
AIGC领域大火的stable diffusion模型由文本编码器,图像信息生成器,图像解码器三部分组成(JayAlammar博客)。

首先对这三部分模型分别进行分析,然后介绍一下inference sample的代码流程和用tensorRT进行加速的一些研究。
文本模型
文本编码器是一种Transformer语言模型,作为语言理解组件,接收文本提示,生成词嵌入。发布的Stable Diffusion模型使用ClipText(基于GPT的模型),而论文中使用BERT。
要了解Text Encoder,首先简单介绍一下CLIP这个模型。该模型的训练集由 4 亿张图像及其描述组成,训练时分别对图像和文本进行编码,然后,使用余弦相似度比较生成的嵌入。通过训练最终使编码器能够生成图像和描述相似的嵌入。总结起来如下图所示:
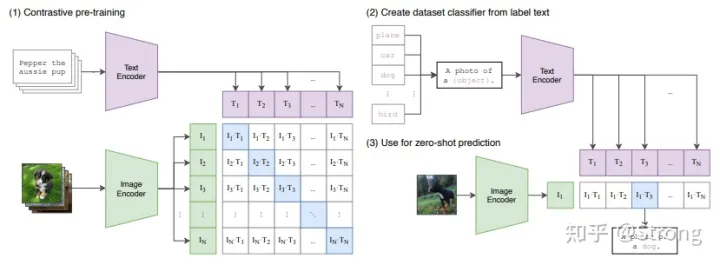
可以看出图中标蓝色的矩阵对角线都是正样本,其他的就是负样本。实际推理预测的时候,新的图像来了,经过image encoder得到图片嵌入向量,将该向量和所有label文本生成的嵌入向量求一个softmax就可以得到该图片分属于哪一个label文本,从而完成该图片的分类。整体过程还是比较简单清晰的。
stable diffusion中使用的就是clip的text encoder部分,原始的clip是采用GPT-2模型来完成这个任务。注意,GPT-2模型由transformer的decoder模块堆叠而成,但是和标准transformer中的结构又有些不同之处:

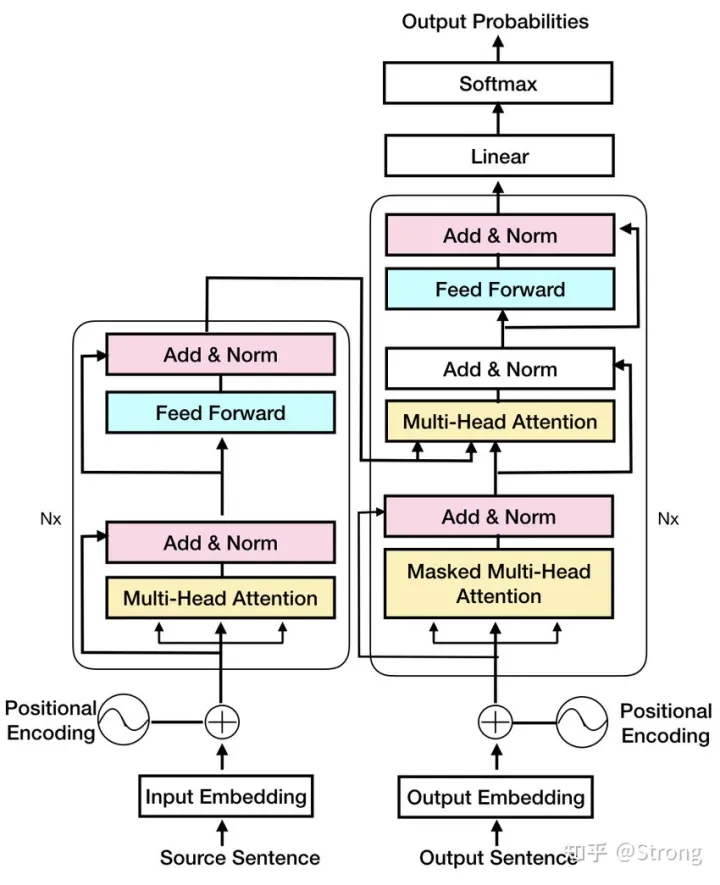
可以看到,GPT中的decoder和标准decoder相比,是没有第二个multi-head attention模块的(也可以叫做encode-decode cross attention)。
总结起来,GPT-2是这样一个过程,首先通过该单词的id去token embeddings字典中去查询对应的嵌入向量,接着通过该单词的position去positional字典中去查询对应的嵌入向量,然后把两个向量相加,送入第一层decoder,接着第二层,第三层。。。一般最小的GPT-2有12层decoder,做完第12层,还是得到一个嵌入向量,用它与token embeddings字典相乘,得到长度为字典长度的一个序列,接着进行softmax取到一个最大分数的单词。接着进行下一个单词的处理。
至于masked self-attention的概念,是说在每个单词计算qxk的时候,需要和其他单词计算相关分数,它只和它前面的单词产生关系,后面的单词都被掩盖住了。比如当前处理的是第10个单词(这个句子长度为20),那么它的q是1×768这样一个向量,它会和它自己的k和前面9个单词的k相乘(k也是1×768的向量),得到10个分数,而后面10个单词它是不去处理的。然后再和前面9个单词的v向量相乘,得到10个v,再累加得到z。注意,前面单词的k和v向量,并不是处理第10个单词的时候计算出来的,而是在前面的单词处理过程中缓存住的。

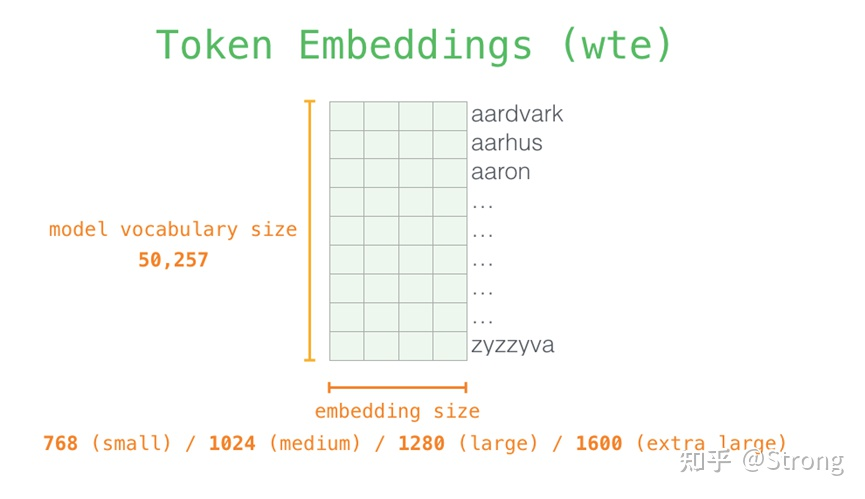
其中,token embeddings一般是一个比较大的词典:
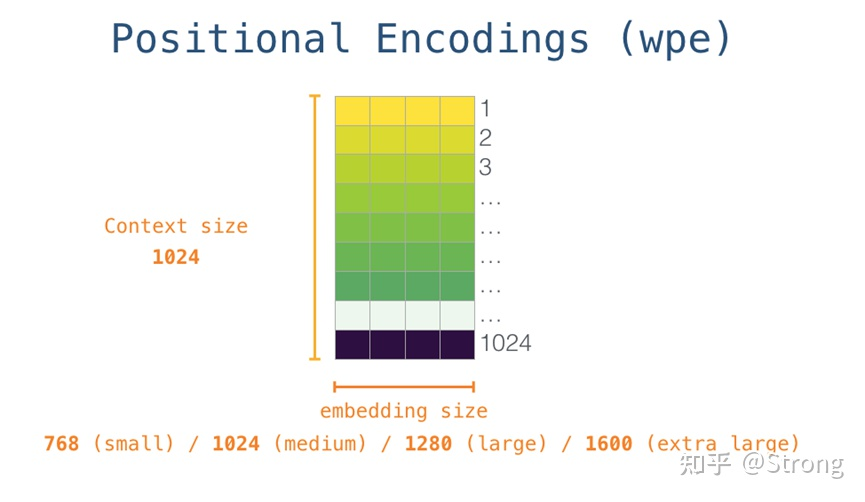
Position embedding是一个长度为1024的词典:
cliptextmodel参数量计算(以hugging face的diffusers工程为例,长度为77,hidden-size 768, 12层decoder):
token_embedding: 49408×768
position_embedding: 77×768
每层k weight:768×768 bias:1×768
每层q weight:768×768 bias:1×768
每层v weight:768×768 bias:1×768
每层 out weight:768×768 bias:1×768
每层layer_norm0 weight: 1×768 bias:1×768
每层 ffn0 weight:3072×768 bias:1×3072
每层 ffn1 weight:768×3072 bias:1×768
每层layer_norm1 weight: 1×768 bias:1×768
汇总:
以float32来计算,参数量大概是 123059712×4/1024/1024 = 469M Byte。其中,字典占了144M,decoder参数占了324M。至于clip论文中说用的text模型是63M个参数,我觉得应该是因为它用的hidden size为512导致。
模型可以按照diffuers工程的guide下载
下载模型之前需先安装git lfs
下载的模型中有每个部分的模型ckpt,.bin文件可以用netron工具进行可视化

Image Creator
前向过程
Creator代表扩散模型的反向过程。这里,我们先了解以下扩散模型的前向过程。所谓前向过程,即往图片上加噪声的过程。考虑向一个从真实数据分布中随机采样的变量添加噪声,添加T次之后,会得到一个长度为T的序列,随着T的增大,原始数据会丢失它的特征而变成一个纯的高斯噪声。
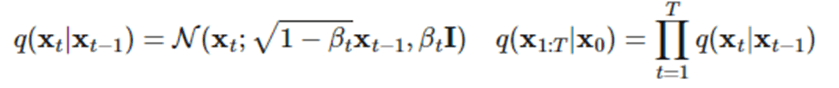
在这个过程中,每个时刻t只与t-1时刻有关,所以可以看作一个马尔可夫过程。
虽然xt只与xt-1相关,但是通过独立高斯分布性质和重参数化技巧,经过推导,可以得到一个xt关于x0的关系:

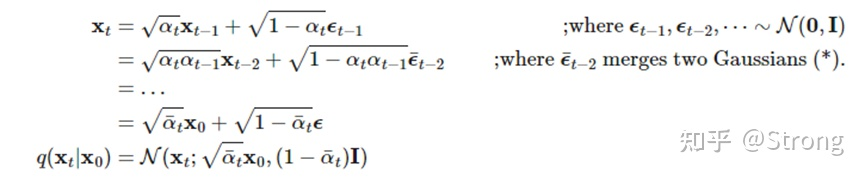
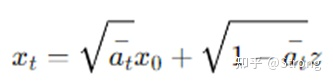
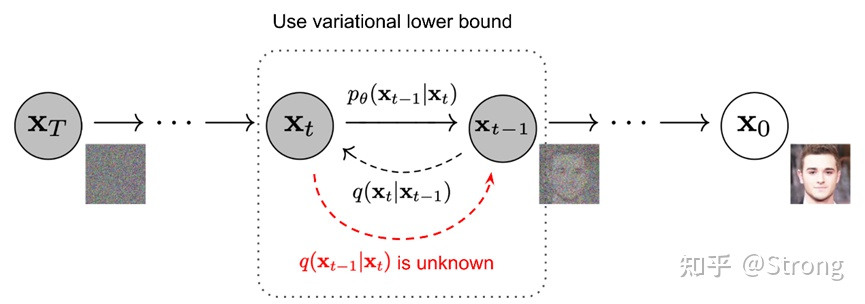
反向过程
反向过程就是去噪的过程。知道xt来计算xt-1。但是我们对于q(xt-1|xt)是不知道的,最好是可以通过推导,得到一个xt-1关于xt的关系。通过贝叶斯法则,可以推导:
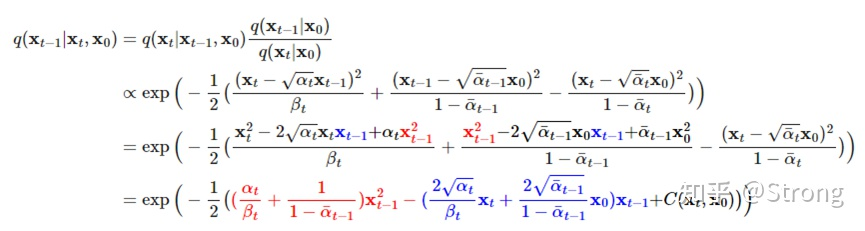
可以看到,经过推导变成了我们正向过程中已经可以表达的关系。但是反向过程中我们对于x0也是不知道的。但根据正向中xt与x0的关系,我们可以把x0进行替换,最终得到只与xt和一个未知的ε的关系:
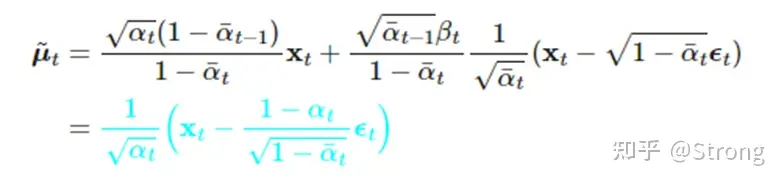
至于这个未知的ε,使用深度学习模型(unet,或者最新的DiT论文中用transformer模块来替代unet)来进行预测。
总结起来,creator的每一步推断就是执行下面的算法流程:
1)使用深度学习模型(unet),通过xt和t来预测高斯噪声zθ(xt,t),然后根据公式计算均值和方差:
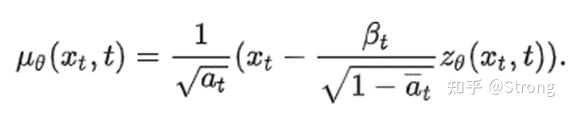
2) 根据公式得到p(xt-1|xt):
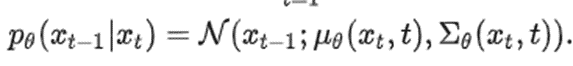
3)利用重参数化得到xt-1,重参数化可表示为可求导的分布随机采样。
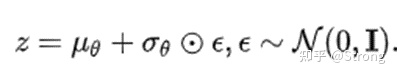
其中⊙表示element-wise乘。
代码流程
对应到hugging face工程中的代码,上述计算xt-1的过程就是不同的scheduler,stable diffusion pipeline中支持三种scheduler,分别为:
PNDM scheduler (used by default)
DDIM scheduler
K-LMS scheduler
以DDIM为例,计算xt-1的公式和上述介绍有些不同,但是大体都是类似的:
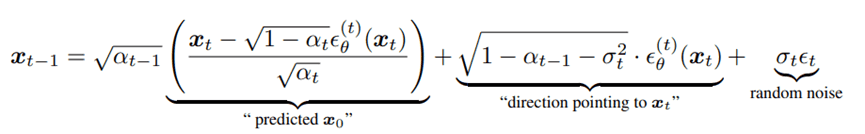
在代码中,其中的εθ(t)就是unet的输出,xt就是latent(即当前iter的整体输入)。截取scheduler中step的一小段:

可以看到就是在计算公式的第一部分x0。
Hugging face中代码整体流程可以用这个图来表示(注意scheduler的过程,其实就是每次unet之后都要执行一次,得到latent。从上述理论推导可以看出,scheduler才是扩散模型的核心,unet只用用来在每次计算xt-1时的一个预测噪声计算步骤中需要的,但是计算量的大头都在这个unet上):
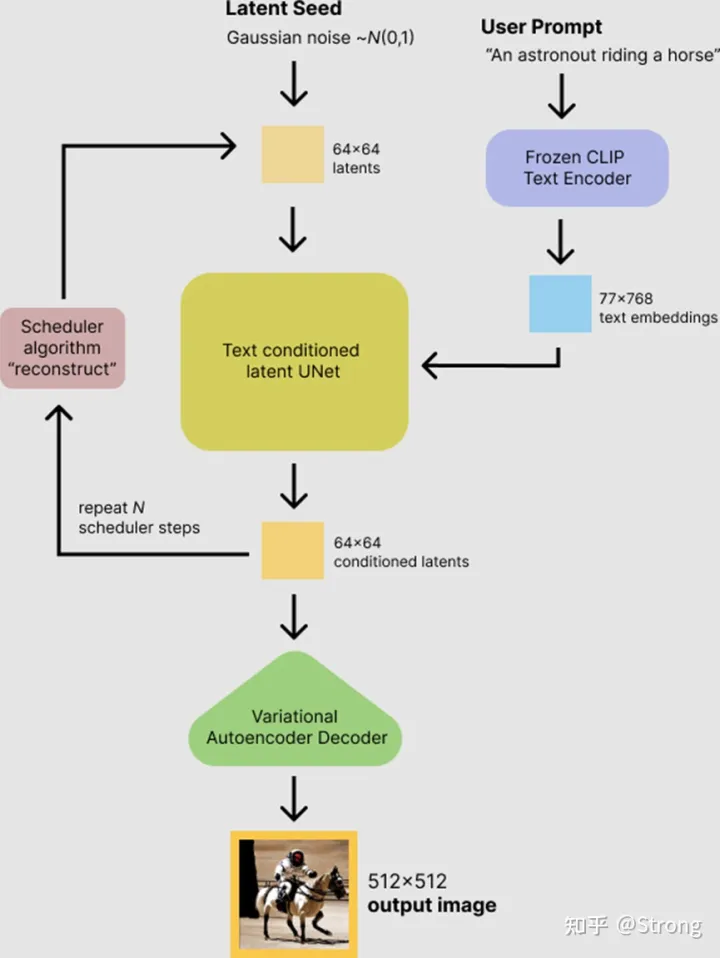
执行流程
公式表达和推导比较繁琐,参考jay的blog,用形象的图文再来介绍一下creator的过程。
Creator发生在多个步骤中,每个步骤都对输入的隐信息进行操作,生成另一个隐信息。生成的隐信息蕴含输入文本信息以及模型从图像训练集获得的视觉信息的融合信息。
可视化一组隐信息状态,查看每个步骤信息变化
Unet是一个噪声预测器:
输入图像中减去预测出的噪声,会得到接近模型训练数据的图像。
Decoder:
在推理时,这部分使用了VAE中的decoder模块,本质上就是把latent复原成图片,中间包含conv和upsample操作
Inference Example
首先下载预训练模型,三部分,分别对应clip unet vae,注意clip分为token和encoder两个模块。
选择scheduler:
设置参数:
文本编码:
产生随机latents(输入给unet的第一个iter),注意这里就是stable diffusion速度快的特殊原因,不是原始图片宽高,而是在一个低维空间中预测(512×512 -> 64×64):
计算每一个iter中的scheduler使用的参数,比如sigma等:
Unet+scheduler主循环:
Vae decode成正常图片:
显示和存储(原始image输出数据范围是-1,1, 变为0,1正常显示):
TensorRT模型加速
目前对于扩散模型推理来说,耗时是一个比较大的问题,一般生成一张图片要几十秒对用户来说是很不友好的。网上有一些加速方案,我们选取了运用tensorRT进行加速的一个案例来进行说明。
首先工程对执行时间进行了统计(没有统计文本模型部分,只有image creator+vae decoder,硬件为Nvidia-A10,去噪执行100个iteration):
可以看到主要耗时在unet部分,所以只对unet进行了tensorrt的加速。
为了复用整体的python pipeline代码,是需要按照pytorch跑模型的方式执行inference。所以通过把模型导出,然后在tensorrt的sample中跑的这条路径就不能用。但是怎样在pytorch模型inference中执行tensorrt后端呢?
一个比较好的方法就是Torch-TensorRT。这里简单介绍一下Torch-TensorRT这个工程,它的目的是为pytorch提供一个tensorrt推理后端,让pytorch用户无感的在模型inference中使用TensorRT的特性。它充当TorchScript的扩展。它优化并执行兼容的子图,让 PyTorch 执行其余的图。PyTorch的全面而灵活的功能集与Torch- TensorRT 一起使用,Torch- TensorRT 解析模型并对图中与TensorRT兼容的部分应用优化。编译后,使用优化的图形就像运行 TorchScript 模块,用户可以获得更好的 TensorRT 性能。
当执行编译后的模块时, Torch- TensorRT 会将引擎设置为活动并准备好执行。当您执行这个修改后的 TorchScript 模块时, TorchScript 解释器调用 TensorRT 引擎并传递所有输入。引擎运行并将结果推回解释器,就像它是正常的 TorchScript 模块一样。
对于unet的加速,分为以下几个步骤:
首先将模型转换为onnx:
接着将onnx模型转换为tensorRT engine格式:
接着把engine转换为torchscript模式:
接着修改原始pipeline代码,把unet创建过程改为load这个torchscript
模型执行的时候也要做一些小的修改:
经测试,发现时间减少了大约25%:



















暂无评论内容