
虽然最近关于根据文本提示生成 3D点云的工作已经显示出可喜的结果,但最先进的方法通常需要多个 GPU 小时来生成单个样本。这与最先进的生成图像模型形成鲜明对比,后者在几秒或几分钟内生成样本。在本文中,我们探索了一种用于生成 3D 对象的替代方法,该方法仅需 1-2 分钟即可在单个 GPU 上生成 3D 模型。我们的方法首先使用文本到图像的扩散模型生成单个合成视图,然后使用以生成的图像为条件的第二个扩散模型生成 3D 点云。虽然我们的方法在样本质量方面仍未达到最先进的水平,但它的采样速度要快一到两个数量级,为某些用例提供了实际的权衡。我们在https://github.com/openai/point-e 上发布了我们预训练的点云扩散模型,以及评估代码和模型。
Date:2023-2-9
作者:Z
公众号:【3D视觉工坊】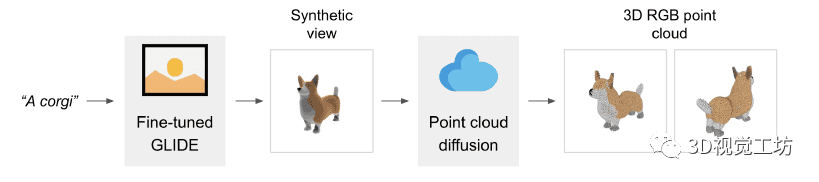
背景介绍


简介
我们不是训练单个生成模型直接生成以文本为条件的点云,而是将生成过程分为三个步骤。首先,我们生成一个以文本标题为条件的综合视图。接下来,我们生成一个基于合成视图的粗略点云(1,024 个点)。最后,我们生成了一个以低分辨率点云和合成视图为条件的精细点云(4,096 个点)。在实践中,我们假设图像包含来自文本的相关信息,并且不明确地以文本为条件点云。
1、数据集
我们在数百万个 3D 模型上训练我们的模型。我们发现数据集的数据格式和质量差异很大,促使我们开发各种后处理步骤以确保更高的数据质量。为了将我们所有的数据转换为一种通用格式,我们使用 Blender(Community,2018)从 20 个随机摄像机角度将每个 3D 模型渲染为 RGBAD 图像,Blender 支持多种 3D 格式并带有优化的渲染引擎。对于每个模型,我们的 Blender 脚本将模型标准化为边界立方体,配置标准照明设置,最后使用 Blender 的内置实时渲染引擎导出 RGBAD 图像。然后,我们使用渲染将每个对象转换为彩色点云。特别地,我们首先通过计算每个 RGBAD 图像中每个像素的点来为每个对象构建一个稠密点云。这些点云通常包含数十万个不均匀分布的点,因此我们还使用最远点采样来创建均匀的 4K 点云。通过直接从渲染构建点云,我们能够避免尝试直接从 3D 网格采样点时可能出现的各种问题,例如模型中包含的采样点或处理以不寻常文件格式存储的 3D 模型 。最后,我们采用各种启发式方法来减少数据集中低质量模型的出现频率。首先,我们通过计算每个点云的 SVD 来消除平面对象,只保留那些最小奇异值高于某个阈值的对象。接下来,我们通过 CLIP 特征对数据集进行聚类(对于每个对象,我们对所有渲染的特征进行平均)。我们发现一些集群包含许多低质量的模型类别,而其他集群则显得更加多样化或可解释。我们将这些集群分到几个不同质量的容器中,并使用所得容器的加权混合作为我们的最终数据集。
2、查看合成 GLIDE 模型
本文的点云模型以文中数据集的渲染视图为条件,这些视图都是使用相同的渲染器和照明设置生成的。因此,为了确保这些模型正确处理生成的合成视图,我们的目标是显式生成与数据集分布相匹配的 3D 渲染。为此,我们微调了 GLIDE,混合了其原始的数据集和我们的 3D 渲染数据集。由于我们的 3D 数据集与原始 GLIDE 训练集相比较小,因此我们仅在 5% 的时间内从 3D 数据集中采样图像,其余 95% 使用原始数据集。我们对 100K 次迭代进行了微调,这意味着该模型已经在 3D 数据集上进行了多次迭代(但从未两次看到完全相同的渲染视点)。
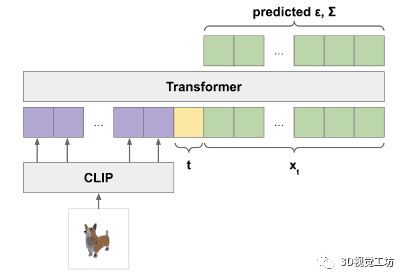
为了确保我们始终对分布渲染进行采样(而不是仅在 5% 的时间内对其进行采样),我们在每个 3D 渲染的文本提示中添加了一个特殊标记,表明它是 3D 渲染;然后我们在测试时使用此标记进行采样。
3、点云扩散

4、点云上采样
对于图像扩散模型,最好的质量通常是通过使用某种形式的层级结构来实现的,其中低分辨率基础模型产生输出,然后由另一个模型进行上采样。我们采用这种方法来生成点云,首先使用大型基础模型生成 1K 点,然后使用较小的上采样模型上采样到 4K 点。值得注意的是,我们模型的计算需求随点数的增加而增加,因此对于固定模型大小,生成 4K 点的成本是生成 1K 点的四倍。我们的上采样器使用与我们的基本模型相同的架构,为低分辨率点云提供额外的条件标记。为了达到 4K 点,上采样器以 1K 点为条件并生成额外的 3K 点,这些点被添加到低分辨率点云中。我们通过一个单独的线性嵌入层传递条件点,而不是用于xt的线性嵌入层,从而允许模型将条件信息与新点区分开来,而无需使用位置嵌入。
5、点云网格
对于基于渲染的评估,我们不直接渲染生成的点云。相反,我们将点云转换为带纹理的网格并使用 Blender 渲染这些网格。从点云生成网格是一个经过充分研究的问题,有时甚至是一个难题。我们的模型生成的点云通常有裂缝、异常值或其他类型的噪声,使问题特别具有挑战性。为此,我们简要尝试使用预训练的 SAP 模型(Peng 等人,2021 年),但发现生成的网格有时会丢失点云中存在的大部分形状或重要的形状细节。我们没有训练新的 SAP 模型,而是选择了一种更简单的方法。为了将点云转换为网格,我们使用基于回归的模型来预测给定点云的对象的符号距离场,然后将行进立方体 (Lorensen & Cline, 1987) 应用于生成的 SDF 以提取网格。然后,我们使用距离原始点云最近的点的颜色为网格的每个顶点分配颜色。
实验结果
由于通过文本条件合成3D是一个相当新的研究领域,因此还没有针对此任务的标准基准集。然而,其他几项工作使用 CLIP R-Precision 评估 3D 生成,我们在表 1 中与这些方法进行了比较。除了 CLIP R-Precision 之外,我们还注意到报告的每种方法的采样计算要求。
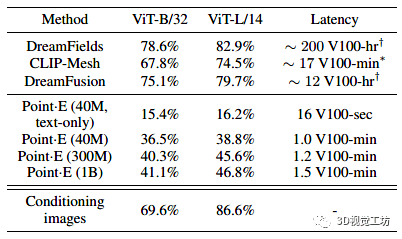
虽然我们的方法比当前最先进的方法表现要差些,但我们注意到此评估的两个微妙之处,它们可以解释部分(但可能不是全部)这种差异:
与 DreamFusion 等基于多视图优化的方法不同,Point E 不会明确优化每个视图以匹配文本提示。这可能会导致 CLIP R-Precision 降低,因为某些物体不容易从所有角度识别。我们的方法生成的点云必须在渲染前进行预处理。将点云转换为网格是一个难题,我们使用的方法有时会丢失点云本身中存在的信息。总结与展望
本文介绍了 Point E,一个用于从文本生成点云的方法,它首先生成合成视图,然后生成以这些视图为条件的彩色点云。我们发现 Point E 能够根据文本提示有效地生成多样化和复杂的 3D 形状。希望我们的方法可以作为文本到 3D这一块研究领域进一步工作的起点。
更多干货
欢迎加入【3D视觉工坊】交流群,为3D领域贡献自己的力量!欢迎大家一起交流成长~ 添加小助手微信:dddvisiona,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。

















暂无评论内容