
了解更多推荐系统、大数据、机器学习、AI等硬核技术,可以关注我的知乎,或同名微信公众号
在前面两篇文章中,我们讨论了Spark SQL和DataFrame API。我们研究了如何连接到内置和外部数据源,查看了Spark SQL引擎相关的内容,并探讨了诸如SQL和DataFrames之间的相互操作性,创建和管理视图和表,以及高级DataFrame和SQL转换等主题。
尽管我们在第3章中简要介绍了DataSet API ,但还是概述了如何在Spark中创建,存储,序列化和反序列化DataSet (强类型分布式集合)这些比较重要的方面。
在本章中,我们将深入了解DataSet :我们将探索在Java和Scala中DataSet的有关用法 ,还有Spark如何管理内存以适应作为高级API一部分的DataSet结构,以及与使用DataSet相关的成本。
1. Java和Scala的单一API
正如你从第三章中(图3-1和表3-6)所记得的那样,DataSet 为强类型对象提供了统一且单一的API。在Spark支持的语言中,只有Scala和Java是强类型的。因此,Python和R只支持无类型的DataFrame API。
DataSet 是特定领域的类型对象,可以使用函数式编程或从DataFrame API熟悉的DSL运算符并行操作DataSet 。
由于这个单一的API,Java开发人员不再有落后的风险。例如,Scala未来的任何接口或行为的变化,如groupBy(),flatMap(),map(),或filter() 这些方法,Java API也会是一样的,因为它是一个单一的接口,有统一的规范,这对这两种实现方式是类似的。
1.1 Scala案例类和JavaBeans用于DataSet
如果你还记得,从第3章(表3-2)可以知道,Spark 本身有内部的数据类型,如StringType,BinaryType,IntegerType,BooleanType和MapType,以便在Spark操作期间能够无缝地映射到Scala和Java语言特定的数据类型。这种映射是通过编码器完成的,我们将在本章后面讨论。
为了创建Dataset[T],其中T是Scala中类型化对象,也就是我们常说的泛型,因此你需要一个定义该对象的case类。为了方便说明,在这里使用第3章(表3-1)中的示例数据,我们有一个JSON文件,其中包含数以百万计的博客作者关于Apache Spark的条目,这些条目采用以下格式:

要创建分一个布式Dataset[Bloggers],我们必须首先定义一个Scala case类,该类定义包含Scala对象的每个单独字段。这个case类作为类型对象Bloggers的蓝图或数据结构:

现在,我们可以从数据源读取文件:
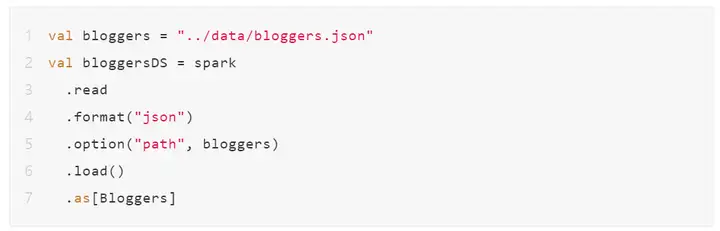
生成的分布式DataSet 中的每一行都是Bloggers类型。
同样,你也可以在Java创建Bloggers类型的JavaBean类,然后使用编码器创建一个Dataset<Bloggers>,如下所示:
如你所见,在Scala和Java中创建DataSet 需要一些深思熟虑,因为你必须要知道正在读取的行的所有字段的列名和类型。在这一点是与DataFrames不同,对于DataFrame你可以选择让Spark推断数据结构,但是Dataset API要求你提前定义好数据结构,并且case类或JavaBean类要与该数据结构匹配,否则会出现异常。
注意
Scala案例类或Java类定义中的字段名称必须与数据源中的顺序匹配。数据中每一行的列名会自动映射到类中的相应名称,并且类型会自动保留。
如果字段名称与输入数据匹配,则可以使用现有的Scala case类或JavaBean类。使用Dataset API与使用DataFrames一样容易,简洁和声明式。对于大多数DataSet 的转换,你可以使用在上一章中了解到的相同关系运算符。
让我们使用样本来研究DataSet 更多的一些方面。
2. 处理DataSet
创建样本DataSet 的一种简单而动态的方法是使用SparkSession实例。在这种情况下,为了方便说明,我们动态创建了一个包含三个字段的Scala对象:uid(用户的唯一ID),uname(随机生成的用户名字符串)和usage(服务器或服务使用情况的分钟数)。
2.1 创建样本数据
首先,让我们生成一些样本数据:
在Java中,这个想法是相似的,但是我们必须使用显式Encoders编码器(在Scala中,Spark会隐式处理):
注意
Scala和Java之间生成的DataSet 将有所不同,因为随机种子算法可能有所不同。因此,你的Scala和Java的查询结果将有所不同。
现在我们有了生成的DataSet — dsUsage,让我们执行在上一章中完成的一些常见转换操作。
2.2 样本数据转换
回想一下,DataSet 是特定领域的对象的强类型集合。这些对象可以使用功能或关系操作进行并行转换操作。这些转换的例子包括map(),reduce(),filter(),select()和aggregate()。作为高阶函数的示例,这些方法可以通过lambda,闭包或函数作为参数并返回结果。因此,它们非常适合函数式编程。
Scala是一种函数式编程语言,最近,lambda,函数自变量和闭包也已添加到Java中。让我们尝试一些Spark中的高阶函数,并对之前创建的示例数据使用函数式编程结构。
高阶函数和函数式编程
举一个简单的例子,让我们使用它filter()来返回dsUsage DataSet 中所有使用时间超过900分钟的用户。一种实现方法是使用函数表达式作为filter()方法的参数:

另一种方法是定义一个函数并将该函数作为参数提供给filter():

在第一种情况下,我们使用lambda表达式{d.usage > 900}作为filter()方法的参数,而在第二种情况下,我们定义了Scala函数def filterWithUsage(u: Usage) = u.usage > 900。在这两种情况下,该filter()方法都会在分布式Dataset中的对象的每一行上进行迭代Usage对象,并应用表达式或执行该函数,Usage为表达式或函数值作为一行,当布尔值为true时,返回一个具有Usage 类型的新的Dataset。(有关方法签名的详细信息,请参见Scala文档。)
在Java中,用于filter()参数的类型为FilterFunction<T>。可以匿名内联定义或使用命名函数定义。在此示例中,我们将通过名称定义函数并将其分配给变量f。在filter()中应用此函数将返回一个新的Dataset,其中包含我们的过滤条件为true的所有行:

并非所有的lambda或函数参数都必须求Boolean值。他们也可以返回计算值。考虑使用高阶函数的示例map(),我们的目标是找出usage中价值超过特定阈值的每个用户的使用成本,以便我们为每位用户提供每分钟的特殊价格。

要在Java中使用map(),必须定义一个MapFunction<T>。可以是匿名类,也可以是extends的已定义类MapFunction<T>。在此示例中,我们将其内联使用,即在方法中调用自己:

尽管我们已经计算了使用成本的值,但是我们不知道计算的值与哪些用户相关联。我们如何获得这些信息?
步骤很简单:
创建一个Scala case样例类或JavaBean类UsageCost,并添加一个名为cost的其他字段或列。定义一个函数来计算cost然后在map()方法中使用它。这是Scala中的样子:
现在,我们有了一个转换后的DataSet ,其中有一个新的列cost ,由我们map()转换中的函数以及所有其他列计算得出。
同样,在Java中,如果我们想要与每个用户相关的成本,则需要定义一个JavaBean类UsageCost和MapFunction<T>。有关完整的JavaBean示例,请参见本书的GitHub repo;为了简洁起见,我们仅在此处显示内联MapFunction<T>:

关于使用高阶函数和DataSet ,需要注意以下几点:
我们使用类型化的JVM对象作为函数的参数。我们使用点表示法(来自面向对象的编程)来访问类型化的JVM对象内的各个字段,从而使其更易于阅读。我们的某些函数和lambda签名可以是类型安全的,从而确保编译时错误检测并指示Spark处理哪些数据类型,执行哪些操作等。使用lambda表达式中的Java或Scala语言功能,我们的代码可读,表达和简洁。Spark在Java和Scala中都提供了等效的map()和filter(),没有高级函数的构造,因此你不必被迫对Datasets或DataFrames使用函数式编程。相反,你可以简单地使用条件DSL运算符或SQL表达式:例如dsUsage.filter(“usage > 900″)或dsUsage($”usage” > 900)。(有关此内容的更多信息,请参见“使用DataSet 的成本”。)对于DataSet ,我们使用编码器,这是一种在JVM和Spark内部二进制格式之间针对其数据类型有效地转换数据的机制(有关更多信息,请参见“DataSet 编码器”中的内容)。注意
函数和函数式编程并非Spark DataSet 独有。你也可以将它们与DataFrames一起使用。回想一下,DataFrame是一个Dataset[Row],其中Row是一个通用的无类型JVM对象,可以容纳不同类型的字段。方法签名采用在其上进行操作的表达式或函数Row,这意味着每个Row数据类型都可以作为表达式或函数的输入值。
将DataFrame转换为DataSet
为了对查询和构造进行强类型检查,可以将DataFrames转换为Datasets。要将现有的DataFrame df转换为SomeCaseClass类型的Dataset ,只需使用df.as[SomeCaseClass]表示即可。我们之前看到了一个示例:
spark.read.format(“json”)返回一个DataFrame<Row>,在Scala中是的类型别名Dataset[Row]。Using.as[Bloggers]指示Spark使用编码器(将在本章稍后讨论)将对象从Spark的内部内存表示形式序列化/反序列化为JVM Bloggers对象。
3. DataSet 和DataFrame 的内存管理
Spark是一个内存密集型的分布式大数据引擎,因此其有效使用内存对其执行速度至关重要。在其整个发行历史中,Spark的内存使用已发生了显着的变化:
Spark 1.0使用基于RDD的Java对象进行内存存储,序列化和反序列化,这在资源和速度方面付出的代价都非常高。而且,存储空间是在Java堆上分配的,因此对于大型数据集你只能依靠JVM的垃圾回收(GC)。Spark 1.x引入了Tungsten项目。它的突出特点之一是一种新的基于行的内部格式,该格式使用偏移量和指针在堆外存储器中布局DataSet 和DataFrame 。Spark使用一种称为编码器的高效机制在JVM及其内部Tungsten格式之间进行序列化和反序列化。堆外分配内存意味着减少了GC对Spark的影响。Spark 2.x引入了第二代Tungsten引擎,具有整个阶段的代码生成和基于列的矢量化内存布局的功能。该新版本以现代编译器的思想和技术为基础,还利用现代CPU和缓存体系结构,以“单条指令,多个数据”(SIMD)方法进行快速并行数据访问。4. DataSet 编码器
编码器将堆外内存中的数据从Spark的内部Tungsten格式转换为JVM Java对象。换句话说,它们将Dataset对象从Spark的内部格式序列化和反序列化为JVM对象,包括原始数据类型。例如,Encoder[T]将会从Spark的内部Tungsten格式转换为Dataset[T]。
Spark内置支持为原始类型(例如,字符串,整数,长整数)、Scala case类和JavaBeans自动生成生成编码器。与Java和Kryo的序列化和反序列化相比,Spark编码器明显更快。
在我们先前的Java示例中,我们显式创建了一个编码器:
但是,对于Scala,Spark会自动为这些高效的转换器生成字节码。让我们看一下Spark内部基于Tungsten行的格式。
4.1 Spark的内部格式与Java对象格式
Java对象的开销很大,包括标头信息,哈希码,Unicode信息等。即使是简单的Java字符串(如“ abcd”)也需要48字节的存储空间,而不是你想象的4字节。可以想象一下创建一个MyClass(Int, String, String)对象的开销。
Spark不会为DataSet 或DataFrame创建基于JVM的对象,而是分配堆外Java内存来布局其数据,并使用编码器将数据从内存中表示形式转换为JVM对象。例如,图6-1显示了如何在MyClass(Int, String, String)内部存储JVM对象。
当数据以这种连续方式存储并且可以通过指针算术和offets访问时,编码器可以快速序列化或反序列化该数据。这意味着什么?
4.2 序列化和反序列化(SerDe)
在分布式计算中,这并不是一个新概念,在分布式计算中,数据经常通过网络在群集中的计算机节点之间传播,序列化和反序列化是将类型化对象编码(序列化)为发送方的二进制表示或格式,接收方从二进制格式转换为重新规范的数据类型对象的过程。
例如,如果JVM对象MyClass在图6-1有在Spark集群节点之间共享,发送者将序列成字节数组,并且接收器将它反序列化为MyClass类型的JVM对象。
JVM拥有自己的内置Java序列化器和反序列化器,但是效率低下,因为(如上一节所述)JVM在堆内存中创建的Java对象会膨胀。因此,这个过程很缓慢。
出于以下几个原因,这是Dataset编码器可以解决的地方:
Spark的内部Tungsten二进制格式(见图6-1和6-2)将对象存储在Java堆内存之外,并且结构紧凑,因此这些对象占用的空间更少。编码器可以使用带有内存地址和偏移量的简单指针算法遍历整个存储器,从而快速进行序列化(图6-2)。在接收端,编码器可以将二进制表示形式快速反序列化为Spark的内部表示形式。编码器不受JVM的垃圾收集暂停的阻碍。但是,正如我们接下来讨论的那样,生活中大多数美好的事物都是有代价的。
5. 使用DataSet 的成本
在第3章的“DataFrame与DataSet ”中,我们概述了使用DataSet 的一些好处——但是这些好处是有代价的。正如前面所指出的那样,当DataSet 被传递到高阶函数如,filter()、map()和flatMap(),或作为参数传递给lambdas 方法时,存在与从Spark的内部Tungsten格式反序列化到JVM对象的成本。
与在Spark中引入编码器之前使用的其他串行器相比,此开销较小且可以接受。但是,在较大的DataSet 和密集查询中,这些成本会累积并可能影响性能。
5.1 降低成本的策略
减轻过度序列化和反序列化的一种策略是在查询中使用DSL表达式,并避免过度使用lambda作为匿名函数作为高阶函数的参数。因为lambda在运行前一直是匿名的,并且对Catalyst优化器是不透明的,所以当你使用它们时,它不能有效地识别你在做什么(你没有告诉Spark该做什么),因此无法优化查询(请参阅第三章中“ Catalyst Optimizer”这一节))。
第二种策略是将查询链接在一起,从而尽量减少序列化和反序列化。将查询链接在一起是Spark中的一种常见做法。
让我们用一个简单的例子来说明。假设我们有一个类型为Person的DataSet ,其中Person定义为Scala案例类:
我们想使用函数式编程对此DataSet 发出一组查询。
让我们检查一个我们无效地编写查询的情况,以便我们无意地承担重复序列化和反序列化的代价:
如你在图6-3中所观察到的,每次我们从lambda迁移到DSL(filter($”salary” > 8000))时,都会产生序列化和反序列化Person JVM对象的成本。
相比之下,以下查询仅使用DSL,不使用lambda。结果,它的效率更高,整个组合查询和链接查询都不需要序列化/反序列化:
出于好奇心里,你可以在本书的GitHub仓库中查看本章笔记中两次运行之间的时间差异。
6. 总结
在本章中,我们详细介绍了如何在Java和Scala中使用DataSet 。我们探索了Spark如何管理内存以适应DataSet 构造(作为其统一和高级API的一部分),并且我们考虑了与使用DataSet 相关的一些成本以及如何减少这些成本。我们还向你展示了如何在Spark中使用Java和Scala的函数式编程构造。
最后,我们了解了编码器如何从Spark的内部Tungsten二进制格式到JVM对象进行序列化和反序列化。
在下一章中,我们将介绍如何通过检查高效的I/O策略、优化和调整Spark配置以及在调试Spark应用程序时要查找的属性和筛选值来优化Spark。
了解更多推荐系统、大数据、机器学习、AI等硬核技术,可以关注我的知乎,或同名微信公众号



















暂无评论内容