
DALL·E的3D版来了,OpenAI提出Point·E,一个由复杂提示生成三维点云的系统
【写在前面】
虽然最近关于文本条件3D对象生成的工作已经显示出令人振奋的结果,但最先进的方法通常需要多个GPU小时来生成单个样本。这与最先进的生成图像模型形成了鲜明的对比,后者在几秒钟或几分钟内就能生成样本。在本文中,我们探索了一种替代的3D对象生成方法,该方法在单个GPU上仅需1-2分钟即可生成3D模型。我们的方法首先使用文本到图像的扩散模型生成单个合成视图,然后使用第二个扩散模型生成3D点云,该模型以生成的图像为条件。虽然我们的方法在样本质量方面仍然没有达到最先进的水平,但它的样本速度快了一到两个数量级,为一些用例提供了一个实用的权衡。
1. 论文和代码地址

论文题目:Point·E: A System for Generating 3D Point Clouds from Complex Prompts
论文地址:https://arxiv.org/abs/2212.08751
代码地址:https://github.com/openai/point-e
2. 动机
随着最近文本到图像生成模型的爆炸性发展,现在有可能在几秒钟内从自然语言描述生成和修改高质量的图像,受这些结果的启发,最近的作品探索了其他形式的文本条件生成,例如视频和3D对象。在这项工作中,我们特别关注文本到3D的生成问题,该问题具有使3D内容创建大众化的巨大潜力,适用于各种应用程序,例如虚拟现实、游戏和工业设计。
最近用于文本到3D合成的方法通常分为以下两类之一:
1、直接在成对(文本,3D)数据或未标记3D数据上训练生成模型的方法。虽然这些方法可以利用现有的生成性建模方法来高效地产生样本,但由于缺乏大规模3D数据集,它们很难扩展到多样化和复杂的文本提示。
2、利用预先训练的文本-图像模型来优化可区分3D表示的方法。这些方法通常能够处理复杂和多样化的文本提示,但需要昂贵的优化过程来生成每个样本。此外,由于缺乏强大的3D先验知识,这些方法可能会陷入与有意义或连贯的3D对象不对应的局部最小值。
我们的目标是通过将文本到图像的模型与图像到3D的模型配对来结合这两个类别的优点。我们的文本到图像模型利用了大量的(文本、图像)对语料库,允许它遵循各种复杂的提示,而我们的图像到3D模型是在(图像、3D)对的较小数据集上训练的。为了从文本提示生成3D对象,我们首先使用文本到图像模型对图像进行采样,然后对以采样图像为条件的3D对象进行采样。这两个步骤都可以在几秒钟内执行,并且不需要昂贵的优化程序。
3. 方法
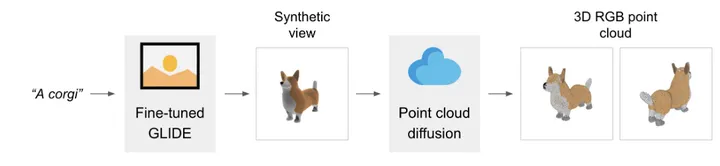
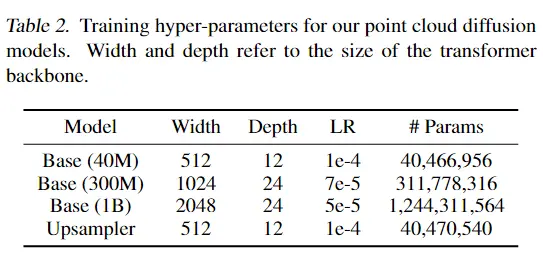
在文本生成3D点云上,Point·E并非“一步到位”,而是将过程分为了三步。
首先,模型会先基于文本生成一个“预览版视图”。
这一步基于OpenAI去年发布的30亿模型GLIDE微调实现,用它生成的视图还不具备“3D特性”,相当于只是给了个参考范例。
随后,如黄色框所展示的,Point·E会采用一个扩散模型,根据“预览版视图”生成一个粗糙的3D点云模型(这里的粗糙指分辨率较低,只有1024个点)。
具体架构如下:
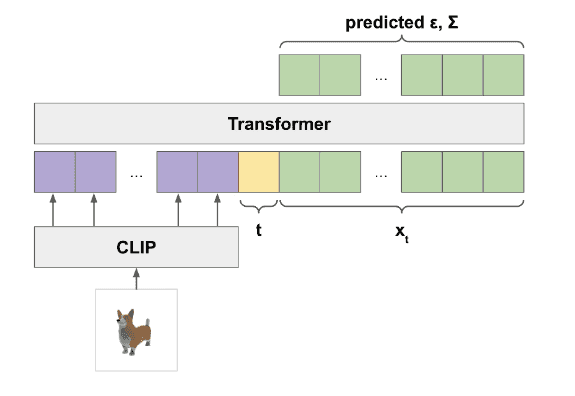
最后,再用一个更小的扩散模型,采用上采样(upsample)将获得的3D点云模型进一步细化,得到最终的精细版3D点云模型(一共有4096个点)。
具体的训练过程,用了一个包含数百万个3D模型的数据集,其中每个模型都被处理成渲染视图、文本描述和3D点云三部分。
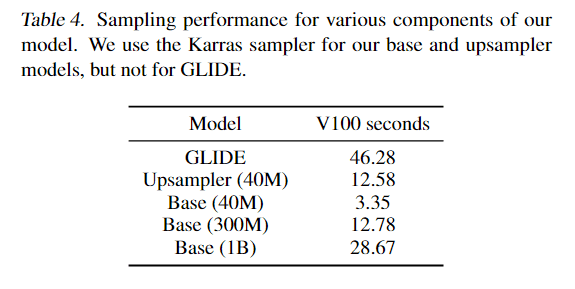
用这种方法生成的3D点云模型,在处理速度上确实快了不少。
4.实验
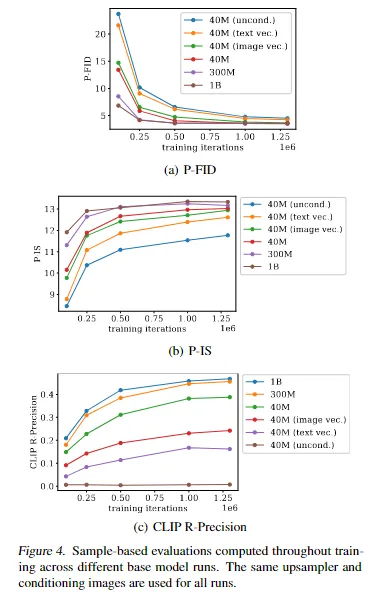

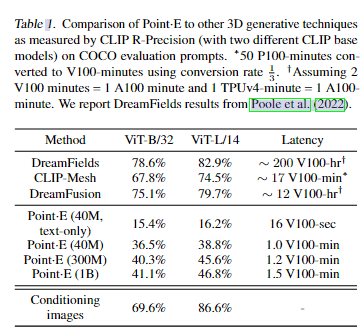


5. 总结
我们已经提出了Point·E,这是一个基于文本条件的3D点云合成系统,它首先生成合成视图,然后根据这些视图生成彩色点云。我们发现,Point·E能够高效地生成以文本提示为条件的各种复杂的3D形状。我们希望我们的方法可以作为文本到3D合成领域进一步工作的起点。
更多细节请参考原文!
[1]https://arxiv.org/abs/2212.08751: https://arxiv.org/abs/2212.08751
[2]https://github.com/openai/point-e: https://github.com/openai/point-e
本文由 mdnice 多平台发布


















暂无评论内容