
Spark作为大数据领域受到广泛青睐的一代框架,一方面是相比前代框架Hadoop在计算性能上有了明显的提升,另一方面则是来自于Spark在数据处理上,同时支持批处理与流处理,能够满足更多场景下的需求。今天我们就来具体讲一讲Spark的批处理和流处理两种数据处理模式。

从定义上来说,Apache Spark可以理解为一种包含流处理能力的批处理框架。Spark与Hadoop的MapReduce引擎基于各种相同原则开发而来,但是通过完善的内存计算和处理优化机制来加快批处理工作负载的运行速度。
Spark既可作为独立集群部署(需要相应存储层的配合),也可与Hadoop集成并取代MapReduce引擎,去负责分布式计算的部分,这也使得企业从Hadoop到Spark,能够以更低的成本完成转换。
Spark批处理模式
与MapReduce不同,Spark的数据处理工作全部在内存中进行,只在一开始将数据读入内存,以及将最终结果持久存储时需要与存储层交互,所有中间态的处理结果均存储在内存中。
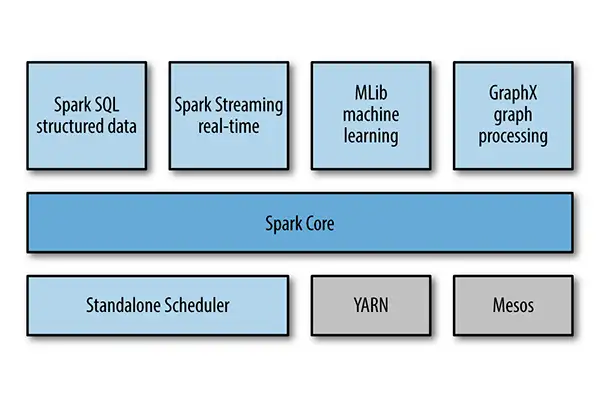
虽然内存中处理方式可大幅改善性能,Spark在处理与磁盘有关的任务时速度也有很大提升,因为通过提前对整个任务集进行分析可以实现更完善的整体式优化。
为此Spark可创建代表所需执行的全部操作,需要操作的数据,以及操作和数据之间关系的Directed Acyclic Graph(有向无环图),即DAG,借此处理器可以对任务进行更智能的协调。
Spark流处理模式
Spark的流处理能力是由Spark Streaming实现的。Spark本身在设计上主要面向批处理工作负载,为了弥补引擎设计和流处理工作负载特征方面的差异,Spark引入了微批(Micro-batch)的概念。
微批处理,将数据流视作一系列非常小的“批”,借此即可通过批处理引擎的原生语义进行处理。

Spark Streaming会以亚秒级增量对流进行缓冲,随后这些缓冲会作为小规模的固定数据集进行批处理。这种方式的实际效果非常好,但相比真正的流处理框架在性能方面依然存在不足。
Spark在数据处理上,兼具批处理和流处理的能力,对于大部分企业需求来说,这就足够使用了。这也是Spark现在的市场地位的由来,甚至相比于真正的实时流处理引擎Storm显得更受到青睐。




















暂无评论内容