
Hello~o~朋友们
欢迎回到AI趣闻屋。
4月初 ControlNet 更新到了1.1版本,修复了旧版本bug,也更新了很多新功能。趣闻屋在下载使用后,是真香没错。
新版 ControlNet 1.1 包含14个模型:11个稳定模型、2个实验中模型、1个开发中模型(未完成)。如下:
control_v11p_sd15_canny control_v11p_sd15_mlsd control_v11f1p_sd15_depth control_v11p_sd15_normalbae control_v11p_sd15_seg control_v11p_sd15_lineart control_v11p_sd15s2_lineart_anime control_v11p_sd15_openpose control_v11p_sd15_scribble control_v11p_sd15_softedge control_v11e_sd15_shuffle control_v11e_sd15_ip2p 实验中(SD可用) control_v11p_sd15_inpaint 实验中(SD未可用) control_v11u_sd15_tile 开发中(SD未可用)(本文总字数9300+,建议同学们收藏下来慢慢看)
安装
ControlNet 的安装分两个部分:
1.代码安装
2.模型下载
1.代码安装。代码安装简单,5个步骤:
1.选择【扩展插件】
2.选择【可用】
3.点击【加载自】
4.搜索框输入【ControlNet】
5.找到【sd-webui-controlnet】点击右边的【安装】即可

安装完成后,重启webui
在文生图(txt2img)或者图生图(img2img)里看到 :

就是安装成功了。Good!
长这样:
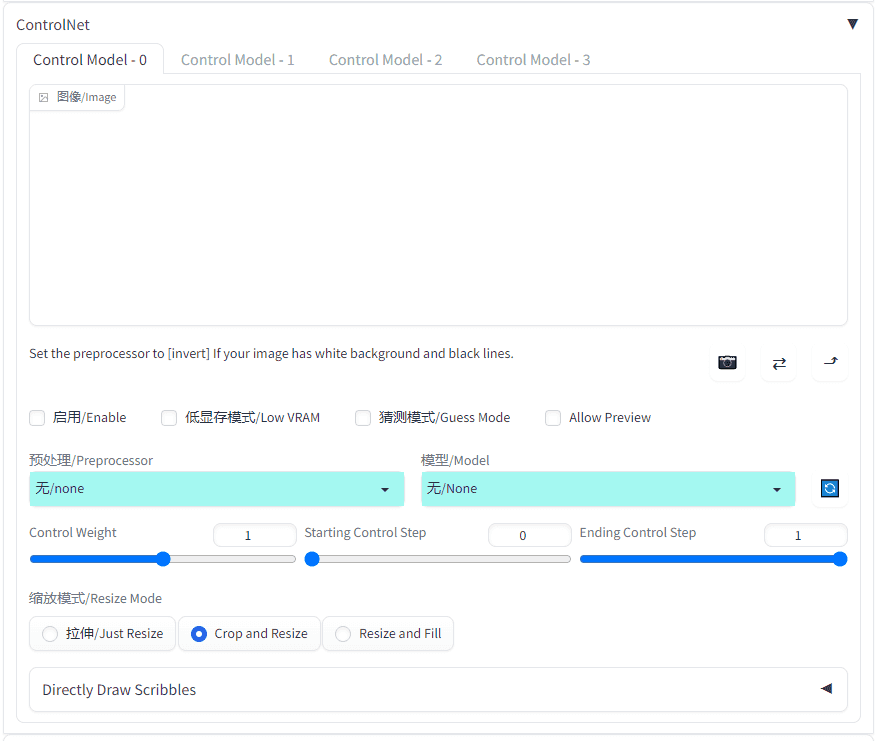
同学们新安装的一般只有一个control model:

扩展的方法也很简单,点击【设置(setting)】:
下拉找到:Controlnet
再找到【多重控制网】:
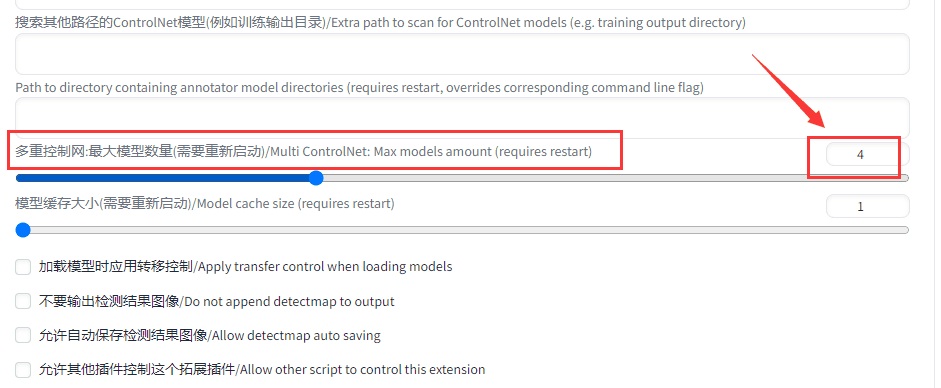
设置成4,或者想要的数量。到这代码的安装就完成了~
2.模型下载
模型下载也简单,一共14个模型都在一个地方。
下载地址:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
打开后长这样:
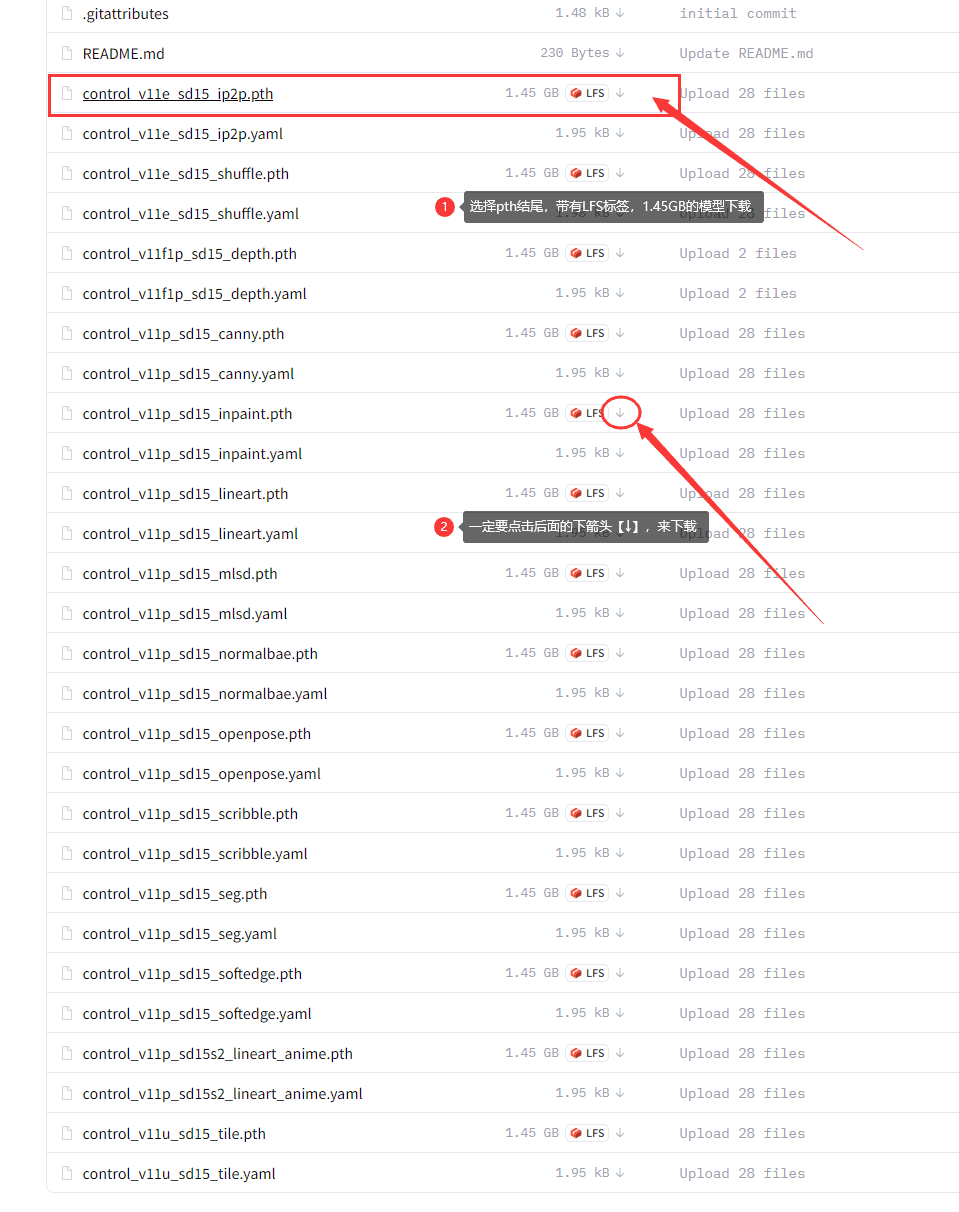
有两个注意点:
1.选择pth结尾的文件,带有LFS标签,1.45GB的模型下载
2.下载时,点击后面的【↓】进行下载,点其他地方下载的文件可能不对
下载路径保存,webui主目录下【models】里的【ControlNet】文件夹:
stable-diffusion-webui\models\ControlNet
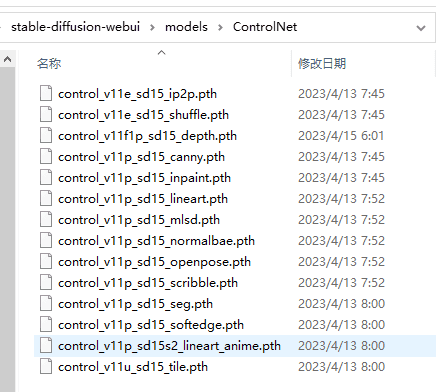
重启weiui。完~
参数介绍
ControlNet 的参数有些是跟着预处理器(Preprocessor)绑定的,这里介绍不绑定预处理器的参数。
如图,一共12个参数:
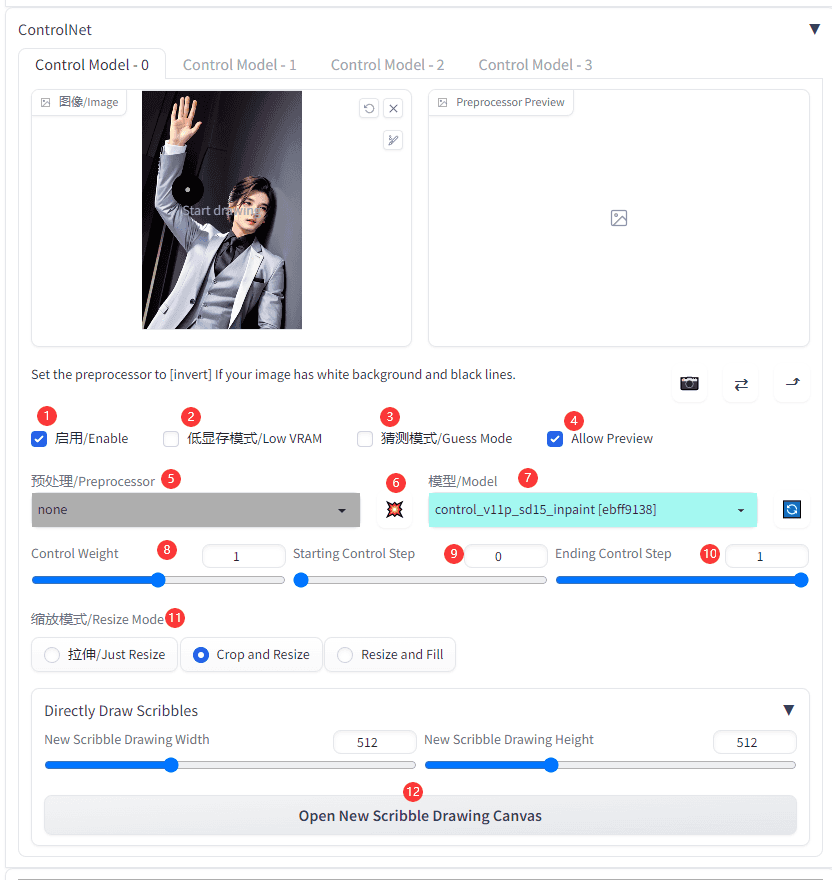
1.启用(Enable),就是启用这个Control model 的意思,想一起使用多少个 Control model 就在对应的 Control model 标签下勾选【启用】。
2.低显存模式(Low VRAM),如果显卡低于6G,则要勾选这个选项,不然会爆胎的噢
3.猜测模式(Guess Mode),顾名思义,就是让AI根据参考图猜测内容,但会增加很多随机性,喜欢让AI发挥想象力的同学,请勾选。
4.Allow Preview新版功能,预览预处理器处理的效果图
5.预处理(Preprocessor),预处理器下拉菜单,配合Controlnet模型一起使用,可以不选择,视Controlnet模型而定。
6.预览按钮 点击图标可以预览预处理器执行的效果图,只有在勾选【Allow Preview】才会出现。
7.模型(Model),Controlnet模型选择菜单,也就是上面下载的模型。
8.Control Weight 控制权重,Controlnet模型的输出权重,权重越大,影响越大。
9.Starting Control Step Controlnet模型对出图施加影响的开始时间,一般不需要动,除非有特别需要。
10.Ending Control StepControlnet模型对出图施加影响的结束时间,一般不需要动,除非有特别需要。
11.缩放模式(Resize Mode)参考图和出图尺寸大小不一致时,使用的缩放模式
(1) Just Resize 直接拉伸,比例不对会出现变形
(2) Crop and Resize 裁剪后拉伸,会丢失原图部分内容
(3) Resize and Fill 拉伸后填充,会在原图上产生新的内容
12.画板尺寸设定 点击【open new scribble drawing canvas】可以打开画板
模型简介
1.control_v11p_sd15_canny
Canny 模型是最常用的模型之一。Canny模型可接受Canny预处理器。
Canny 预处理后,长这样:
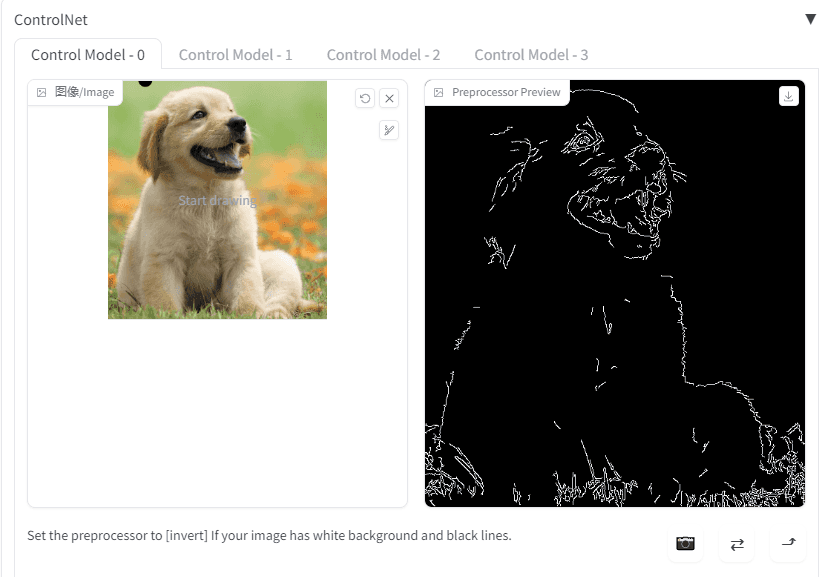
Canny 预处理下有两个参数:
1.Canny low threshold
2.Canny high threshold
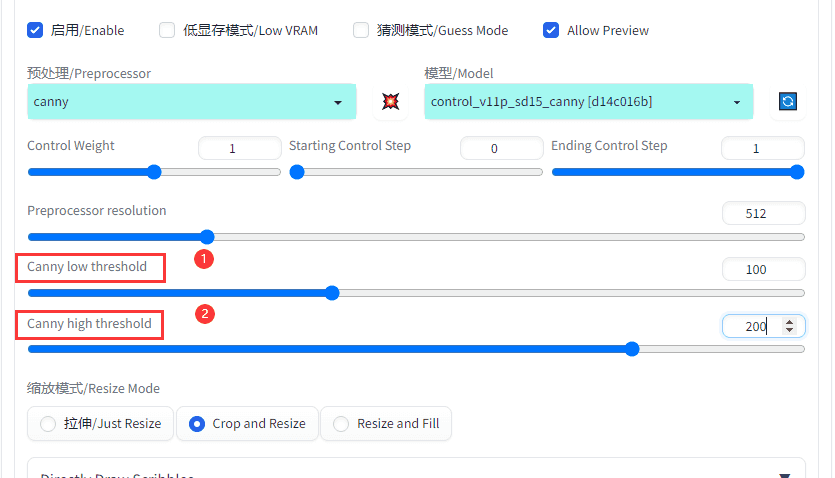
他们用来指定强、弱边缘的阈值。分3种情况:当像素点的梯度值大于 high threshold 时,是强边缘点;梯度值在 low threshold 和 high threshold 之间时,是弱边缘点;小于 low threshold 时,是非边缘点(抑制点)。
意思是这两个值越小,检测到的点线就会越多:
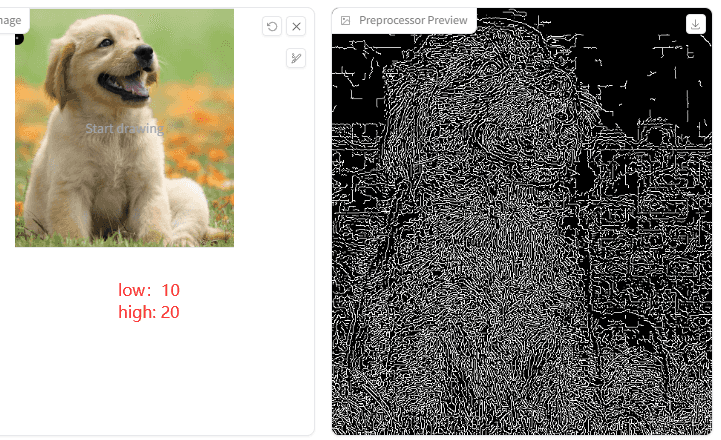
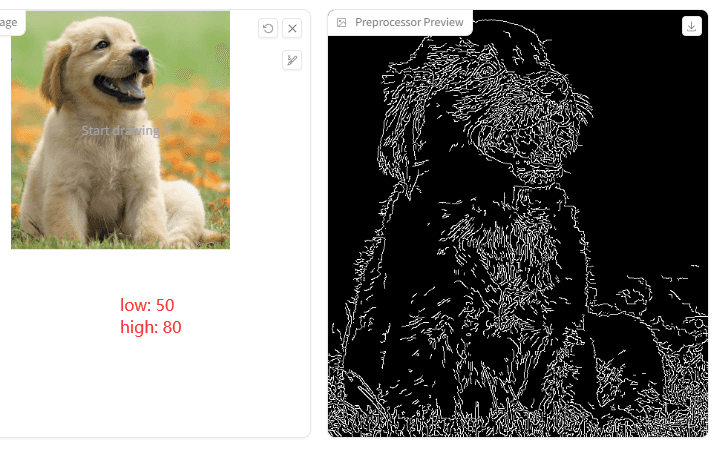
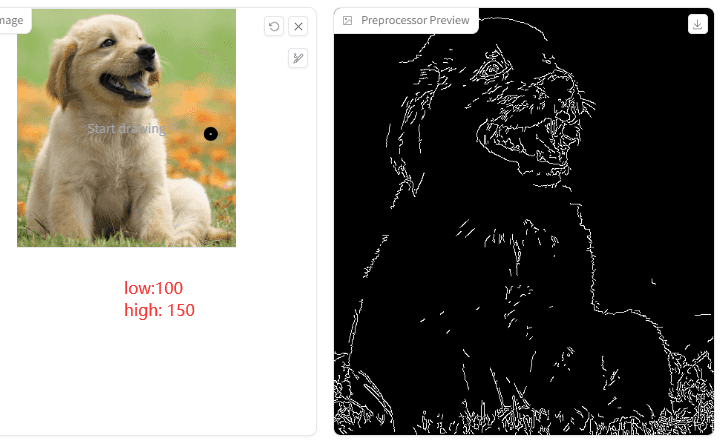
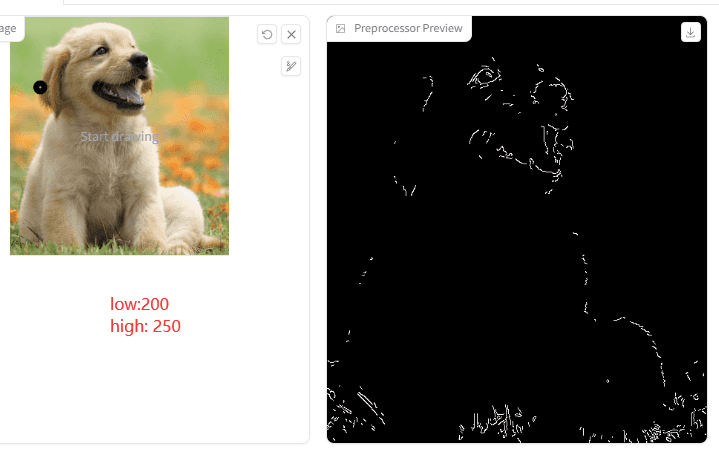
来看下出图效果对比图:

X轴是 Canny low threshold,Y轴是 Canny high threshold。从图中可以分析出,两个值越小,点线越浓烈,出来的图像边缘更锋利和浓厚。
Canny 模型是最常用的模型之一。同学们在不知道选什么好的情况下,又想保留更多图片细节,无脑选择不会错。哈哈,这也是趣闻屋常干的事情~
2.control_v11p_sd15_depth
Depth深度模型。预处理器是:Midas、Leres、Zoe。这三个深度图处理器算法有啥区别?趣闻屋找了好久都没有找到满意的解析。
(有这方面知识的同学。走起,趣闻请你喝奶茶啊~)
淡定,新知识的摄取从来都是先实验的。
先来看看他们生成的深度图有啥区别:
(1) 偏写实风格:
Midas:
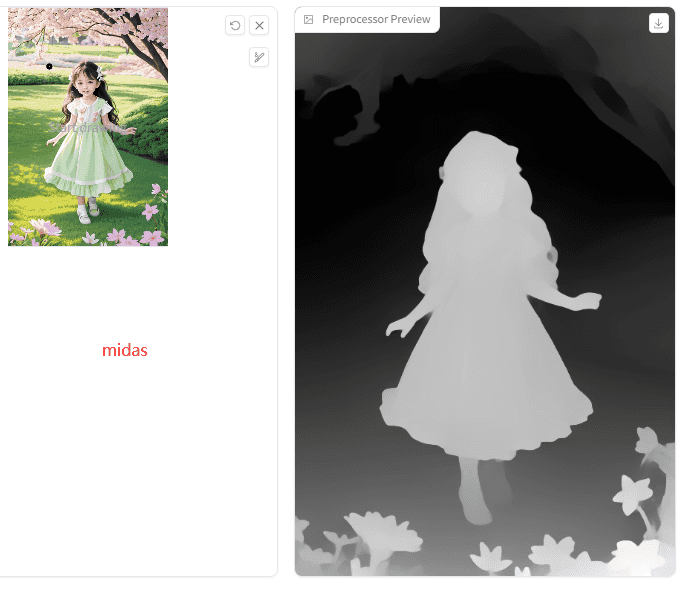
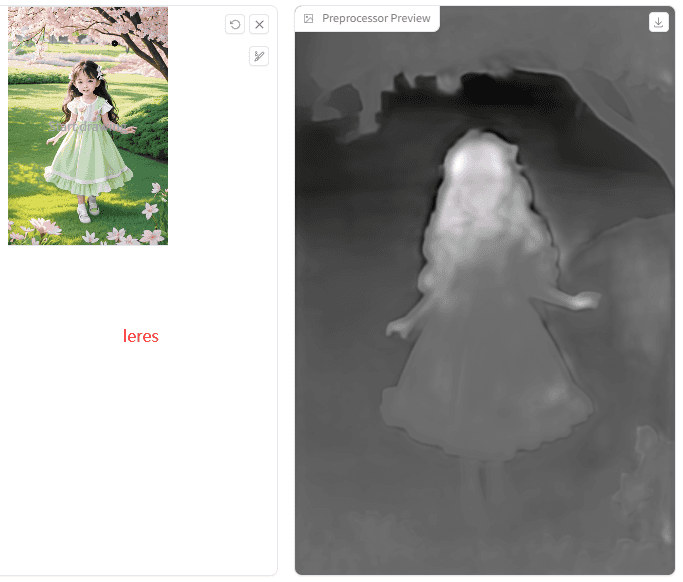
Leres:
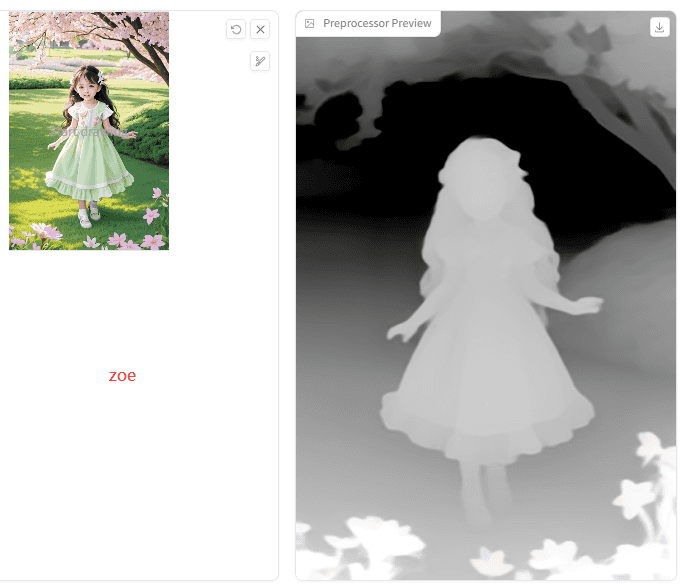
Zoe:
出图效果:

对比图中效果可以初步了解到:Zoe会更贴近原图一些,其次Midas,Leres看着会更平面一些的样子。那是不是说,Leres会不会更适合次元风?试试看!
(2) 二次元风格:
出图效果:
次元风里,三个算法都有不错的表现。但整体来讲还是Zoe的效果会更好些,细节更多,对比度也更好。嗯……再看看自然风格。
(3)自然风景:
出图效果:
自然风光,Zoe和Midas的 3d 还原都可以,Leres还原的效果则浅一些。
Depth总结:3个算法各有千秋,Zoe和Midas的3d景深效果还原更好,,其中Zoe优佳。同学们如果只想还原3d结构,可选Midas,想还原更多3d细节,则选择Zoe;Leres 的识别更轻一些,景深不多的2d图可以考虑首选。
3.control_v11p_sd15_normalbae
Normalbae 法线图模型,法线贴图(Normap map)是一种用来改善表面细节和真实感的贴图,游戏里经常用到。所以官方给了个惊喜,只要渲染引擎出的法线贴图遵循ScanNet 的协议 (http://www.scan-net.org/),就可以直接放到 ControlNet 里使用。
我们来吃个栗子:
正向提示词:
room
Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 5, Seed: 1068242941,
Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: normal_bae,
ControlNet-0 Model: control_v11p_sd15_normalbae [316696f1],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
效果:
真的好用,玩渲染引擎的同学,你的神器来了!
官方强调,Normal bae 比 Normal midas 更符合这个版本,而且Normal midas 算法不合理也不正确,使用渲染引擎出的法线图得到的结果也不准确,建议弃用。
第二个栗子,如何使用法线预处理器:
正向提示词:
a bouquet of flowers
Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 5, Seed: 2436953495,Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: normal_bae,
ControlNet-0 Model: control_v11p_sd15_normalbae [316696f1],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
得到:
美美的!
总结:一般时,法线模型和深度模型可以交替使用。如果深度模型没有得到理想的效果,可以尝试更换法线模型。有法线贴图时,直接上法线模型一键生成,不用多考虑。
4.control_v11p_sd15_mlsd
MLSD 模型用 M-LSD 直线算法来控制Stable Diffusion生成图像。可接受预处理器:msld。
MLSD模型适合直线线条结构多的建筑设计、室内装潢等领域。它能通过简单的几笔勾画配上提示词,就能得到符合线条结构且令人满意的作品。
先来个栗子:
正向提示词:
room
Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 3152096536,Size: 512×768,
Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: mlsd,
ControlNet-0 Model: control_v11p_sd15_mlsd [aca30ff0],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
ControlNet参数设置:
得到效果:
只有寥寥几笔的家装设计草图和一个简单的提示词:room,就能得到如此完善的效果图。真·人类好帮手!
再来看另一个栗子:如果我们对当前的设计不太满意,那么我们可以让AI根据修改的提示词换一种风格——中国风。
其他设定不变,提示词换成:
room,chinese style
得到:
漂亮!
MLSD 预处理器有两个参数:
1.Hough value threshold (MLSD)
2.Hough distance threshold (MLSD)
Hough value threshold 是指MLSD直线算法在霍夫变换中的投票(voting)阈值。当直线在霍夫变换中的 voting 数超过了该阈值才会算作是直线。也就是说,Hough value threshold值设定的越小,直线的检测数越多。
Hough distance threshold 直译,霍夫距离阈值。懵!趣闻屋在网络半天也找不到很好的解析。没关系,趣闻屋特色,看实验:
可以看到,随着Hough distance threshold值的增加,直线的枝条(瞎定义)会被去除,也就是说,它的作用是去除一些“犄角旮瘩”里的线段,让整体轮廓线更清晰简洁。
总结:MLSD 模型适用于室内设计、建筑设计等领域出图。当你手里只有寥寥几笔的家装设计草图,或因缺乏灵感继续创作而陷入焦灼时,或许可以考虑交给AI一下!
5.control_v11p_sd15_openpose
Openpose这个模型大家肯定都很熟悉了,哪怕没用过,那一定听过它鼎鼎大名。顾名思义,Openpose是一个姿势检测模型。同时还可以检测手部,检测手部需要使用预处理openpose hand 或者 openpose Full。
官网表示Openpose可以接受以下7种组合:
1.openpose body
2.openpose hand
3.openpose face
4.openpose body + Openpose hand
5.openpose body + Openpose face
6.openpose hand + Openpose face
7.openpose body + Openpose hand + Openpose face
但趣闻屋看了SD里ControlNet的处理器选择,只有4种:
同学们可在使用中自行选择。官方的建议是不需要考虑那么多,只需考虑两个组合即可:
1.”openpose” = openpose body
2.”openpose Full” = openpose body + Openpose hand + Openpose face
来看看SD里面4种 openpose 预处理器生成的结果区别:
小总结一下:
(1) openpose只检测姿势,包括头部姿势
(2) openpose face是在 openpose 的基础上加了脸部(face)轮廓
(3) openpose faceonly 只有脸部轮廓
(4)openpose full 在 openpose 姿势的基础上不仅加了脸部(face)轮廓,还有手势(hand)
栗子:我们来借助官网的【挥手的男人】来举个栗子:
正向提示词:
man in suit
反向提示词:kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by < bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 7, Seed: 2375748576,
Size: 512×768,
Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: openpose_full,
ControlNet-0 Model: control_v11p_sd15_openpose [cab727d4],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
效果:
赞!
6.control_v11p_sd15_seg
Semantic Segmentation 图像语义分割,把图像根据不同场景分割成不同色块。可接受的处理器:seg_ofade20k (oneformer ade20k), seg_ofcoco (oneformer coco), seg_ufade20k (uniformer ade20k), 或者自创建的遮罩(mask)、
1.Seg OFADE20K (Oneformer ADE20K):是基于ADE20K数据集,使用Oneformer网络结构训练的语义分割模型。适用于分割室内场景,可以更多分割出墙、天花板、地板等细节。
2.Seg OFCOCO (Oneformer COCO):也是使用Oneformer网络结构,不过,是基于COCO数据集训练的语义分割模型。适用分割常见物体,如人脸、汽车、狗等。
3.Seg UFADE20K (Uniformer ADE20K):Uniformer 是一个即将被淘汰的模型,将被OneFormer所取代。Uniformer ADE20K 是Seg 1.0版本使用的方式,但仍是一个非常有效的模型。
语义分割成像图的区别:
(1) seg_ofade20k (oneformer ade20k)
图片内容网络,侵删
(2) seg_ofcoco (oneformer coco)
图片内容来源网络,侵删
(3) seg_ufade20k (uniformer ade20k)
图片内容来源网络,侵删
可以看到,seg_ofade20k (oneformer ade20k)似乎更注重平面,地面是一块,车身的侧面是一块,人和狗是一块,人和狗的阴影也都考虑进去了。seg_ofcoco (oneformer coco)的划分就很直接,人是人,狗是狗,车是车,地板根据亮暗分了两块,其他的细节基本不考虑,两个字“大气”。seg_ufade20k (uniformer ade20k) 则更细节,想用好这个模型,想必是需要更多的提示词。下面我们来看几个简单的栗子吧!
栗子1:室内设计
正向提示词:
indoor
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Model: Guofeng3_v33,
Steps: 30, Sampler: Euler a, CFG scale: 7,Size: 768×512,
输出预处理器
1.seg_ofade20k (oneformer ade20k),
2.seg_ofcoco (oneformer coco),
3.seg_ufade20k (uniformer ade20k)
的对比图效果图:(segmentation 是 seg_ufade20k (uniformer ade20k) 的意思)
结合定义,可以看到 oneformer ade20k 的表现确实略胜一筹,细节还原度更高。
栗子2:街景,我们使用刚才的街景图
图片内图片来源网络,侵删
这里趣闻屋不输入提示词,看效果如何?
参数设置:
Model: Guofeng3_v33,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3738645480, Size: 512×512,
效果:
虽然有点辣眼睛,但是在识别场景内车、人、狗这件事情上,seg_ofcoco (oneformer coco)的表现最佳。
再来看看加入了提示词的效果:
正向提示词:
a man kneeling down next to and caress a dog and a green bowl of water on the ground next to a car,
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
其他参数不变:
seg_ofcoco (oneformer coco) 的依旧表现亮眼。
总结:seg_ofade20k (oneformer ade20k), seg_ofcoco (oneformer coco), seg_ufade20k (uniformer ade20k)之间的区别在于训练数据集和网络结构,这使得它们对于不同的场景表现会有所差异。同学们在使用的时候,根据需要自行选择~
7.control_v11p_sd15_lineart & control_v11p_sd15s2_lineart_anime
Lineart 和 Lineart_anime 线条艺术(线稿)模型,这两个模型放在一起,这样可以一起看他们有何差别。
1.Lineart
官方解析:该模型是在
awacke1/Image-to-Line-Drawings 上训练的。可以用预处理器Lineart 、 Lineart_Coarse生成详细或粗略的线稿来绘制图像。该模型使用足够多的数据进行增强训练,可以通过手动绘制的线稿合成图像。2.Lineart_anime模型支持真实的动漫线条图或提取的线条图输入作为模版来绘制图像。使用时需要注意以下3点:
1.需要一个动画大模型,如:anything-v3
2.这是一个长提示模型。除非你使用 LoRA,否则长提示的结果会更好。如:extracted line drawing, “1girl, Castle, silver hair, dress, Gemstone, cinematic lighting, mechanical hand, 4k, 8k, extremely detailed, Gothic, green eye”
3.Lineart_anime 模型不支持猜测模式
他们有4个预处理器:lineart_anime, lineart_coarse, lineart(lineart_realistic), lineart_standard。下面我们来看他们的线稿对比图:(致敬科比!)
啥区别?
栗子开始:
这次我们使用同一个反向提示词和相同的参数设置,不同的正向提示词和模型。
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 939625287, Size: 512×512,
ControlNet-0 Enabled: True,
ControlNet-0 Model: control_v11p_sd15_lineart [43d4be0d],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
兔子,
正向提示词:rabbit
Model: revAnimated_v122
得到:
还是兔子,我们换个模型:
Model: v1-5-pruned-emaonly
得到:
lineart(lineart_realistic) 原处理器线稿出来的图更真实。
换个动漫风格的:
官方建议动漫风格的正向提示词要长,那就长的;
正向提示词:a woman in a dress with long white hair and a bow tie standing in a forest with trees and grass, Chizuko Yoshida, official art, a character portrait, remodernism
模型:anything-v3-fp32-pruned,
重点!记得换ControlNet动画模型:
ControlNet-0 Model: control_v11p_sd15s2_lineart_anime
如果忘了换?那趣闻屋告诉你会有啥后果:
动画风格,使用了 lineart 模型:
得到:
这样,四不像版本的啥也不像!
换了之后:
迷恋的感觉,有没有?!哈哈哈…
总结:Lineart 模型官方建议使用,Lineart 和 Lineart_Coarse 预处理器。但用下来,趣闻觉得,看风格选择不同的处理器,写实风肯定首选Lineart(Lineart_realistic)。如果是表现粗犷强烈的风格,特效可以选择Lineart_Coarse。动漫不用多说,Lineart anime已预订。最后的Lineart standard,小伙伴们有何高见没?
8.control_v11p_sd15_shuffle
Shuffle 模型,通过随机打撒再扩散重组图像。可接受预训练模型:shuffle。
先来看个官方的示例图:
打乱后变成抽象图了~
再来看看趣闻屋的:
机甲套装,变成了时刻扭曲图。
但也别小看了它,出图效果那是杠杠滴:
使用:
参数设置:
正向提示词:
iron man
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2594063120, Size: 512×768, Model: revAnimated_v122,
ControlNet-0 Enabled: True,
ControlNet-0 Module: shuffle,
ControlNet-0 Model: control_v11e_sd15_shuffle [526bfdae],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
来个白虎铠甲勇士秒变钢铁侠:
参数模型都不变,效果:
主题白色得到很好的保留!这两都是风格相近的。既然Shuffle 号称风格转换模型,那怎么能不来点刺激的呢?
安排!
暗黑风:
参数模型都不变,效果:
再来一个,海底世界秒变卧室:
正向提示词改成:bedroom,其他不变:
这效果,倍儿棒!
Shuffle是个很好玩的模型,特别适合脑洞很大的小伙伴!
去吧~ 带上你的脑洞去驰骋AI绘画界吧!(中二)
9.control_v11p_sd15_scribble
Scribble 涂鸦模型,可接受预处理器有3种:pidinet_scribble,scribble_xdog,scribble_hed。
区别什么的,我们直接看图吧:
pidinet_scribble:
scribble_hed:
scribble_xdog:
scribble_xdog 预处理多了一个参数:XDoG Threshold,默认值32,范围1-64。值越高,线条越少。
1时:
64时:
我们用个栗子来看看他们的区别和稳定性:
小兔子上场
正向提示词:
rabbit,animal
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Size: 512×512,
Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: pidinet_scribble,
ControlNet-0 Model: control_v11p_sd15_scribble [d4ba51ff],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
得到:
在只有 rabbit,animal 提示词下,scribble_xdog 最稳定且外物较少。pidinet_scribbl,scribble_hed 最具创意,pidinet_scribbl 甚至还出现了换头的情况。
再来个栗子,Scribble 既然叫涂鸦模型,那我们用涂鸦的方式来画个自然风景图。
正向提示词:
interactive, “the beautiful landscape”
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3580681343, Size: 512×768, Model: cheeseDaddys_35,
ControlNet-0 Enabled: True,
ControlNet-0 Module: scribble_xdog,
ControlNet-0 Model: control_v11p_sd15_scribble [d4ba51ff],
ControlNet-0 Weight: 1,
ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
scribble_hed 预处理器的效果:
scribble_pidinet 预处理器的效果:
最后是,scribble_xdog 预处理器的效果:
小伙伴们,你们喜欢哪个呢?趣闻屋等你们的答案。
10.control_v11p_sd15_softedge
Softedge 软边缘模型,可接受的预处理器:SoftEdge_PIDI、SoftEdge_PIDI_safe、SoftEdge_HED、SoftEdge_HED_safe。
这几个预处理器,官方给出了鲁棒性(Robustness)排行和最佳出图质量排行:
Robustness:SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
Maximum result quality:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
官方推荐使用 SoftEdge_PIDI,在大多数情况下,它最稳定。
那么我们就来看看,表现如何。
先来个国风小姐姐:
正向提示词:
beautifull woman
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3626764237, Size: 512×512, Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Model: control_v11p_sd15_softedge [a8575a2a],
效果:
无太大差别。质量上确实,hed更胜一筹,色彩更丰富,也更生动。
再来个次元风:
提示词没变和参数设定,修改大模型:
Model: anything-v4.0-pruned,
得到:
次元风,趣闻觉得hed好像不如其他,但它确实更贴近原图一些。
再看看写实风格的,挥手的帅哥再次登场:
修改正向提示词和大模型,其他参数没变:
正向提示词:a handsome man
Model: v1-5-pruned-emaonly,
得到:
pidinet safe 变化最大,手部也出现了不协调感。hed是一如既往的好,只是它的鲁棒性最低,如果小伙伴是少量出图的话,可以选择它。
11.control_v11p_sd15_ip2p
ip2p 是在 Instruct Pix2Pix 上训练出来的,没有预处理器。使用方法是,在正向提示词栏里给它指令,如“make it into X” 、”make Y into X”,然而官方提示说,”make it into X” 比 “make Y into X” 更有效果。
抄个官方栗子:
参数设置:
正向提示词:
make he iron man
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist:0.8>, by <bad-artist-anime:0.8>, by <bad-hands-5:0.8>, <bad_prompt_version2:0.8>
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Size: 512×768,
Model: Guofeng3_v33,
ControlNet-0 Enabled: True,
ControlNet-0 Module: none,
ControlNet-0 Model: control_v11e_sd15_ip2p
得到:
是的,就是这么简单的事儿!一句话把换人。
再来个:
正向提示词修改:make it winter(让它过冬)
得到:
妥妥的冬天有没有?!
ip2p 这个模型就是这么的简单、直接又如此的给力。只是,官方说还有一些不完善的东西,目前是实验性阶段。
那让我们一起期待它的正式版吧。
12.control_v11p_sd15_inpaint
Inpaint 这个模型跟图生图(img2img)里的 inpaint 功能类似,目前也只是实验阶段。
13.control_v11p_sd15_tile
Tile模型是可以让提示词只影响到我们选择的区域。什么意思?在Stable Diffusion中,我们写的提示词会影响到整张图,而我们想要修改局部会变得很难。而ControlNet Tile 模型就是解决这个问题的。让我们再一起期待吧。
如:修改手部
到这儿,ControlNet 的全部模型就介绍完咯。
14个模型,最后两个 control_v11p_sd15_inpaint 和 control_v11p_sd15_tile,在SD里面还用不了,同学们可以选择不下。
趣闻屋建议先下载 canny、openpose、depth和normalbae这四个模型。如果是建筑设计类从业的同学考虑下载mlsd。再其他的,小伙伴们自行下载体验吧~
完~
感谢小伙伴们的阅读,有什么补充、问题和纠错,欢迎评论区留言。
古德拜!我们下期见~
电梯:


















暂无评论内容