
发表在SIGAI的翻译文章:
注:这是一篇2019年7月发表在arXiv的论文【1】,如题目所言是对激光雷达传感器的仿真建模,以生成3D点云数据。
摘要: 先进的传感器是实现自动驾驶汽车技术的关键。激光扫描仪传感器成为一种基本选择,因为它具有远距和低光驾驶条件的鲁棒性。自动驾驶汽车控制的软件设计是一个基于规则系统的复杂任务,因此最近的方法依赖于从数据学习这些规则的机器学习方法。这种方法的主要问题是推广机器学习模型所需的训练数据量很大,另一方面,与其他汽车传感器相比,激光雷达数据注释成本非常高。精确的激光雷达传感器模型可以应对这种问题。此外,现有的激光雷达开发、验证和评估平台和流程成本非常高,在物理属性表示方面虚拟测试和开发环境仍然不成熟。这项工作提出了一种新颖的基于深度学习的激光雷达传感器模型。该方法使用深度神经网络模拟传感器回波信号,用极坐标网格图(Polar Grid Maps,PGM)对从实际数据中学习的回波脉冲宽度进行建模。
1. 激光雷达
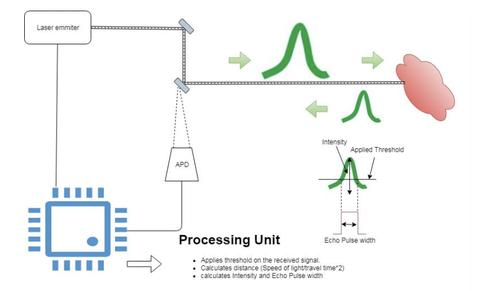
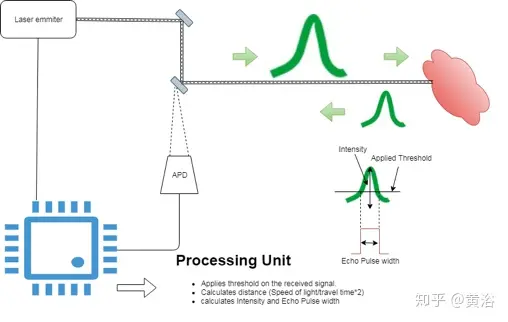
激光雷达传感器的基本元件是发射器、接收器(APD,雪崩光电二极管)和处理单元。 激光雷达传感器通过将光速乘以从发射器到接收器APD的脉冲行进时间的一半来测量距离。激光雷达处理单元对接收到的脉冲应用滤波器和取阈值,以区分噪声检测和有意义的检测。 同时,接收的激光雷达脉冲携带关于材料和检测到的目标反射性的信息。这些信息的表示,要么是检测到的反射强度,要么是检测到的反射回波脉冲宽度(EPW),取决于激光雷达处理单元在其字节流计算或返回什么,如图1是基本的激光雷达解剖。
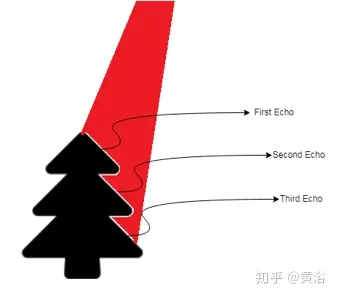
由于激光射线轮廓的划分导致多个回波,激光雷达传感器可以有来自相同脉冲的多次反射,如图2所示。
首先,实际激光雷达数据与本文传感器模型生成的合成数据做一下对比(左和右两个),如图3所示。 每个扫描点颜色代表其回波脉冲宽度(EPW)值。 很明显,两个例子都看出来:1)该方法明确地模拟了真实数据EPW值;2)该方法可以模拟远感知中句法生成数据中的噪声模型;3)该模型可以学习如何通过真实的痕迹来表示车道。

2. 模拟方法
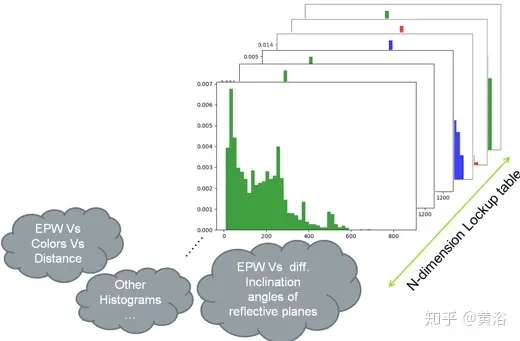
假设EPW值主要取决于目标材料、与传感器的距离以及激光束倾斜和偏航拍摄角度。因此这里采用两种直方图;一个用于每个回波和目标材料的EPW值,另一个是在不同的偏航射击角度下发生回声的概率。如图4所示的这种多维度直方图包含了EPW对上述依赖性的敏感度查找表,它与信号强度或衰减度、通过不同距离的噪声模型、不同目标和回波出现的分布信息等相关联。通常,传感器最多支持3个回波。
此外,这里提出了一种基于端到端深度学习的方法,可以学习从物理环境设置到激光雷达数据物理属性的复杂函数映射。整个架构是两步DNN:首先是全卷积DNN,基于极坐标网格图(PGM)方法推断EPW值;其次是许多选择块的一种,对每个回波的模拟射线轮廓,选择其许多离散信号射线轮廓中的一个离散表示,并从该选择中得到噪声模型的表示,如图5所示。
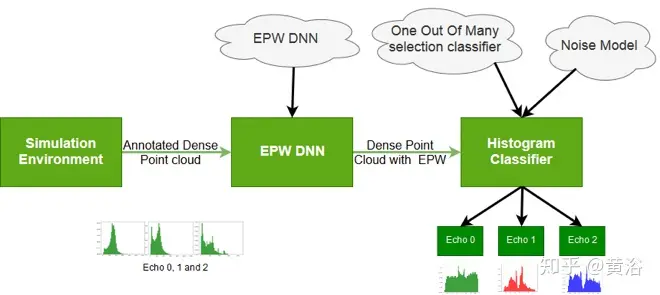
极坐标网格图(PGM)是3D张量中的激光雷达全扫描的表示。全扫描由在PGM中编码的扫描点云组成。PGM的每个通道是2D网格图,其中每行表示水平激光雷达层。将传感器作为参考点,每个扫描点由与此参考点的距离以及方位角和高度角确定。
每个PGM单元对应于扫描点,行和列的索引分别表示扫描点高度和方位角。单元格值表示相应扫描点的信息。在第一个PGM通道,该值保持扫描点距离,而第二个通道保持其类别。 可以通过添加额外的通道来扩展表示更多信息。如图6是来自单个激光雷达全扫描的PGM表示示意图(上部是深度表示,下部是点标注)。


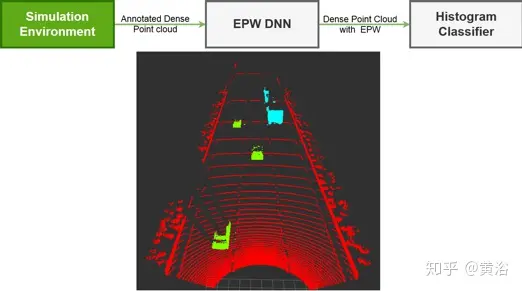
来自模拟环境的输入是密集的标注点云,密集点云代表激光射线轮廓的离散表示,如图7所示。
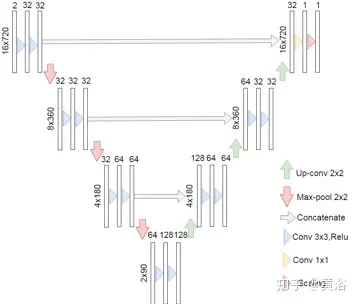
采用著名的U-Net模型【2】来处理两个通道的输入数据,并减少了块数以满足合理的运行时间限制。对于每次完整扫描,相应的PGM用作网络的输入。然后,通过一个三个下采样块组成的编码器,每个块有2个卷积层,3×3内核,后面是最大池化层。 接着,输出经过三个上采样块,每个块有2个卷积层,3×3内核,接着是转置卷积层。 采用U-Net的收缩路径或跳连接来捕获激光雷达数据的上下文。 网络输出表示1个通道的PGM,它保存了输入全扫描的EPW信息。如图8是U-Net架构图。
损失函数定义如下:
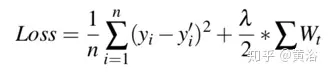
而EPW DNN输出的是与其推断的EPW相同的标注点云,如图9所示。

EPW训练采用350个时期(epoch),根据L1分数可提前停止,微批量大小是8个样本,学习率为1e-5,标注类别是{无(None),汽车,卡车,行人,摩托车,高反光材料}。
将密集点云传递给直方图分类器(Histogram classifier),从多个点选择方法中选择一个,从密集点云中选择使扫描点看起来更像真实激光雷达传感器模型中的那种逼真扫描点,如图10所示。
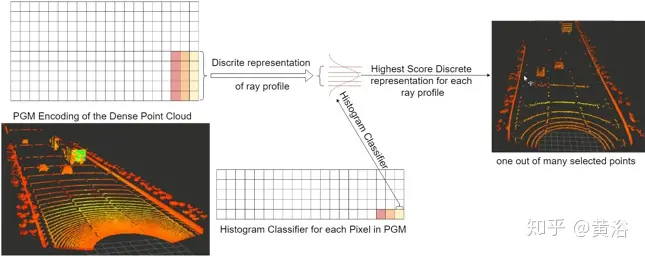
3. 实验结果
激光雷达是一个16层传感器±5°,垂直分辨率为0.625°,水平视场角为145°,分辨率为0.125°。 传感器为每个反射的射线投射提供三个回波,可以根据目标的反射率、几何形状和来自另一个目标的反射为每个反射提供一个、两个或三个扫描点,用于分割的激光雷达射线轮廓。每个反射扫描点携带反射扫描点的两个信息,深度和回波脉冲宽度。
数据集是30k帧,帧速率为25Hz,分为两条主要轨迹,第一条记录轨迹是20k帧,一条道路用于训练DNN,第二条记录轨迹是10k帧,另一条道路用于验证DNN;在合成数据中,使用了来自Carmaker,Gazebo和Unity仿真环境的不同数据。
提出的传感器模型的主要优点之一是用可测量的测度来评估输出,观察其与现实传感器模型的接近度,但是这是一个巨大挑战,因为在模拟环境中没有GT,这样只能使用统计评估指标,并将评估KPI分为两组,第一个真实-对-真实,第二个真实-对-模拟。
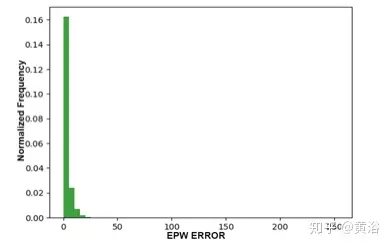
评估的最大问题是关联属性,和参考相关联的是实际数据,以及来自不同模拟环境的数据,这两种数据类型的性质是不同的。解决这个问题的唯一方法是使用无监督评估技术。如图11 是推断的EPW误差直方图。
基于不同DNN架构进行实现,它们的执行时间和性能都作为基准标记,结果如下表:
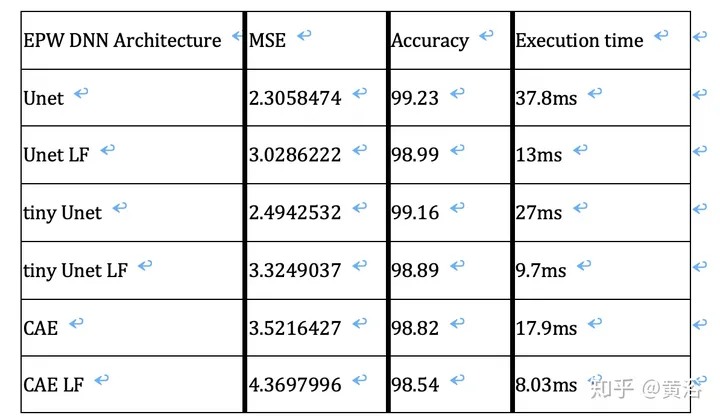
其中Unet是上面提出的体系结构,Unet LF是相同的体系结构,但每个卷积过程的内核数量只有一半,tiny Unet是相同的Unet体系结构,但每个Unet块只有一个卷积过程而不是两个卷积过程,tiny Unet LF与tiny Unet相同,但每个卷积过程的内核数量只有一半,CAE是一个简单的卷积自动编码器,编码器是3个下采样卷积,解码器是3个上采样卷积,CAE LF与CAE的架构相同,但每个卷积过程的内核数量只有一半。如果需要准确度,Unet架构将是选择,但是如果可以使用目标CAE LF架构更快的执行时间,并且在良好的执行时间和良好的准确性之间,Tiny Unet LF将是选择。
提出的方法,其最佳附加值之一是作为任何模拟环境的插件,将带标注的点云作为输入,并通过它的噪声模型和不同的物理属性返回扫描点感知。 Carmaker,Unity和Gazebo的演示分别如图12,图13和图14所示。


4. 今后的工作
未来的工作,计划在直方图分类器中使用其他方法,如时域分辨信号建模,并融合这些输出而不只是所有选择块的一个。此外,激光雷达和相机的融合可以为扫描点提供颜色信息,如图15所示。这可以为EPW DNN和直方图分类器提供激光雷达物理特性与每个类别和材料的目标颜色之间的关系。

参考文献
1. K Elmadawi et al., “End-to-end sensor modeling for LiDAR Point Cloud”,arXiv 1907.07748v1,2019,7
2. O. Ronneberger, P. Fischer, T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” International Conference on Medical image computing and computer-assisted intervention. Springer, 2015.

















暂无评论内容