
全文共17984字,预计学习时长30分钟或更长
![图片[1]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-2290a5d49e3f133a52fe6a792f936a33_720w.webp)
如今,有不少关于Spark的相关介绍,但很少有人从数据科学家的角度来解释该计算机引擎。因此,本文将试着介绍并详细阐述——如何运行Spark?
![图片[2]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-5ed1f6731b174b5477f8e9497ecd5e12_720w.webp)
一切是如何开始的呢?— MapReduce(用于大规模数据集的编程模型)
![图片[3]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-0afbe7f561ea6a66096136000781866f_720w.webp)
假设我们的任务是砍伐森林中的所有树木,有两种选择:
· 让戴夫·巴蒂斯塔(美国职业摔跤运动员)用电动电锯把树一棵接一棵地砍掉。
· 找500个普通人用一般的斧头砍伐不同的树。
你更喜欢哪种方法?
虽然选项1仍然是一些人的选择,但是对选项2的需求促使了MapReduce的出现。
在大数据中,巴蒂斯塔的解决方案称为垂直扩展/扩大,就像在单个工作单元中添加/填充大量内存和硬盘一样。
而第二种解决方法称为水平扩展/横向扩展。就像把许多普通机器连接在一起(用更少的内存),然后并行使用这些机器。
垂直扩展相对于水平扩展而言,有以下几个优势:
· 问题规模较小时,速度更快:假设是2棵树。巴蒂斯塔会用那可怕的电锯一下把两棵树砍掉,而两个普通人则还得用斧头砍这两棵树。
· 易于理解:这就是做事的一贯方式,通常按顺序思考问题,这也是整个计算机体系结构和设计的演变过程。
而水平扩展优势如下:
· 更加便宜:雇佣50个普通人比雇佣一个像巴蒂斯塔这样的人要便宜得多。除此之外,巴蒂斯塔需要很多的照顾和保养,以帮助他保持冷静。他非常敏感,就算对一些小事情也是这样,犹如内存过高的机器。
· 问题规模较大时速度更快:设想一下有1000棵树,1000普通工人VS 巴蒂斯塔。利用水平扩展时,如果面临一个很大的问题,只需要雇佣100或1000个廉价工人即可。但和巴蒂斯塔工作却不是这样。你必须增加内存,而这也意味着需要更多的冷却基础设施和保养费用。
![图片[4]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic1.zhimg.com/80/v2-97f9ef20bd8d0bdb277dc353ce68fc10_720w.webp)
MapReduce使第二种选择成为可能,通过允许使用计算机集群进行并行化来实现这种可能性。
MapReduce由两个术语组成:
映射:
其主要是apply/map函数。将数据分成n个组块,并将每个块发送给不同的工作单元 (映射器)。若想对数据行应用某个函数,该工作单元就会照做。
归约:
使用基于groupby key的某个函数汇总数据。其主要是利用groupby。
当然,系统如期工作还有许多事情需要完成。
为什么使用Spark?
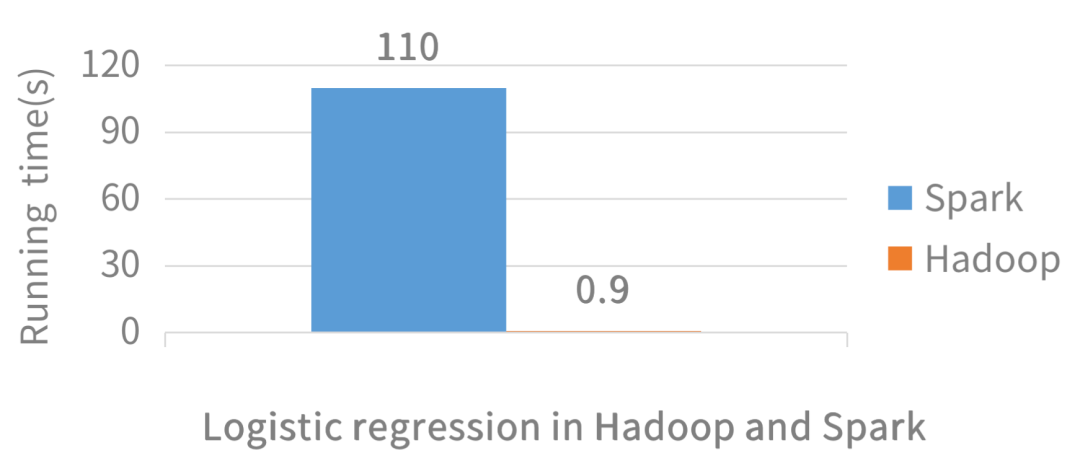
Hadoop(大数据平台)是引入MapReduce编程范式的首个开源系统,而Spark是使其速度更快(100倍)的系统。
Hadoop过去有很多数据传送指令,因为其过去常常将中间结果写入文件系统。
这就影响了分析速度。
Spark有一个内存模型,因此Spark在工作时不会向磁盘写入太多内容。
简单地说,Spark比Hadoop更快,现在很多人都在使用Spark。
开始使用Spark
安装Spark本身就是一个令人头痛的问题。
如果想了解Spark是如何工作的以及如何真正地使用,建议在社区版在线Databricks上使用Sparks。别担心,这是免费的。
传送门:https://databricks.com/try-databricks?utm_source=databricks&utm_medium=homev2tiletest
![图片[7]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-a209f9a71e8cb0559f93a700504436c2_720w.webp)
注册并登录后,屏幕会出现以下显示。
![图片[8]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-9e6d929822d5108999b8bf36edec0117_720w.webp)
在此可建立新的笔记本。
选择Python笔记本,自定义笔记本名称。
一旦启动一个新的笔记本并尝试执行任何命令,笔记本会询问是否要启动一个新的集群。点击确定。
下一步检查sparkcontext是否存在。要检查sparkcontext是否存在,只需运行以下命令:
![图片[9]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-95deb25a0dd939a36a915855bcc94cbd_720w.webp)
这意味着运行Spark就需要新建一个笔记本。
加载数据
下一步是上传用于学习Spark的一些数据。只需点击主页选项卡上的“导入并查看数据”。
本文末尾会使用多个数据集来说明,但现在先从一些非常简单的东西开始。
添加shakespeare.txt文件,下载传送门:https://github.com/MLWhiz/spark_post
![图片[11]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-41c03c01781cc202cbfda7c659c2c99f_720w.webp)
可以看到文件加载到/FileStore/tables/shakespeare.txt这个位置了。
第一个Spark程序
本文倾向通过示例学习,所以让我们完成分布式计算的“Hello World”: WordCount 程序。
![图片[13]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-218cf6afe9b3a57e3d2c3ac5f63068ea_720w.webp)
这是一个小例子,其统计了文档字数并输出了其中的10。
大多数工作是在第二指令中完成的。
如果目前还是跟不上,也别担心,你的任务就是运行Spark。
但是在讨论Spark的基础知识之前,先了解一下Python基础知识。如果使用过Python的函数式编程,那么理解Spark将变得容易得多。
对于没有使用过Python的人,以下是一个简短介绍。
Python中编程的函数方法
![图片[15]-代码+案例详解:使用Spark处理大数据最全指南-卡咪卡咪哈-一个博客](https://pic1.zhimg.com/80/v2-de9154687370e90ffaff6d457a2e2118_720w.webp)
1. 映射
map用于将函数映射到数组或列表中。如果想应用某函数到列表中的各元素中,只需通过使用for循环来实现,但是python lambda函数可允许在python的单行中实现这一点。
# Lets say I want to square each term in my_list.
squared_list = map(lambda x:x**2,my_list)
print(list(squared_list))
————————————————————
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
在上面的例子中,可将map看作一个函数,该函数输入两个参数—一个函数和一个列表。
然后,其将该函数应用于列表中各元素,而lambda则可供编写内联函数使用。在这里lambda x:x**2定义了一个函数,将x输入,返回x²。
也可以用另外一个合适的函数来代替lambda。例如:
return x**2
my_list = [1,2,3,4,5,6,7,8,9,10]
# Lets say I want to square each term in my_list.
squared_list = map(squared,my_list)
print(list(squared_list))
————————————————————
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
同样的结果,但是lambda表达式使代码更紧凑,可读性更强。
2. 筛选
另一个广泛使用的函数是filter函数。此函数输入两个参数—一个条件和一个筛选列表。
如果想使用条件筛选列表,请使用filter函数。
# Lets say I want only the even numbers in my list.
filtered_list = filter(lambda x:x%2==0,my_list)
print(list(filtered_list))
—————————————————————
[2, 4, 6, 8, 10]
3. 约归
下面介绍的函数是reduce函数。这个函数将是Spark中的主力部分。
这个函数输入两个参数——一个归约函数,该函数输入两个参数,以及一个应用约归函数的列表。
my_list = [1,2,3,4,5]
# Lets say I want to sum all elements in my list.
sum_list = functools.reduce(lambda x,y:x+y,my_list)
print(sum_list)
在python2中,约归曾经是Python的一部分,现在我们必须使用reduce,使其作为函数工具的一部分。
在这里,lambda函数输入两个值x和y,返回它们的和。直观地,可以认为约归函数的工作原理如下:
Reduce function then sends 3,3 ; the lambda function returns 6
Reduce function then sends 6,4 ; the lambda function returns 10
Reduce function finally sends 10,5 ; the lambda function returns 15
在约归中使用的lambda函数的一个条件是它必须是:
· 交换律 a + b = b + a 和
· 结合律 (a + b) + c == a + (b + c).
在上面的例子中,使用了交换律和结合律。另外还可以使用的其他函数:max, min, *等等。
再次回到Spark
既然已经掌握了Python函数式编程的基本知识,现在开始了解Spark。
首先深入研究一下spark是如何工作的。Spark实际上由驱动和工作单元两部分组成。
工作单元通常执行这些需要完成的任务,而驱动则是发布任务指令的。
弹性分布式数据集
RDD(弹性分布式数据集)是一种并行的数据结构,分布在工作单元节点之间。RDD是Spark编程的基本单元。
在wordcount示例中,其第一行
lines = sc.textFile(“/FileStore/tables/shakespeare.txt”)
获取一个文本文件,将其分布到工作单元节点上,这样RDD就可以并行地处理此文件。还可以使用sc.parallelize函数并行计算列表。
例如:
new_rdd = sc.parallelize(data,4)
new_rdd
—————————————————————
ParallelCollectionRDD[22] at parallelize at PythonRDD.scala:267
在Spark中,可以对RDD执行两种不同类型的操作:转换和操作。
1. 转换:从现有的RDD中创建新的数据集
2. 操作:从Spark中获取结果的机制
转换基础
假设已经以RDD的形式获取了数据。
目前可以通过访问工作机器来重报数据。现在想对数据进行一些转换。
比如你可能想要筛选、应用某个功能等等。
在Spark中,这可以由Transformation函数完成。
Spark提供了很多转换函数。
完整列表:http://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
以下列出一些笔者常用的函数:
1. Map函数:
将给定函数用于RDD。
注意其句法与Python略有不同,但是可以完成同样的操作。现在还不必担心collect操作,因为目前只需要将其视为在squared_rdd中收集数据然后返回列表的函数。
rdd = sc.parallelize(data,4)
squared_rdd = rdd.map(lambda x:x**2)
squared_rdd.collect()
——————————————————
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
2. Filter函数:
此处依旧没什么惊喜。将输入作为一个条件,仅保留满足该条件的元素。
rdd = sc.parallelize(data,4)
filtered_rdd = rdd.filter(lambda x:x%2==0)
filtered_rdd.collect()
——————————————————
[2, 4, 6, 8, 10]
3. distinct函数:
仅返回RDD中的不同元素。
rdd = sc.parallelize(data,4)
distinct_rdd = rdd.distinct()
distinct_rdd.collect()
——————————————————
[8, 4, 1, 5, 9, 2, 10, 6, 3, 7]
4. flatmap函数:
与 map函数相似,但是每个输入项可映射到0个或更多个输出项。
rdd = sc.parallelize(data,4)
flat_rdd = rdd.flatMap(lambda x:[x,x**3])
flat_rdd.collect()
——————————————————
[1, 1, 2, 8, 3, 27, 4, 64]
5. Reduce By Key函数:
此函数与Hadoop MapReduce中的reduce相似。
目前,Spark若只与Lists一起使用,是无法求得数值的。
在Spark中,有一对RDD的概念使其更加灵活。假设有一个数据,其中包含产品、类别和售价。这种情况下仍然可以并行化数据。
rdd = sc.parallelize(data,4)
现在的RDD rdd 包含各元组。
目前想找出从每个类别中获得的总收入。
要实现这一目标,必须将rdd转换为一对rdd,以使其只包含键值对/元组。
category_price_rdd.collect()
—————————————————————–
[(‘Fruit’, 200), (‘Fruit’, 24), (‘Fruit’, 56), (‘Vegetable’, 103), (‘Vegetable’, 34)]
此处应用map函数获取所需格式的rdd。使用文本格式运行时,形成的RDD有很多字符串。然后使用map函数将其转换为所需格式。
所以现在的category_price_rdd中包含产品类别和售价。
如果想将关键类别进行约归并统计总价,那么可以这样做:
category_total_price_rdd.collect()
———————————————————[(‘Vegetable’, 137), (‘Fruit’, 280)]
6. Group By Key函数:
与reduceByKey相似,Group By Key只是把所有元素放入迭代器中,并不会reduce。举个例子,如果想保留关键类别和所有产品你的价值,可以使用此函数。
再次使用map函数,获取所需形式的数据。
rdd = sc.parallelize(data,4)
category_product_rdd = rdd.map(lambda x: (x[1],x[0]))
category_product_rdd.collect()
————————————————————
[(Fruit, Apple), (Fruit, Banana), (Fruit, Tomato), (Vegetable, Potato), (Vegetable, Carrot)]
然后像下面这样使用groupByKey:
findata = grouped_products_by_category_rdd.collect()
for data in findata:
print(data[0],list(data[1]))
————————————————————
Vegetable [Potato, Carrot]
Fruit [Apple, Banana, Tomato]
此处groupByKey函数运行,其返回该类别中的类别和产品列表。
操作基础
至此已经筛选了数据,并在其上映射了一些函数。接下来要完成计算。
现在希望获取本地计算机上的数据或将其保存到文件中,或者以excel或任何可视化工具中的某些图形的形式显示结果。
为此需要进行一些操作。
完整操作列表:http://spark.apache.org/docs/latest/rdd-programming-guide.html#actions
笔者倾向使用的一些常见操作如下:
1. collect
上文已多次使用过此操作。该操作将整个RDD返回到应用程序中。
2. reduce
使用函数func(该函数接受两个参数并返回一个)来聚合数据集的元素。该函数可交换和组合,以便并行进行正确计算。
rdd.reduce(lambda x,y : x+y)
———————————
15
3. take
有时需要查看RDD包含内容,但无需获取内存中的所有元素。take操作返回包含RDD前n个元素的列表。
rdd.take(3)
———————————
[1, 2, 3]
4. takeOrdered
takeOrdered操作使用自然顺序或自定义比较器返回RDD的前n个元素。
# descending order
rdd.takeOrdered(3,lambda s:-1*s)
—-
[23, 12, 5]
rdd = sc.parallelize([(5,23),(3,34),(12,344),(23,29)])
# descending order
rdd.takeOrdered(3,lambda s:-1*s[1])
—
[(12, 344), (3, 34), (23, 29)]
至此所有的基础都已涉及,接下来回到wordcount示例。
理解WordCount示例
目前已基本了解Spark所提供的转换和操作。
现在理解wordcount程序应该不难。接下来一起逐行完成该程序。
第一行创建RDD并将其分发给工作单位。
此RDD行包含文件中的语句列表。使用take操作可查看rdd内容。
——————————————–
[The Project Gutenberg EBook of The Complete Works of William Shakespeare, by , William Shakespeare, , This eBook is for the use of anyone anywhere at no cost and with, almost no restrictions whatsoever. You may copy it, give it away or]
此RDD格式如下:
实际上,下一行是整个工序中的主要函数。
.map(lambda x: (x, 1))
.reduceByKey(lambda x,y : x + y))
该函数包含对RDD行进行的一系列转换。首先进行flatmap转换。flatmap转换将行作为输入,单词作为输出。因此,进行flatmap转换之后,RDD的形式如下:
接下来,对flatmap输出进行map转换,将RDD转换为:
最后,进行reduceByKey转换以计算每个单词出现的时间。
随后,RDD接近最终的理想形式。
下一行是一个操作,它在本地获取生成的RDD的前10个元素。
此行仅输出结果。
print(“%s: %i” % (word, count))
以上就是wordcount程序。
到目前为止,我们讨论了Wordcount示例以及可以在Spark中使用的基本转换和操作。但是在现实生活中并不做文字计数。
Spark应用实例
接下来用具体实例解决一些常见的转换。
所研究的数据集是Movielens(https://github.com/MLWhiz/spark_post),该数据集是一个稳定基准数据集。1700部电影中的1000名用户给出了100000份评分,发布于1998年4月。
Movielens数据集包含大量文件,但本文仅处理3个文件:
1. 用户: 此文件名为 “u.user”, 文件中的列如下:
2. 评分: 此文件名为 “u.data”, 文件中的列如下:
3. 电影: 此文件名为 “u.item”, 文件中的列如下:
首先使用主页选项卡上的“导入和浏览数据”将这3个文件导入spark实例。
业务合作伙伴联络我们并要求从这些数据中找出25部评分最高的电影。一部电影会收到多少次评分?
在不同的RDD中加载数据,看看数据包含什么内容吧。
ratingRDD = sc.textFile(“/FileStore/tables/u.data”)
movieRDD = sc.textFile(“/FileStore/tables/u.item”)
print(“userRDD:”,userRDD.take(1))
print(“ratingRDD:”,ratingRDD.take(1))
print(“movieRDD:”,movieRDD.take(1))
———————————————————–
userRDD: [1|24|M|technician|85711]
ratingRDD: [196\t242\t3\t881250949]
movieRDD: [1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0]
值得注意的是,回答这个问题需要使用ratingRDD。但是ratingRDD中没有电影名称。
所以必须使用 movie_id合并movieRDD和ratingRDD。
如何在Spark中做到这一点?
以下是使用的代码。其中还使用了一个新的转换leftOuterJoin。请阅读以下代码中的文档和评论。
# Create a RDD from RatingRDD that only contains the two columns of interest i.e. movie_id,rating.
RDD_movid_rating = ratingRDD.map(lambda x : (x.split(“\t”)[1],x.split(“\t”)[2]))
print(“RDD_movid_rating:”,RDD_movid_rating.take(4))
# Create a RDD from MovieRDD that only contains the two columns of interest i.e. movie_id,title.
RDD_movid_title = movieRDD.map(lambda x : (x.split(“|”)[0],x.split(“|”)[1]))
print(“RDD_movid_title:”,RDD_movid_title.take(2))
# merge these two pair RDDs based on movie_id. For this we will use the transformation leftOuterJoin(). See the transformation document.
rdd_movid_title_rating = RDD_movid_rating.leftOuterJoin(RDD_movid_title)
print(“rdd_movid_title_rating:”,rdd_movid_title_rating.take(1))
# use the RDD in previous step to create (movie,1) tuple pair RDD
rdd_title_rating = rdd_movid_title_rating.map(lambda x: (x[1][1],1 ))
print(“rdd_title_rating:”,rdd_title_rating.take(2))
# Use the reduceByKey transformation to reduce on the basis of movie_title
rdd_title_ratingcnt = rdd_title_rating.reduceByKey(lambda x,y: x+y)
print(“rdd_title_ratingcnt:”,rdd_title_ratingcnt.take(2))
# Get the final answer by using takeOrdered Transformation
print “#####################################”
print “25 most rated movies:”,rdd_title_ratingcnt.takeOrdered(25,lambda x:-x[1])
print “#####################################”
——————————————————————–RDD_movid_rating: [(242, 3), (302, 3), (377, 1), (51, 2)]
RDD_movid_title: [(1, Toy Story (1995)), (2, GoldenEye (1995))]
rdd_movid_title_rating: [(1440, (3, Above the Rim (1994)))] rdd_title_rating: [(Above the Rim (1994), 1), (Above the Rim (1994), 1)]
rdd_title_ratingcnt: [(Mallrats (1995), 54), (Michael Collins (1996), 92)]
#####################################
25 most rated movies: [(Star Wars (1977), 583), (Contact (1997), 509), (Fargo (1996), 508), (Return of the Jedi (1983), 507), (Liar Liar (1997), 485), (English Patient, The (1996), 481), (Scream (1996), 478), (Toy Story (1995), 452), (Air Force One (1997), 431), (Independence Day (ID4) (1996), 429), (Raiders of the Lost Ark (1981), 420), (Godfather, The (1972), 413), (Pulp Fiction (1994), 394), (Twelve Monkeys (1995), 392), (Silence of the Lambs, The (1991), 390), (Jerry Maguire (1996), 384), (Chasing Amy (1997), 379), (Rock, The (1996), 378), (Empire Strikes Back, The (1980), 367), (Star Trek: First Contact (1996), 365), (Back to the Future (1985), 350), (Titanic (1997), 350), (Mission: Impossible (1996), 344), (Fugitive, The (1993), 336), (Indiana Jones and the Last Crusade (1989), 331)] #####################################
《星球大战》是Movielens数据集中评分最高的电影。
现在可以使用以下命令在一个命令中完成所有步骤,但现在代码有点乱。
这样做是为了表明Spark的链接功能可以使用,借此绕过变量创建的过程。
leftOuterJoin(movieRDD.map(lambda x : (x.split(“|”)[0],x.split(“|”)[1])))).
map(lambda x: (x[1][1],1)).
reduceByKey(lambda x,y: x+y).
takeOrdered(25,lambda x:-x[1]))
再来一次。练习:
现在想要使用相同的数据集找到评分最高的25部电影。事实上只需要那些至少有100次评分的电影。
# We already have the RDD rdd_movid_title_rating: [(u429, (u5, uDay the Earth Stood Still, The (1951)))]
# We create an RDD that contains sum of all the ratings for a particular movie
rdd_title_ratingsum = (rdd_movid_title_rating.
map(lambda x: (x[1][1],int(x[1][0]))).
reduceByKey(lambda x,y:x+y))
print(“rdd_title_ratingsum:”,rdd_title_ratingsum.take(2))
# Merge this data with the RDD rdd_title_ratingcnt we created in the last step
# And use Map function to divide ratingsum by rating count.
rdd_title_ratingmean_rating_count = (rdd_title_ratingsum.
leftOuterJoin(rdd_title_ratingcnt).
map(lambda x:(x[0],(float(x[1][0])/x[1][1],x[1][1]))))
print(“rdd_title_ratingmean_rating_count:”,rdd_title_ratingmean_rating_count.take(1))
# We could use take ordered here only but we want to only get the movies which have count
# of ratings more than or equal to 100 so lets filter the data RDD.
rdd_title_rating_rating_count_gt_100 = (rdd_title_ratingmean_rating_count.
filter(lambda x: x[1][1]>=100))
print(“rdd_title_rating_rating_count_gt_100:”,rdd_title_rating_rating_count_gt_100.take(1))
# Get the final answer by using takeOrdered Transformation
print(“#####################################”)
print (“25 highly rated movies:”)
print(rdd_title_rating_rating_count_gt_100.takeOrdered(25,lambda x:-x[1][0]))
print(“#####################################”)
————————————————————
rdd_title_ratingsum: [(Mallrats (1995), 186), (Michael Collins (1996), 318)]
rdd_title_ratingmean_rating_count: [(Mallrats (1995), (3.4444444444444446, 54))]
rdd_title_rating_rating_count_gt_100: [(Butch Cassidy and the Sundance Kid (1969), (3.949074074074074, 216))]
#####################################
25 highly rated movies: [(Close Shave, A (1995), (4.491071428571429, 112)), (“Schindlers List (1993)”, (4.466442953020135, 298)), (Wrong Trousers, The (1993), (4.466101694915254, 118)), (Casablanca (1942), (4.45679012345679, 243)), (Shawshank Redemption, The (1994), (4.445229681978798, 283)), (Rear Window (1954), (4.3875598086124405, 209)), (Usual Suspects, The (1995), (4.385767790262173, 267)), (Star Wars (1977), (4.3584905660377355, 583)), (12 Angry Men (1957), (4.344, 125)), (Citizen Kane (1941), (4.292929292929293, 198)), (To Kill a Mockingbird (1962), (4.292237442922374, 219)), (“One Flew Over the Cuckoos Nest (1975)”, (4.291666666666667, 264)), (Silence of the Lambs, The (1991), (4.28974358974359, 390)), (North by Northwest (1959), (4.284916201117318, 179)), (Godfather, The (1972), (4.283292978208232, 413)), (Secrets & Lies (1996), (4.265432098765432, 162)), (Good Will Hunting (1997), (4.262626262626263, 198)), (Manchurian Candidate, The (1962), (4.259541984732825, 131)), (Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1963), (4.252577319587629, 194)), (Raiders of the Lost Ark (1981), (4.252380952380952, 420)), (Vertigo (1958), (4.251396648044692, 179)), (Titanic (1997), (4.2457142857142856, 350)), (Lawrence of Arabia (1962), (4.23121387283237, 173)), (Maltese Falcon, The (1941), (4.2101449275362315, 138)), (Empire Strikes Back, The (1980), (4.204359673024523, 367))]
#####################################
到目前为止,已经讨论过RDD,因为其非常强大。
RDD也可以处理非关系型数据库。
他们让你完成很多无法用SparkSQL完成的事情?
是的,你也可以通过Spark使用 SQL,接下来就谈谈这个。
Spark Datafrmes
Spark为数据科学家提供了DataFrame API来处理关系数据。
请记住,在后台它仍然是所有RDD,这就是本文伊始关注RDD的原因。
下文将从使用Spark DataFrames所需的一些常用功能开始。它的一些句法变化与Pandas很相像。
1. 读取文件
2. 显示文件
使用Spark DataFrames显示文件有两种方式。
本文倾向于 display,因其看起来更为美观简洁。
3. 改变列名
这是一个好功能,一直都很有用。注意不要遗漏列表前的*。
4. 一些基本统计结果
print(len(ratings.columns)) #Column Count
———————————————————
100000
4
还可以使用以下方式看到数据帧的统计结果
5. 选择部分列
6. 筛选
使用多个条件筛选数据帧:
7. Groupby函数
Groupby函数可以与spark数据帧结合使用。操作与pandas groupby函数基本相同,只是需要导入pyspark.sql. functions函数。
display(ratings.groupBy(“user_id”).agg(F.count(“user_id”),F.mean(“rating”)))
本文中已从每个user_id中找到了评分数以及平均评分。
8. 排序
如下所示,还可以使用F.desc函数进行降序排序
使用spark Dataframes数据帧进行增加/合并
无法找到与Spark DataFrames合并的pandas对应项,但SQL可以与与dataframes一起使用,所以可以使用SQL合并dataframes。
试着在Ratings上运行SQL。
首先将ratings df注册到临时表ratings_table,其上可运行sql操作。
如你所见,SQL select语句的结果还是Spark Datadframe。
现在再添加一个Spark Dataframe,观察是否可以使用SQL查询来使用连接:
#get one more dataframe to join
movies = spark.read.load(“/FileStore/tables/u.item”,format=”csv”, sep=”|”, inferSchema=”true”, header=”false”)
# change column names
movies = movies.toDF(*[“movie_id”,”movie_title”,”release_date”,”video_release_date”,”IMDb_URL”,”unknown”,”Action”,”Adventure”,”Animation “,”Children”,”Comedy”,”Crime”,”Documentary”,”Drama”,”Fantasy”,”Film_Noir”,”Horror”,”Musical”,”Mystery”,”Romance”,”Sci_Fi”,”Thriller”,”War”,”Western”])
现在尝试加入movie_id上的表格,以获得评级表中的电影名。
尝试用RDD做之前做的事情。找到评分最高的25部电影:
同时找到拥有超过100票的25部评分最高电影:
上面的查询中使用了GROUP BY,HAVING和ORDER BY子句以及别名。这表明使用sqlContext.sql可以完成相当复杂的事情。
关于Display命令的小提示
还可以使用display命令以在笔记本中显示图表。
选择“绘图选项”时,可以看到更多选项。
Spark Dataframe与RDD的相互转换
有时可能希望Spark Dataframe与RDD的相互转换,这样就可以充分利用这两个不同的功能。
要从DF转换为RDD,只需执行以下操作:
由RDD转换为数据帧:
RDD以时间和编码工作上的付出为代价提供更多控制。而Dataframes则提供熟悉的编码平台。但是现在可以在这两者之间来回转换了。
结论
Spark提供了一个界面,在此可以对数据进行转换和操作。Spark还拥有Dataframe API,便于简化数据科学家向大数据的过渡。
GitHub代码传送门:https://github.com/MLWhiz/spark_post?source=post_page———————–—-
留言 点赞 关注
我们一起分享AI学习与发展的干货
编译组:柳玥、胡昕彤
相关链接:
https://towardsdatascience.com/the-hitchhikers-guide-to-handle-big-data-using-spark-90b9be0fe89a
如需转载,请后台留言,遵守转载规范




















暂无评论内容