
作为Spark负责流计算的核心组件,Spark Streaming是整个Spark学习流程当中非常重要的一块。对于Spark Streaming,作为Spark流计算的实际承载组件,我们也需要更全面的掌握。今天的大数据入门分享,我们就来讲讲Spark Streaming实际应用。

一、关于Spark Streaming
实际上来说,Spark进行数据计算处理,是继承了Hadoop MapReduce的理念,因此从实质定性来说,Spark仍然是一个批处理框架,而非流处理框架。
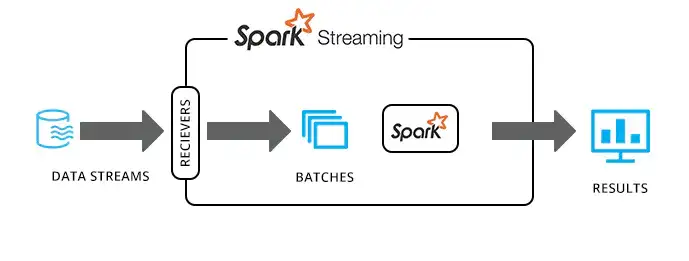
Spark Streaming由于其本身的扩展性、高吞吐量以及容错能力等特性,能够提供近实时的数据处理。简单来说,Spark Streaming是因为批处理的速度较快而达到了类似实时的效果。
Spark Streaming的近实时处理,也可以理解为微批实时处理,将不断输入的数据流先进行分批,就像坐电梯一样,把一批数据装入电梯,然后一批批的去输送,每一批的间隔是以秒级别的。
二、Sparkstreaming应用场景
基于Spark Streaming优秀的性能表现,在很多的企业级应用场景,如网站监控和网络监控、异常监测、网页点击、用户行为、用户迁移等,都能够给出合理的解决方案。
总的来说,Spark Streaming适用于:
不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度的类似场景当中;其次是如果项目需求除了实时计算,还有一定量的批处理任务,那么Spark streaming也能很好地解决。
三、Spark Streaming程序结构
Spark Streaming功能结构上通常包含以下五部分——
1、导入Spark Streaming相关包:
Spark Streaming作为Spark框架上的一个组件,具有很好的集成性。在开发Spark Streaming应用程序时,只需导入Spark Streaming相关包,无需额外的参数配置。
2、创建StreamingContext对象:
同Spark应用程序中的SparkContext对象一样,StreamingContext对象是Spark Streaming应用程序与集群进行交互的唯一通道,其中封装了Spark集群的环境信息和应用程序的一些属性信息。
3、创建InputDStream:
Spark Streaming需要根据数据源类型选择相应的创建DStream的方法。
4、操作DStream:
对于从数据源得到的DStream,用户可以调用丰富的操作对其进行处理。
5、启动与停止Spark Streaming应用程序:
在启动Spark Streaming应用程序之前,DStream上所有的操作仅仅是定义了数据的处理流程,程序并没有真正连接上数据源,也没有对数据进行任何操作,当ssc.start()启动后程序中定义的操作才会真正开始执行。
四、Spark Streaming优缺点
优点:
Spark Streaming基于Spark Core API,因此其能够与Spark中的其他模块保持良好的兼容性,为编程提供了良好的可扩展性;
Spark Streaming是粗粒度的准实时处理框架,一次读取完或异步读完之后处理数据,且其计算可基于大内存进行,因而具有较高的吞吐量;
Spark Streaming采用统一的DAG调度以及RDD,因此能够利用其lineage机制,对实时计算有很好的容错支持;
Spark Streaming的DStream是基于RDD的在流式数据处理方面的抽象,其transformations以及actions有较大的相似性,这在一定程度上降低了用户的使用门槛,在熟悉Spark之后,能够快速上手Spark Streaming。
缺点:
Spark Streaming是准实时的数据处理框架,采用粗粒度的处理方式,当batch time到时才会触发计算,这并非像Storm那样是纯流式的数据处理方式。此种方式不可避免会出现相应的计算延迟。
关于大数据入门,Spark Streaming实际应用,以上就为大家做了简单的介绍了。Spark在大数据学习当中,是非常重要的一部分,也是作为大数据开发工程师必备的技能点,值得多花时间去深入理解和掌握。




















暂无评论内容