
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(一)
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(二)

前2篇文章中,介绍了如何训练LoRA之后,线上训练LoRA的Colab页面又改版了,改变了一些设置,引进了一些模型,所以某些设定不再适用。加上我找到了该Colab的作者写的,专门讨论如何使用他的工具来训练LoRA的页面,以及在各个论坛讨论如何精确训练LoRA的文章,我决定把我近来训练的方法更新在新文章中。让大家有个参考。
问题
之前使用的方法,的确可以快速产出你要的LoRA,而且不需要任何高性能的显卡,但是这个方法有一些问题:
将训练图的提示词提炼出来,依旧需要用本机的Automatic1111来做,而有些时候Automatic1111会出问题,怎么提炼提示词都是错的,尤其是deepbooru,我的本机没成功过。迫使我只能用CLIP来做,在动漫类角色LoRA上问题很大。常常训练出过拟合(Overfitting)的LoRA,这种LoRA不只是影响你的角色,它还会影响图片的整体画风,迫使你必须将权重放得很低,否则只要一高起来,不管你使用什么模型,出来的图都会扭曲,甚至破图。而你将权重放得过低,产生出来的角色又会变得不像,使得你在出图时必须反复调整权重,找出能生出相像的角色,但是又不会严重影响画风的设定,有如在走钢索。不知道怎么检测产生的LoRA到底品质好不好,如果前前后后产生了好几个LoRA,要怎样决定哪个版本更好,在不同模型下要使用什么权重。这几个问题,基本上训练LoRA的Colab的作者都有在他的专题页面上讲到,有兴趣的可以去看看。
[Guide] Make your own Loras, easy and free
接下来就来讨论如何依照他给的解释,整合进自己的人物类LoRA训练流程。
首先,第一个问题是从训练图提炼提示词的问题,除了使用Automatic1111来抓词,并且自己进去文字档一个一个修改之外,holostrawberry大大给了我们一个专门的Colab页面来处理这个问题,本文稍后会使用到。
第二个问题,过拟合通常有两个因素,一个是训练回数太多太久,使得LoRA的权重产生严重偏见,让它可以在训练时取得良好分数,另一个原因是因为我们没有提供规范图(regulation images)。无法在LoRA训练想取巧时教训它。
至于什么是规范图,让ChatGPT来回答他的定义:
在图像生成式AI的训练中,regulation images的功能是将一些无关的图像加入到训练数据中,以增加模型的泛化能力,防止过度拟合。这些无关图像可能是与训练数据中的图像非常相似,但实际上不属于目标类别的图像,或是随机产生的噪声图像。
加入regulation images会对模型的品质产生积极影响。如果模型只在训练数据中学习,那么它很可能会过度拟合训练数据,导致在新数据上的表现不佳。然而,当使用regulation images时,模型被迫学习一些与目标类别不完全相关的特征,这可以帮助模型更好地泛化到新数据上,并且可以减少过度拟合的风险。因此,regulation images可以提高模型的品质和稳健性。目前看不懂没关系,我们马上就要来自己生产规范图,让我们从范例中搞懂这是什么东西。
上传训练图
在这一版的流程中,我们一样要准备并裁切训练用的素材图,请依照我在AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(一)之中的「准备」与「裁切」素材图。
本次以训练一个猛男战士为目标,准备了他的素材图:
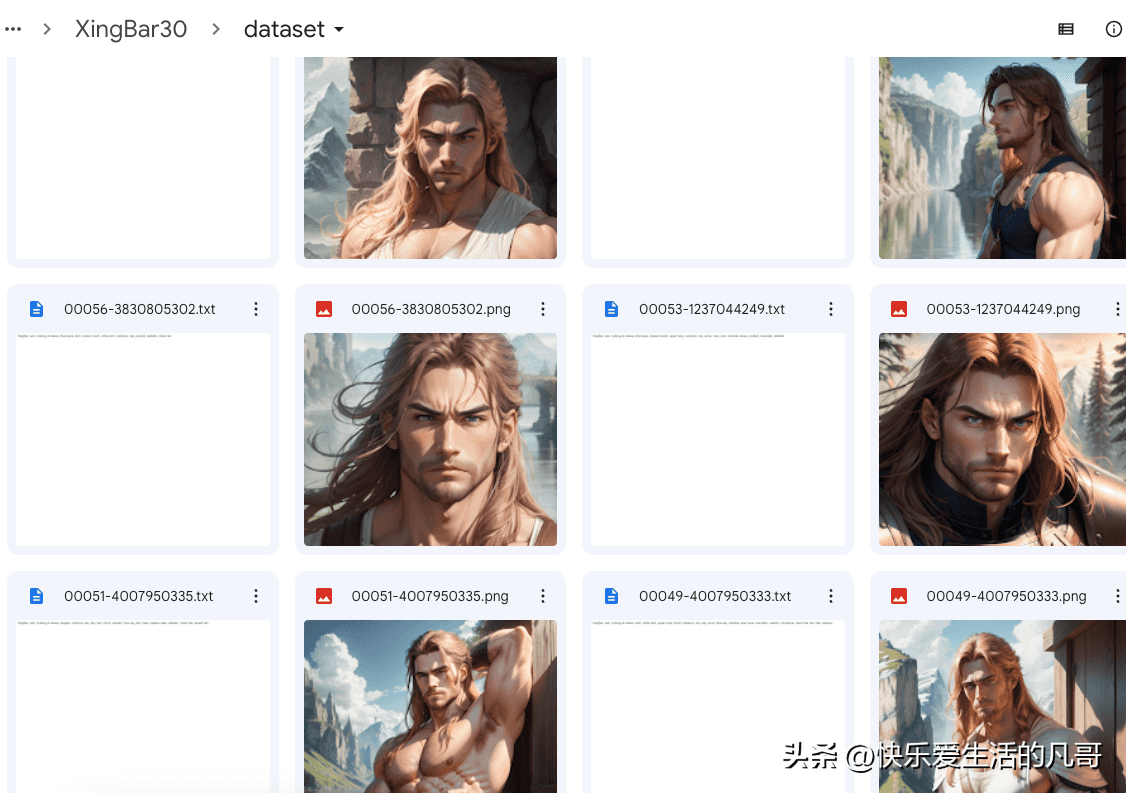
并且帮他指名了启动词XingBar。原本我使用的词是Xing,但我发现这个词已经被Stable Diffusion使用了,是一个东方女子的提示词,所以若是没有改名,会在使用时冲突,出现的人物会变来变去,甚至出现意想不到的图片。所以在取名启动词之前,最好用lexica.art等网站查询一下自己的启动词会不会叫出一个固定的角色。
素材图准备好之后,我们不用在这时提炼提示词,请直接将所有的素材图上传到Google云端硬盘上,由于Colab的作者更新了设定,我们要将它放置在新的路径格式上:
我的云端硬盘-> Loras -> <项目名称> -> dataset以我这次的范例,我的目录位置是:
我的云端硬盘-> Loras -> XingBar30 -> dataset接下来,我们要来生产规范图。
产生与上传规范图
特地问了ChatGPT关于规范图的挑选标准,我觉得很准确:
选择好的regulation images是非常重要的,因为这将直接影响模型训练的品质。以下是一些挑选好的regulation images的方法:
1. 选择高质量的图像:确保你选择的图像是高质量的,可以清晰地显示出你想要的特征。
2. 多样性:选择多样的图像,包括不同的风格、色彩和纹理,这有助于提高生成模型的多样性。
3. 详细:选择能够呈现你想要特定特征的图像。例如,如果你想训练一个生成写实风格的模型,那么你需要选择那些能够呈现真实细节的图像。
4. 数量:通常情况下,regulation images的数量越多越好,因为这能够提高训练的品质和多样性。但是,选择过多的图像可能会增加训练的时间和计算成本。也就是说,规范图需要的是一大批跟素材图同类别,但是又不会太相似,也不会太过不相似的图。
所谓的同类别,例如我的目标是猛男战士,那同类别就会是男性,男战士,男野蛮人这种东西。而我上一个训练的LoRA是银发年轻女性,同类别的图就是女性,女孩等类别。
但我们在挑选规范图时尽量避免列入太过相似的图,免得训练时让AI困惑。同时也要避免太过不相像,例如你的素材图是动漫系男性战士,但你的规范图是毕卡索或梵谷画中的男性,甚至是男性玩具士兵的图片,这样可能让整个训练过程的Loss数值降不下来。或是让AI将你的启动词归类到不同的类别里。
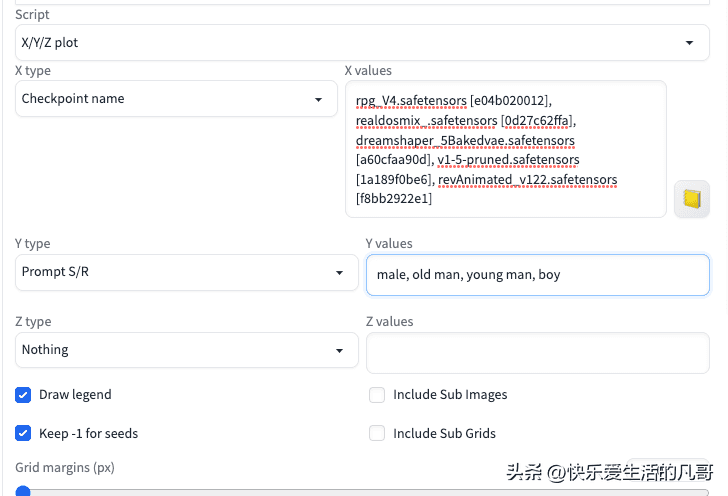
产生规范图的方法有两种,第一种就是Google搜寻该类别的图片,找个100张,再裁切成512×512的图片,然后上传到Google云端硬盘。第二种则是自行使用Automatic1111的X/Y/Z plot来大批量生产图片:
AI绘图|Stable Diffusion进阶Script脚本使用详解——X/Y/Z plot篇
在这边我以生产男性图片为例,使用这样的设置:
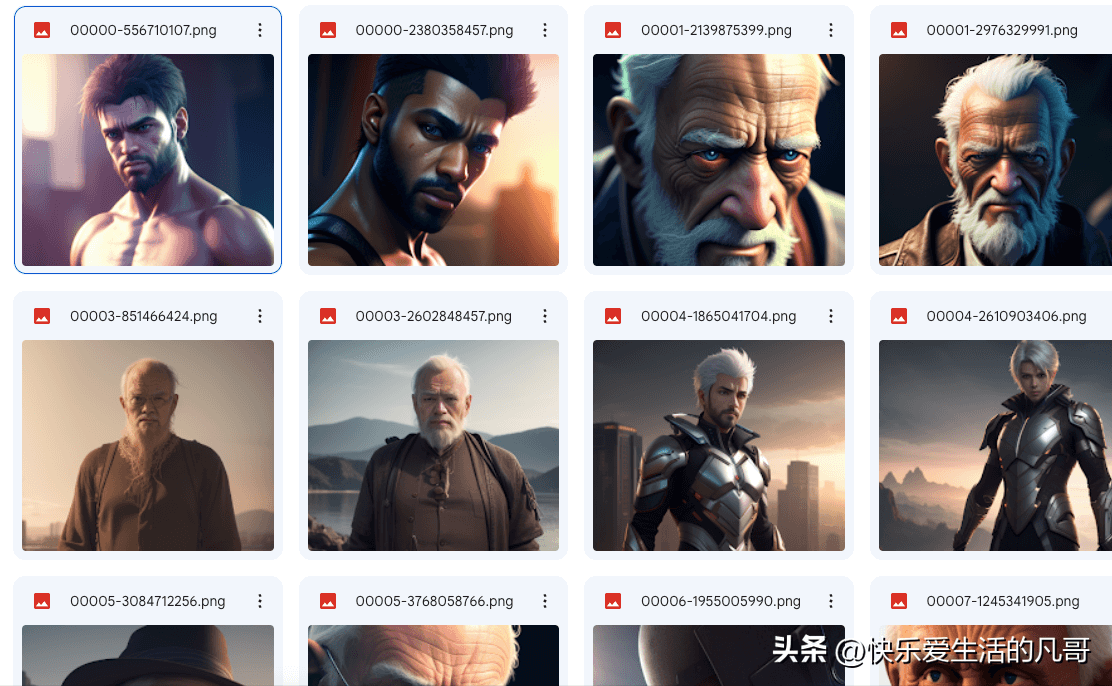
然后产生大约150张图片,挑选其中100张符合条件的图片上传云端硬盘,放在这样的文件夹下:
我的云端硬盘-> Loras -> Man -> dataset在Google云端硬盘上,会看起来像这样:
产生提示词
接下来,我们就要使用Colab来帮助我们快速生成训练与规范图的提示词。请打开这个Colab页面:
colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Dataset_Maker.ipynb这个页面提供了从头生成素材图辑的整个流程,但我们已经有素材图了,所以只需要用到它的提示词生成功能。
规范图的提示词
首先我们从简单的规范图提示词开始,在第一步的project_name填入我们的规范图文件夹Man,而folder_structure则保持不变,使用作者提供的新架构:

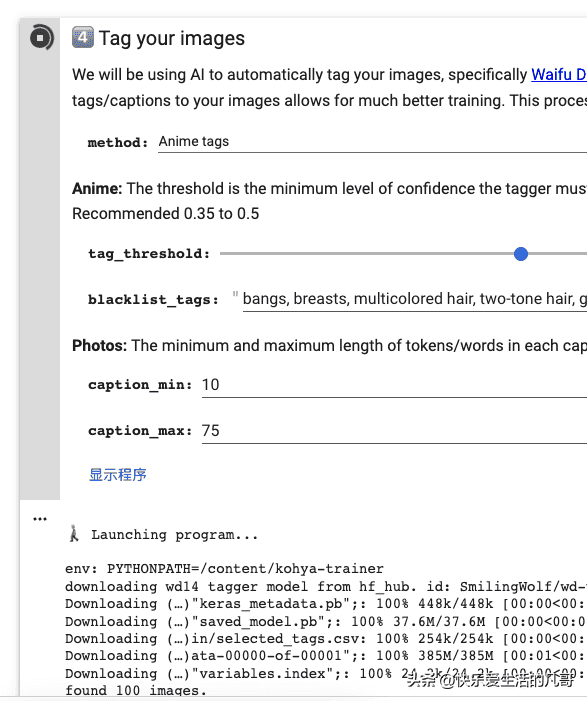
按下执行后,它会要求存取你的Google云端硬盘,授权之后接着跳到第四步(Tag your images)。
在这边什么都不用改,直接执行即可,程序会使用Waifu Diffusion的文字图像对应模型,替你的图产生提示词。
只要确认程序找到图,并且产生文件档之后,我们就来处理比较复杂的素材图的提示词。
素材图的提示词
一样打开同一份Colab文件,这次在第一步project_name填入放置素材图的项目名称XingBar30,然后执行。一样跳到第四步,直接执行,确认所有的素材图都有相对应的文件档产生,而且Colab会给你一个提示词与提示词出现次数的分布名单:

之后需要到第五步(Curate your tags)置换你的启动词与要融合的词。
这个步骤,官方的说明是:
编辑你的提示词:这个步骤对于动画提示词来说是可选的,但非常有用。在这里,你可以为你的LoRA定义启动词。如果你正在训练风格,你可能不想要任何启动词,这样LoRA就会一直生效。如果你正在训练角色,我个人倾向于删除(修剪)与角色内在特征有关的常见提示词,例如身体特征和头发/眼睛颜色。这会导致它们被启动词吸收。
在我们的例子中,启动词global_activation_tag是XingBar,而remove_tags则是你在第四步的提示词分布名单上看到的,想要融合进角色的提示词,对我的角色而言,就是跟男性、眼睛颜色、发型、肌肉等相关的提示词:
brown eyes, long hair, male focus, mature male, muscular, blonde hair, pectorals, muscular male, manly, large pectorals

其他栏保持不变,按下执行之后,Colab会将每个文件的开头放进启动词,并且将remove_tags列进去的提示词都移除掉。这样我们就完成所有的准备步骤了!
验证提示词
在Colab页面最下端的Extras区域,有一个工具Analyze Tags可以检查剩下的提示词:

确认了提示词已经成功整理干净,我们就可以在下一篇来训练,并验证LoRA的品质!



















暂无评论内容