
来介绍一下目前超强的开源模型~求一波点赞
前言&背景:
原文:High-Resolution Image Synthesis with Latent Diffusion Models
Satble Diffusion的出现,可以说是扩散模型的一个非常重大的里程碑。个人理解核心层面有三个部分:
1.高质量低门槛的开源模型。
2.保证高分辨率创作图的同时,极大的降低了资源消耗量。
3.在多种下游任务如:超分,inpaintning,img2img,txt2img,都有非常良好的表现,
可谓是平民福音,下面我们就详细介绍Stable-Diffusion的优化原理:
一句话总结:
核心创新点:通过构建latent-diffusion-model ,解决了之前直接在高维度特征建立扩散模型带来的资源消耗和精度限制 ,在多类下游任务中都实现了State-of-the-art。
详细展开:
1.在做特征编码的过程中,相较于简单暴力使用Transformer对特征进行处理不同,本文更优雅/高效的利用了Transformer的结构。
2.在多种下游任务中都有非常良好的表现。
3.在训练和测试任务中,不需要人为进行加权,这点我感觉是和1. 是相辅相成的,通过transformer的高效利用,使得对应的权重自动得到学习。
4.可支持更大的渲染分辨率。这点主要得益于构建了latent-diffusion-model ,将扩散模型在低维度进行计算,在使用高维特征解码。
5.基于U-net 更新了一种全新的模型结构。
6.开源。
话不多说,下面直接进入模型优化部分:
模型部分:
先来一个整体框架图:
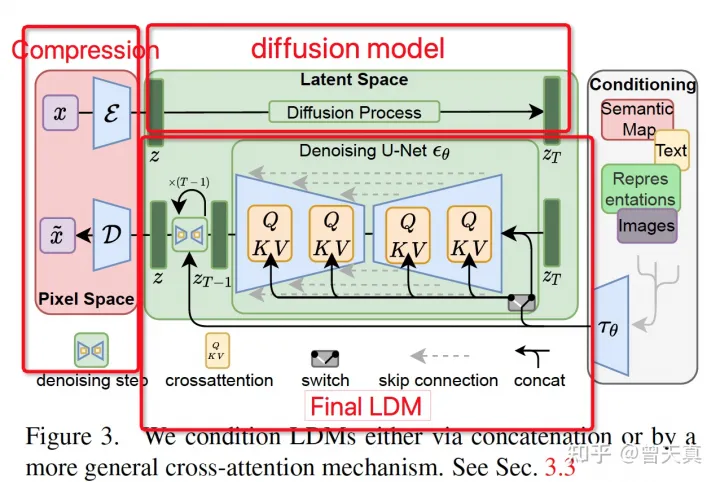
整体分成三个模块:特征压缩模块,扩散模型Diffusion Model 模块,以及带条件的Final-LDM 模块。在下文我们将针对每个模块进行详细的分析。
为了减少传统方法的计算资源消耗问题和分辨率的限制,作者发现使用扩散模型可以通过上采样,来忽视图像感知无关的细节,但是仍然需要耗费大量的资源在像素维度的评估上。
为了解决这个问题,文章将压缩模型和生成模型独立出来,分别构建压缩阶段网络和生成学习阶段网络进行优化。 为了实现优化的目的,文章构建了感知上等同于图像特征空间,但是又能显著减少计算复杂度的模型结构。
通过将扩散模型的学习步骤降低到低位空间进行采样,极大的减少了扩散漠心前/后步骤所需的计算量。而另一方面,为了保证特征降维的高效性和一致性,文章放弃了一些过去的不合理做法。最终实现了高效。state-of-the-art,以及下游多任务复用。
感知压缩模型:
首先就提到了模型压缩的方案,基于历史文章中的经验:《Taming transformers for high-resolution image synthesis》。具体来说,通过将原始三维图像H*W*3维度的图像,encoderϵ\epsilon将原始特征映射到隐层空间。Encoder将图像压缩率为f=H/h=W/wf = H/h=W/w,确定f为2的整数倍。为了减少在高维空间下的方差问题,文章中使用了两种不同的方差约束器:1.KL-reg,通常被用在VQ-GAN中。2.考虑到本文只是针对2维特征空间进行压缩,因此可以使用更为温和压缩方式。不同于以往的针对1维特征进行自回归建模的做法,能减少很多一维特征下处理的重要特征忽略问题。
Latent Diffusion Models:
主要分为三块:1.Diffusion model , 2. latent sapce generate model 3. Conditioning Mechanisms。说人话就是:1.基础扩散模型。2.隐式空间的生成模型。3.带条件的输入机制。
Diffusion Model:
基础扩散模型,文章中简单介绍了扩散模型的原理和优化方法,对于这部分感兴趣的同学可以参看:
1.Diffusion Model (扩散模型)解读系列一(DDPM)Denoising diffusion probalistic models
2.Diffusion Model (扩散模型)解读系列二:(DDIM) denoising diffusion implicit models
3.Diffusion Model (扩散模型)系列四:DALLE 2
Generative Model of Latent Representations:
基于前述的压缩模型,已经有能力在低维度下进行特征操作,而结合前述的感知压缩模型和扩散模型,我们可以将上述两者进行结合,减少计算量的技术上,充分利用图像的隐式特征。优化后的公式:
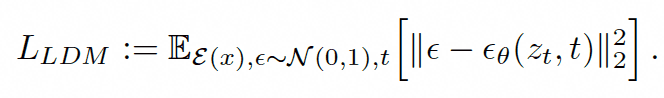
这边与扩散模型最大的差异在于,特征部分结合了感知压缩模型后的特征。
Conditioning Mechanisms:
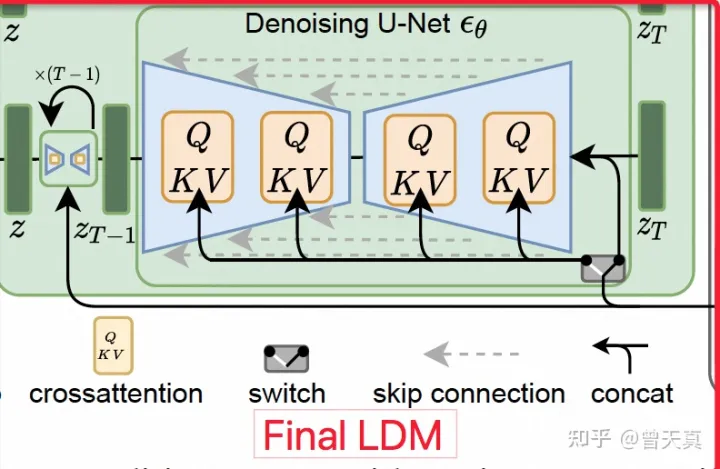
此模块主要考虑了先验的条件输入,在很多场景下,生成模型都需要带条件的输入,例如文本,图像等。因此本文也考虑到了这方面的能力,在生成U-net 部分,增加了Atteniton模块。
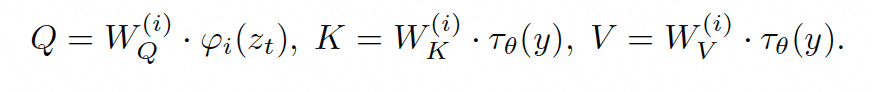
而最终上述LDM损失函数优化成带有条件机制的损失函数:
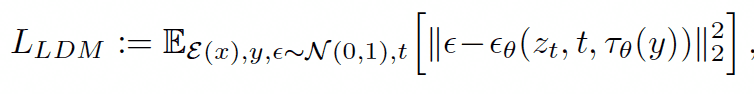
现在回头看整体框架图是不是就豁然开朗了。
试验部分:




其实可以明显看出,在超分,txt2img等领域,都有着非常好的表现。
最后:
感兴趣的同学可以去参看原文,尤其是压缩模型部分的详细数据都在原文的附录中。
另外可以多跑Stable-Diffusion效果,以及最近的Stable-Diffusion-2 已经出来了,效果显著的好。



















暂无评论内容