

阅读文本大概需要 9 分钟。
之前的两篇文章

分别讲了 shuffle 的参数调优和数据本地化的调优。
本文将从以下几个方面来介绍一下 Spark 的调优。
资源调优并行度调优代码调优数据本地化
内存调优shuffle 参数堆外内存
数据倾斜 (内容较多, 下篇文章见)1
资源调优
在部署集群的时候,指定资源分配的默认参数,需要在 conf 下面的 spark-env.sh 里面指定
SPARK_WORK_CORES 指定每个 worker 分配的核数
SPARK_WORK_MEMORY 指定每个 worker 分配的内存
SPARK_WORK_INSTANCES 指定每台机器启动的 worker 数量
在提交 APPLICATION 的时候,给当前的任务分配更多的资源,在 spark-submit 命令后面指定以下参数:
–executor-cores
–executor-memory
–total-executor-cores
当然也可以在配置文件 Spark-default.conf 里面配置
spark.executor.cores
spark.executor.memory
spark.max.cores
动态的分配资源
spark.dynamicAllocation.enabled true 开启动态资源分配。
2
并行度优化
如果读取的数据在 HDFS 上,降低 Block 的大小,相当于提高了 RDD 中 partition 的个数。
也可以直接加上参数 numPartitions 来手动的给定分区数。
也可以使用 repartitions / coalesce 算子来改变分区。
在使用 reduceByKey / groupByKey / join 的时候,也可以加上 numPartitions 这个参数的。
自定义分区器,Partitioner 。
如果读取的数据是在 SparkStreaming 中,Receive 模式的话,并行度是由 batch Interval 和 block Interval 来决定的,默认分别是 5 秒和 200 ms。
Direct 模式的话,kafka 的 topic 的分区数就是 RDD 的分区的并行度。
3
代码调优
避免创建重复的 RDD, 可以复用同一个 RDD。
对多次使用的 RDD 进行持久化,这里要思考如何选择一种最合适的持久化策略。
默认情况下,性能最优的是 MEMORY_ONLY ,但是前提是我们的内存必须足够大,要不然很容易导致 OOM。资源受限的时候,可以降一级,使用 MEMORY_ONLY_SER 对数据序列化再保存到内存中,这时的 partition 仅仅是一个字节数组,大大减少了对象的数量,并且降低了内存占用,但是这种级别加大了性能的消耗。如果这时候,数据还是很大,还是很有可能导致 OOM 的,我们还可以再降级,使用 MEMORY_AND_DISK_SER 策略,不建议后面带上副本数,这种策略会优先把数据缓存到内存中,内存缓存不下去才写到磁盘。
这里必须提到持久化算子:cache / persist / checkpoint
cache 只有 MEMORY_ONLY 策略
persist 有很多选择策略,上面出现的,都可以。
checkpoint 如果一个 RDD 的计算时间比较长或者计算起来很复杂,一般都将这个 RDD 的计算结果保存到 HDFS 上,这样数据会更加安全。
如果一个 RDD 的依赖关系非常长,也会使用 checkpoint, 会切断依赖关系,提高容错的效率。
注意它们三个区别,前两个是为了提高性能,任务执行结束之后会把主动地把临时存数据的目录删掉。但是 checkpoint 是为了容错,需要显示的指定一个目录,可以是 HDFS 上的目录。
避免使用 shuffle 类的算子,这种情况下:有一个 RDD 很小,可以使用广播变量来代替 join。join 算子 = 广播变量 + filter/map/flatMap。
使用 map-side 预聚合的 shuffle 算子,即尽量使用有 combiner 的算子。
好处:可以减少 shuffle write 写磁盘的数据量,还可以减少 shuffle read 拉取数据的大小,最后还可以减少 reduce 任务的聚合次数。
下面这些算子是由有 combiner 的:
reduceByKey, 所以在有些场景下可以代替 groupByKey 。
aggregateByKey, 可以自定义在 map 和 reduce 端的逻辑。
combineByKey
尽可以能使用高性能的算子,比如像下面这样:
使用 reduceByKey 代替 groupBykey。
使用 mapPartition 代替 map。
使用 foreachPartition 代替 foreach。
filter 之后使用 coalesce 减少分区。
使用 repartition 和 coalesce 来操作分区
使用广播变量,同一个 Executor 中的 task 公用一份变量集合。可以避免多余的变量副本占用内存,避免导致频繁的 GC。广播变量的发送方式,Executor 一开始并没有广播变量,而是 task 运行的时候需要广播变量,会找到 BlockManager 要这个变量,BlockManager 会去找 Driver 的BlockManagerMaster 要。
使用 kryo 优化序列化,在 spark 中使用的最多的三个地方是:广播变量、RDD<T> 自定义类型,RDD 持久化的时候。
Kryo 比 Java 默认的序列化速度要快,序列化之后的数据要小,大概是 1/10 。Spark 默认使用 Java 的 ObjectOutputStream 来序列化,但是 Spark 也支持 Kryo 来序列化。需要在代码里面指定:
优化数据结构,Java 中有三种类型比较消耗内存:
对象,每个对象都有对象头,引用等额外的信息,比较占用内存。
字符串,每一个字符串内部都有一个字符数组以及长度等额外的信息。
集合类型,集合内部会使用内部类来封装集合元素。
官方建议,推荐使用字符串来替代对象,用原始类型 Long, Int 等来替代字符串,使用数组来代替集合类型。这样可以尽可能的减少内存占用,从而降低 GC 频率,提升性能。
使用高性能库 fashutil 库,扩展了 Java 的标准集合框架,能够占用更小的内存,更快的存取速度。JDK 要求 7 以及以上版本。
4
数据本地化
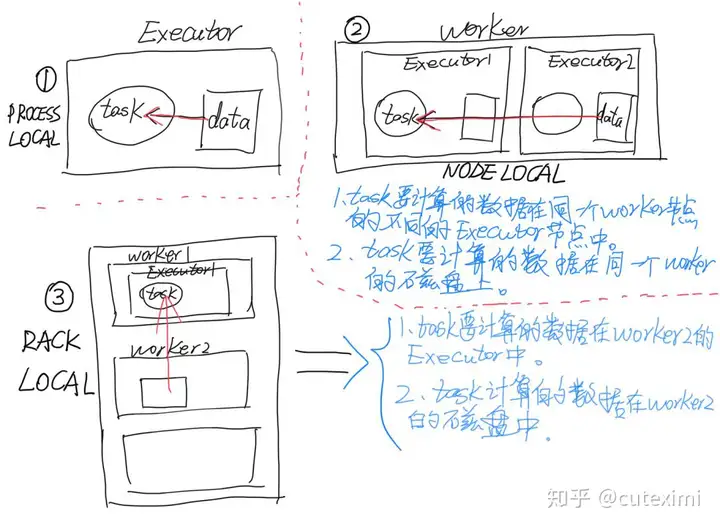
往期的文章很详细的说明了什么是本地化,数据本地化是谁来负责,具体流程以及调优建议。可以戳
。
5
内存优化
这里放一张图,堆内存对象分配。
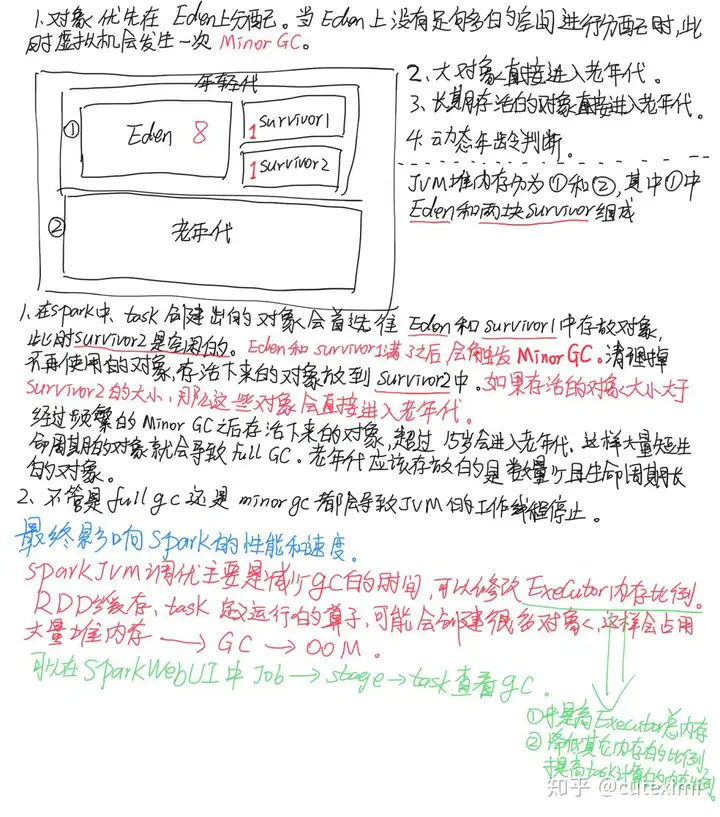
Spark JVM 调优主要是降低 GC 的时间,可以修改 Executor 内存的比例参数,可以参考这篇文章Spark 的 shuffle 文件寻址流程,文章的最后提到了 Spark 的统一内存分配以及调优。比如我们可以根据业务来调整内存的大小以及分配。
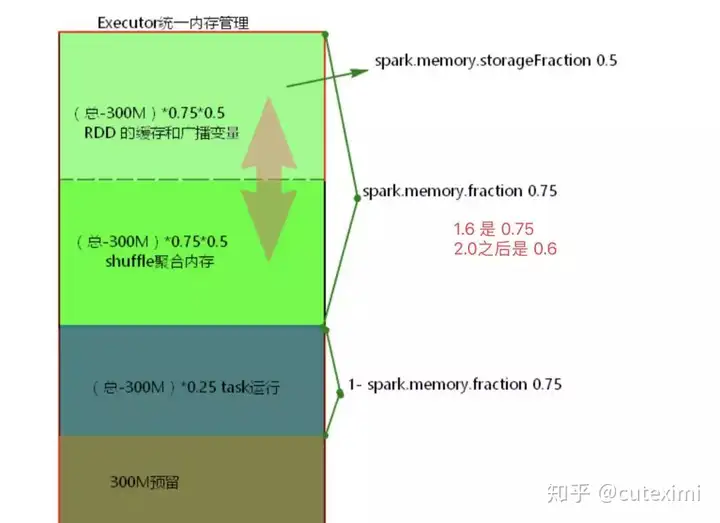

6
shuffle 参数调优
Spark 基于内存进行计算,擅长迭代计算,流式处理,但也会发生shuffle 过程。shuffle 的优化,以及避免产生 shuffle 会给程序提高更好的性能。因为 shuffle 的性能优劣直接决定了整个计算引擎的性能和吞吐量。
从 shuffle write 和 shuffle read 的角度来分析。可以参考这篇文章:
7
调节 Executor 堆外内存
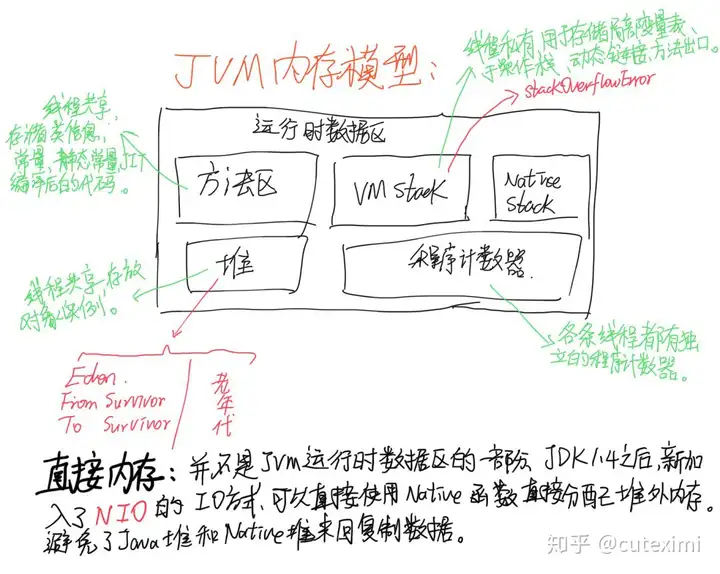
Spark 底层 shuffle 的传输方式使用 netty 传输,netty 在进行网络传输的过程中会申请堆外内存(netty 是零拷贝),所以使用了堆外内存。拉取数据的过程,可以查看这篇文章:
,默认情况下,堆外内存默认上限是每个 Executor 的 10%,建议这个内存给到 1 G,
可以在提交内存的时候加上配置:
8
数据倾斜
内容较多,本文篇幅就已经很多了,所以留到下篇文章见喽。




















暂无评论内容