成较好的理解。
同时,他还在推文中强调,“难以想象模型和数据都是开源的。”
是的,随着模型发布,Meta现已将模型及其背后的训练数据集一并开源。
SAM模型背后的数据集是一个包括了1100万张图像和11亿个掩膜(指图像分割任务重被选定的具体物体)的巨大训练数据集,由Meta研究团队进行收集和标注,也是当前最大的图像分割数据集,可以通过Meta官网进行下载。模型也可以在GitHub上进行查看或下载。
此外,Meta也推出了SAM模型的Demo网页,点击即可进行试用。
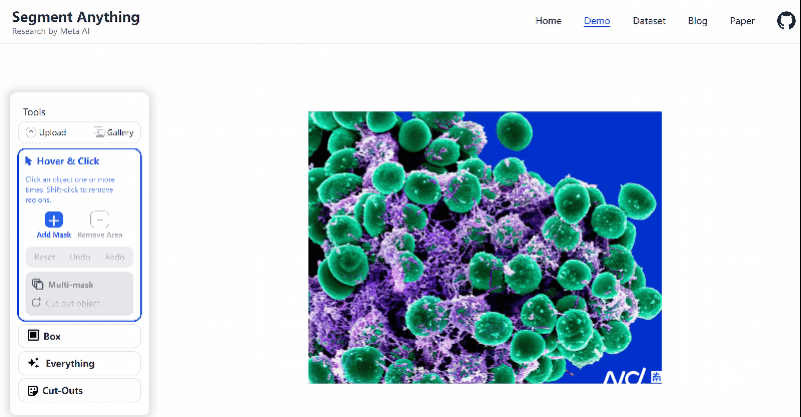
对此,各个领域的科学家已经兴致勃勃地开始试用。有自然科学领域的学者通过SAM识别卫星图像、有医学家通过它识别人体成像、还有生物学家将其应用到了显微镜下的组织图像中,甚至开发了相应插件……
而Meta也表示,当前公司内部也已开始在Facebook、Instagram等社交平台上照片的标记、内容审核和内容推荐等领域试用SAM相关技术,之后,生成式AI也将作为今年的重点优先事项,被逐渐整合到Meta更多的应用程序中。
编译:南都记者杨博雯



















暂无评论内容