现在,万事俱备了,可以准备训练我们自己的全卷积结构的YOLOv1。
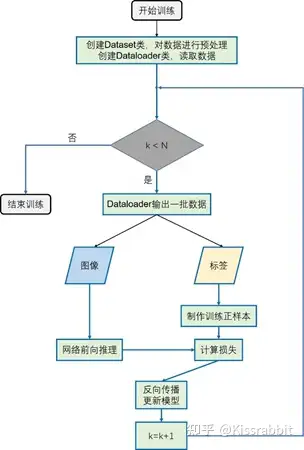
图1 训练流程
整个训练流程如图1所示,读者可以根据该流程图所展示的训练过程来编写相应的训练代码。这里,我们展示出来训练部分的主要代码,如下方的代码所示:
def train():
# 创建命令行参数
args = parse_args()
print(“Setting Arguments.. : “, args)
print(“———————————————————-“)
# 保存模型的路径
path_to_save = os.path.join(args.save_folder, args.dataset, args.version)
os.makedirs(path_to_save, exist_ok=True)
# 是否使用cuda来训练
if args.cuda:
print(use cuda)
cudnn.benchmark = True
device = torch.device(“cuda”)
else:
device = torch.device(“cpu”)
# 是否使用多尺度训练技巧
if args.multi_scale:
print(use the multi-scale trick …)
train_size = 640
val_size = 416
else:
train_size = 416
val_size = 416
# 训练所使用到的配置参数
cfg = train_cfg
# 创建dataset类和dataloader类
if args.dataset == voc:
# 加载VOC数据集
data_dir = VOC_ROOT
num_classes = 20
dataset = VOCDetection(root=data_dir,
transform=SSDAugmentation(train_size)
)
evaluator = VOCAPIEvaluator(data_root=data_dir,
img_size=val_size,
device=device,
transform=BaseTransform(val_size),
labelmap=VOC_CLASSES
)
elif args.dataset == coco:
# 加载COCO数据集
data_dir = coco_root
num_classes = 80
dataset = COCODataset(
data_dir=data_dir,
img_size=train_size,
transform=SSDAugmentation(train_size),
debug=args.debug
)
evaluator = COCOAPIEvaluator(
data_dir=data_dir,
img_size=val_size,
device=device,
transform=BaseTransform(val_size)
)
else:
print(unknow dataset !! Only support voc and coco !!)
exit(0)
print(Training model on:, dataset.name)
print(The dataset size:, len(dataset))
print(“———————————————————-“)
# dataloader类
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=True,
collate_fn=detection_collate,
num_workers=args.num_workers,
pin_memory=True
)
# 创建我们的模型
if args.version == yolo:
from models.yolo import myYOLO
yolo_net = myYOLO(device=device,
input_size=train_size,
num_classes=num_classes,
trainable=True)
print(Let us train yolo on the %s dataset …… % (args.dataset))
else:
print(We only support YOLO !!!)
exit()
model = yolo_net
model.to(device).train()
# 是否使用tensorboard来保存训练过程中的各类数据
if args.tfboard:
print(use tensorboard)
from torch.utils.tensorboard import SummaryWriter
c_time = time.strftime(%Y-%m-%d %H:%M:%S,time.localtime(time.time()))
log_path = os.path.join(log/coco/, args.version, c_time)
os.makedirs(log_path, exist_ok=True)
writer = SummaryWriter(log_path)
if args.resume is not None:
print(keep training model: %s % (args.resume))
model.load_state_dict(torch.load(args.resume, map_location=device))
# 构建训练所使用的优化器
base_lr = args.lr
tmp_lr = base_lr
optimizer = optim.SGD(model.parameters(),
lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay
)
max_epoch = cfg[max_epoch] # 最大训练轮次
epoch_size = len(dataset) // args.batch_size # 每一训练轮次的迭代次数
# 开始训练
for epoch in range(args.start_epoch, max_epoch):
# 使用阶梯式学习衰减策略
if epoch in cfg[lr_epoch]:
tmp_lr = tmp_lr * 0.1
set_lr(optimizer, tmp_lr)
# 获取一批数据
for iter_i, (images, targets) in enumerate(dataloader):
ni = iter_i+epoch*epoch_size
# 使用warm-up策略来调整早期的学习率
if not args.no_warm_up:
if epoch < args.wp_epoch:
nw = args.wp_epoch*epoch_size
tmp_lr = base_lr * pow((ni)*1. / (nw), 4)
set_lr(optimizer, tmp_lr)
elif epoch == args.wp_epoch and iter_i == 0:
tmp_lr = base_lr
set_lr(optimizer, tmp_lr)
#多尺度训练
if iter_i % 10 == 0 and iter_i > 0 and args.multi_scale:
# 随机选择一个新的训练尺寸
train_size = random.randint(10, 19) * 32
model.set_grid(train_size)
if args.multi_scale:
# 插值
images = torch.nn.functional.interpolate(images,
size=train_size,
mode=bilinear,
align_corners=False
)
# 制作训练标签
targets = [label.tolist() for label in targets]
targets = tools.gt_creator(input_size=train_size,
stride=yolo_net.stride,
label_lists=targets
)
# to device
images = images.to(device)
targets = targets.to(device)
# 前向推理,计算损失
conf_loss, cls_loss, bbox_loss, total_loss = model(images, target=targets)
# 梯度累加 & 反向传播
total_loss /= args.accumulate
total_loss.backward()
# 更新
if ni % args.accumulate == 0:
optimizer.step()
optimizer.zero_grad()
# 验证模型的性能
if (epoch + 1) % args.eval_epoch == 0:
model.trainable = False
model.set_grid(val_size)
model.eval()
# evaluate
evaluator.evaluate(model)
# convert to training mode.
model.trainable = True
model.set_grid(train_size)
model.train()
# 保存模型
if (epoch + 1) % 10 == 0:
print(Saving state, epoch:, epoch + 1)
torch.save(model.state_dict(), os.path.join(path_to_save,
args.version + _ + repr(epoch + 1) + .pth)
)
更完整的训练代码还请读者打开我的YOLOv1项目的train.py文件来查看。(相信看到这里的读者都已经下载了项目,若是还没有现在,请回到序言章节,找到代码链接。)
在训练代码中,读者会看到COCO数据集的dataset类的构建,由于我们目前只讲解了VOC数据集,尚未提及COCO数据集,因此COCO数据集这一块暂不做过多的介绍。感兴趣的读者可以自行跳到COCO数据集的代码去查看我们的项目是如何获取COCO数据的,相应代码在data/cocodataset.py文件中。
在后续的章节中,我们也会使用COCO数据集,毕竟这是当前目标检测领域中的最常用的数据集,大多数工作都会在这一数据集上去验证自己工作的有效性和先进性。然而,前面已说过,COCO数据集过于庞大,训练时间非常得长,尽管在目标检测领域,COCO是研究者们互相“切磋”的主要数据集,但目前我们主要是以“入门”为主,就这一目的而言,暂时使用VOC数据便足够了。数据集不过是训练模型的“食物”而已,如同吃饭,重点不在于先学会 “吃哪样的米饭”,而是要先学会“如何吃米饭”。
另外,细心的读者一定注意到了代码中的“多尺度训练”技巧,代码图下所示,代码实现参考了YOLOv5:
#多尺度训练
if iter_i % 10 == 0 and iter_i > 0 and args.multi_scale:
# 随机选择一个新的训练尺寸
train_size = random.randint(10, 19) * 32
model.set_grid(train_size)
if args.multi_scale:
# 插值
images = torch.nn.functional.interpolate(images,
size=train_size,
mode=bilinear,
align_corners=False)
所谓的多尺度训练技巧,即在训练过程中,不断随机改变输入图像的大小,图像大小改变了,那图像中的物体大小也会跟着发生变化,其目的就是让模型能够见到更多尺度的物体,缓解模型对尺度变化不敏感的问题。其实,这一点和常用的尺度缩放的数据增强是一个性质。
这里,我们借鉴了YOLOv2工作给出的多尺度配置,每训练10次,就随机从{320,352,384,416,448,480,512,544,576,608}中抽取一个新的尺寸,用做接下来训练中的图像尺寸。我们只需要在命令行中传入“-ms”参数即可调用多尺度训练技巧。具体来说,训练时开启了多尺度训练技巧,那么dataloader给出的图像尺寸都会设置为640×640,然后使用双线性插值的方法去resize图像的尺寸,得到不同尺度的图像。
开始训练时,请读者先打开电脑的终端(建议使用ubuntu系统,当然,win10也是支持的),进入项目文件夹下,输入下面一行命令即可运行训练文件:
python train.py –cuda -d voc -bs 16 -accu 4 -ms
简单介绍一下这些参数的意义:
–cuda表示我们调用GPU来训练模型,切记,一定要输入“–cuda”,否则程序只调用CPU来训练,那将是个极其漫长的训练过程;-d voc表示我们使用VOC数据集来训练YOLO,若读者准备好了COCO数据集,可以将其改成-d coco即可;-bs 16表示训练期间的batch size为16;读者可以根据自己的GPU显存来修改,如-bs 8或者-bs 32等;-accu 4表示我们累计四次梯度再反向传播,假如batch size为16,那我们累计4次再传向传播的话,相当于batch size为16×4=64;这里建议读者保持-bs x -accu = 64 的配置,比如,读者设置-bs 8,那么就要相应地设置-accu 8,以确保二者的乘积为64,这里建议乘积不要小于32;-ms表示我们是哟个多尺度训练技巧。
由于我们的loss是在batch维度上做归一化的,所以为了保证梯度累加的等效性,我们需要对计算出来的总的损失total_loss做平均:
# 梯度累加 & 反向传播
total_loss /= args.accumulate
total_loss.backward()
更多的命令行参数,还请读者打开train.py代码文件详细阅读。
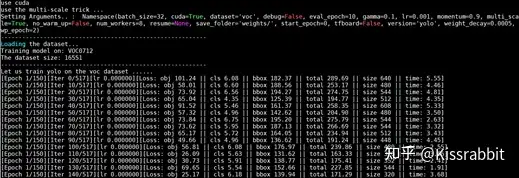
训练过程中,读者将会在终端下看到如图2的输出,在训练的初期,由于默认使用warmup策略,因此损失下降的会较慢。
图2 VOC数据集上的训练输出
warmup的作用在于可以缓解模型在训练初期由于尚未学到足够好的参数而回传不稳定的梯度所导致的负面影响,就如同游泳时,我们不做任何热身运动直接扎进水池里,容易出现手脚抽筋的现象。热热身,则可以在很大的程度上避免这一问题。因此,还请读者耐心等待warmup阶段过去。
通常,训练会花费至少两个小时的时间(取决于读者所使用的显卡设备),这期间一旦终端被关闭,则训练就被迫中止了,这不是我们想要看到的结果。因此,读者可以在输入训练指令时,可以使用nohup命令,将程序放到后台去训练,即便终端被关闭,也不会影响我们的训练,命令如下:
nohup python train.py –cuda -d voc -bs 16 -accu 4 -ms 1>1.txt 2>2.txt &
在ubuntu下(建议使用ubuntu环境),nohup指令可以将程序放到后台去运行,即便终端被关闭,也不会造成运行的程序被终止的问题。在上面一行的命令中,“1>1.txt”表示程序会将有效输出信息(程序正常运行时所输出的信息)存放在1.txt文件中,读者也可以将其换个名字,比如1-voc.txt,用1.txt这个名字只是笔者的个人习惯。而“2>2.txt”是将程序执行过程中的警告信息和报错信息存放到2.txt文件中。当后台程序报错导致终止,读者可以打开2.txt文件来查看程序报出的错误,以便进行debug。
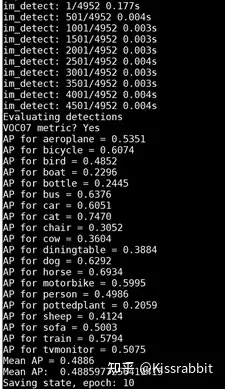
读者可以在终端下使用cat命令来查看已写入文件1.txt中的训练输出信息。训练过程中,默认每训练10个轮次(epoch),模型便会在VOC 2007 test测试集上进行一次测试。读者将会看到如图3的输出。输出的信息是我们的当前训练的模型在VOC2007测试集上的mAP指标,默认每10个轮次保存一次模型。
图3 训练过程中的测试输出
至此,我们讲完了训练部分的干货,条件允许的读者可以开始在自己的机器上训练自己的YOLOv1模型啦。下一周,我们再讲有关于可视化检测结果和测试模型的mAP的内容。敬请期待。
(干货如此充足,真的不给个赞赏吗?嘤嘤嘤)



















暂无评论内容