
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(一)
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(三)
本文要介绍的LoRA训练法,特别适用于下列对象:
nVidia显卡不够高级,跑不动训练程序根本不是nVidia的使用者,Stable Diffusion的训练程序不支持不想花钱花电力花显卡时间训练这个方法主要是借用Google Colab的威力,直接靠Colab强大GPU与够大的显存,能够非常充足地训练出品质非常优异的LoRA模型。
第一步,上传训练图:
首先,你必须登录Google,并进入我的云端硬盘(请使用魔法进入):
然后,创建一个多层的文件夹,根据你的LoRA的名称,格式是:
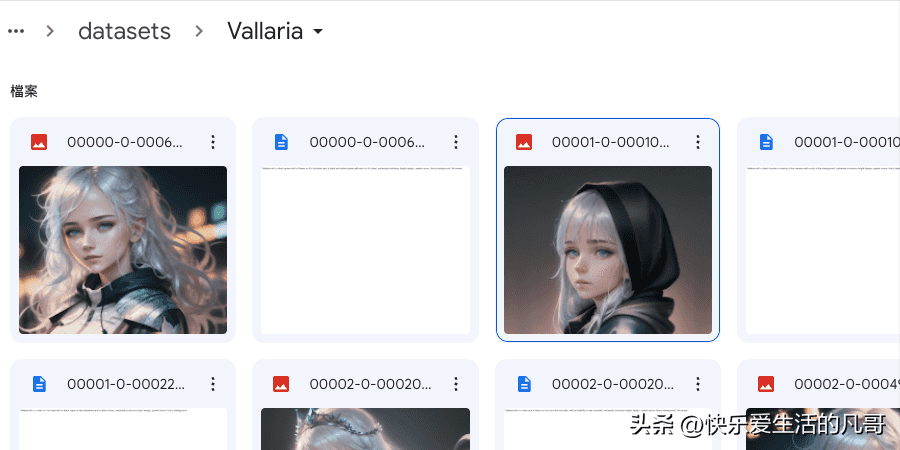
我的云端硬盘-> lora_training -> datasets -> <项目名称>以我为例,我创建的路径为:
我的云端硬盘-> lora_training -> datasets -> Vallaria之后,将AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(一)制作好的训练图以及提示词文档全部上传到这个目录里面。
第二步,使用Colab训练:
训练素材准备好之后,就可以打开Colab页面来训练了。
首先,登入这个页面:
colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb里面有几个栏目要填写,需要修改的有这几个:
project_name:等同于你放在Google云端硬盘的目录名,以我为例这里是Vallaria
training_model:有两个原始模型可以挑选,如果要用在动画图片上可用Anime,否则选Photorealism。我自己是用Photorealism训练,用在动画类的模型上也没啥问题。
num_repeats:每张图被训练的次数,这边我选15training_unit:我选择Epochshow_many:我选择30train_batch_size:同时训练的图的数量,通常是2其他参数保持不变即可。在这边你要依照你的训练图的数量来决定num_repeats的数量,有一个公式是:
训练图总数X 每张训练步数X Epochs数量/ 同时训练的图的数量= 总训练数。
以我的20张训练图为例:
20张X 15步X 30个Epochs / 2 = 4500。
这个数字要超过4000,这样LoRA的品质才会好,而通常低于6000,免得Colab的每日免费时长被用完。
当训练数量低于2000,出来的LoRA非常难看,角色的特征能被抓出来,但是成品的脸型边缘会一团模糊,更细部的特征例如雀斑、肤色会大面积不稳定在脸上扩散。当训练数量到达3000以后,大部分的品质会趋于稳定,但是眼睛的特征会过于模糊,使得人物的神色委靡。直到了4000以上的LoRA才能拿来用。
当一切都设定好之后,就可以按下左边的开始图示跑训练了!
刚开始跑的时候,程序会要求你授权,让它能存取你的Google云端硬盘,请记得要允许。
如果一切正常的话,你就会在这区块的最下方看到系统跑训练的log了!
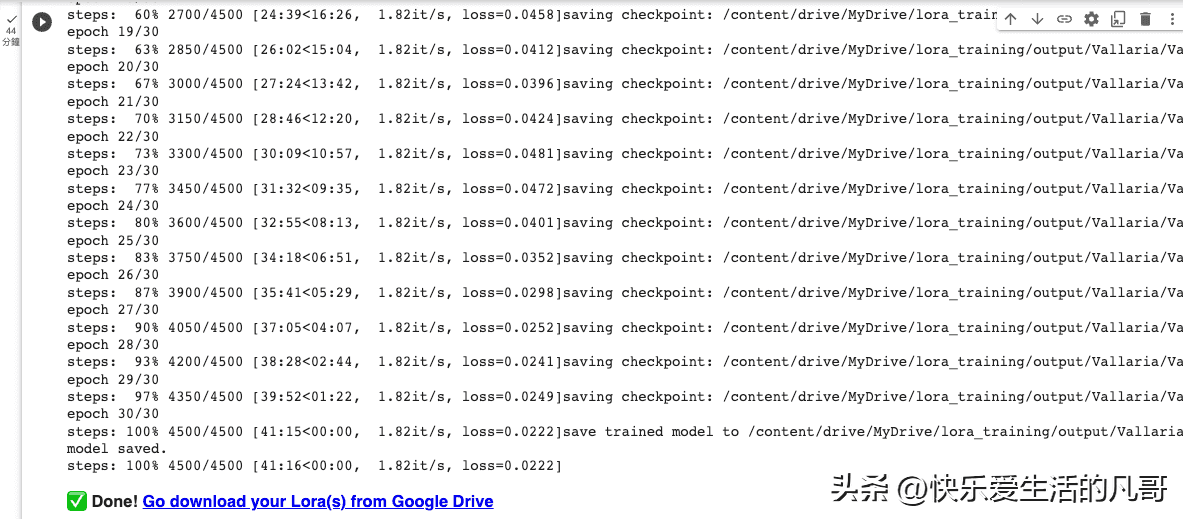
通常需要十到二十分钟才能跑完。
当训练完成后,模型文件就在你的云端硬盘的目录下:
我的云端硬盘-> lora_training -> output -> <项目名称>你会在这个目录上看到不止一个safetensors文件,数字最大的那个就是最后训练的成果LoRA文件了。
就这样,你已经轻松训练出你自己的LoRA了!
恭喜你,完成了!
是时候把你的LoRA模型放到stable-diffusion-webui的models/Lora目录里面,然后重启整个webui,就能看见它出现在Lora标签下了,马上用它来绘出你想要的角色图,验证并同时犒赏犒赏自己吧!

不论是哪种发型跟服装,你都能清楚看见角色的特征是一致的。



















暂无评论内容