
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(二)
AI绘图|如何使用Stable Diffusion训练自己的LoRA模型实战(三)

闲聊!目前AI绘图在国内游戏厂商,特别是去年MJ那波开始,只是大厂有点兴趣,自SD出来后,直接巅峰了,不管是鹅厂猪厂都把整个美术团队拉起去训练自己的LoRa模型去了。LoRa训练完成了,再把这些人给开了。
目前来说,各厂商基本都有自己的LoRa模型在跑了,再配合企业美工做后期能提效80%左右吧。
言归正传,下面来说说怎么进行自己的LoRa模型训练吧.
从我自己学了LoRA之后,在动漫模型里练出了我要的角色图样之后,再放进colab训练出LoRA,然后把LoRA用在真人向模型,结果就能弄出各种逆天实景:

在冰川遗迹上外拍
所以,Stable Diffusion上面除了学好提示词算是基本技巧,接下来的LoRA,ControlNet,3D OpenPose Editor等都是让你的出图时间更快的进阶技巧。确实可以大幅缩短创作时间。
准备
LoRA可以在很多地方下载不同的角色、物品、风格,例如Civita,huggingface。但是如果你想要训练自己的LoRA,像我一样,那你需要准备好训练的素材图,才能顺利炼丹。
数量:依照经验,7张到100张都可以,但是张数过少,同一张训练的次数会非常多,训练出来的LoRA在高权重的时候会让算出来的图严重变形(尤其是背景部分)。所以最好是20张上下。当然你可以用镜像出图的方法让训练图数量加倍,但这样还是没办法避免高权重下整体变形的问题。品质:如果是训练人物或物品的LoRA,最好不要有太多同一个角度,同一个表情的图片,尤其在张数少的情况下,训练出来的LoRA会有人物表情僵直的问题。人物的脸通常是LoRA的重点,最好能有面孔多角度,不同光影,不同表情,不同服装配件,让模型能够涵盖够多的情况。切记不要加入模糊失焦、被挡住部分脸部的图片,除非你准备的张数够多。尺寸:以Stable Diffusion 1.X为基准训练的图片要求至少要是512×512像素的正方形图片,而Stable Diffusion 2.X的话图片至少要768×768像素。裁切
当我们准备好图片之后,就要开始裁切,如果没有泄密疑虑的话,什么美术工具都不会的美术小白可以使用BIRME这个网站,把过大的尺寸裁切成512×512的训练素材图:
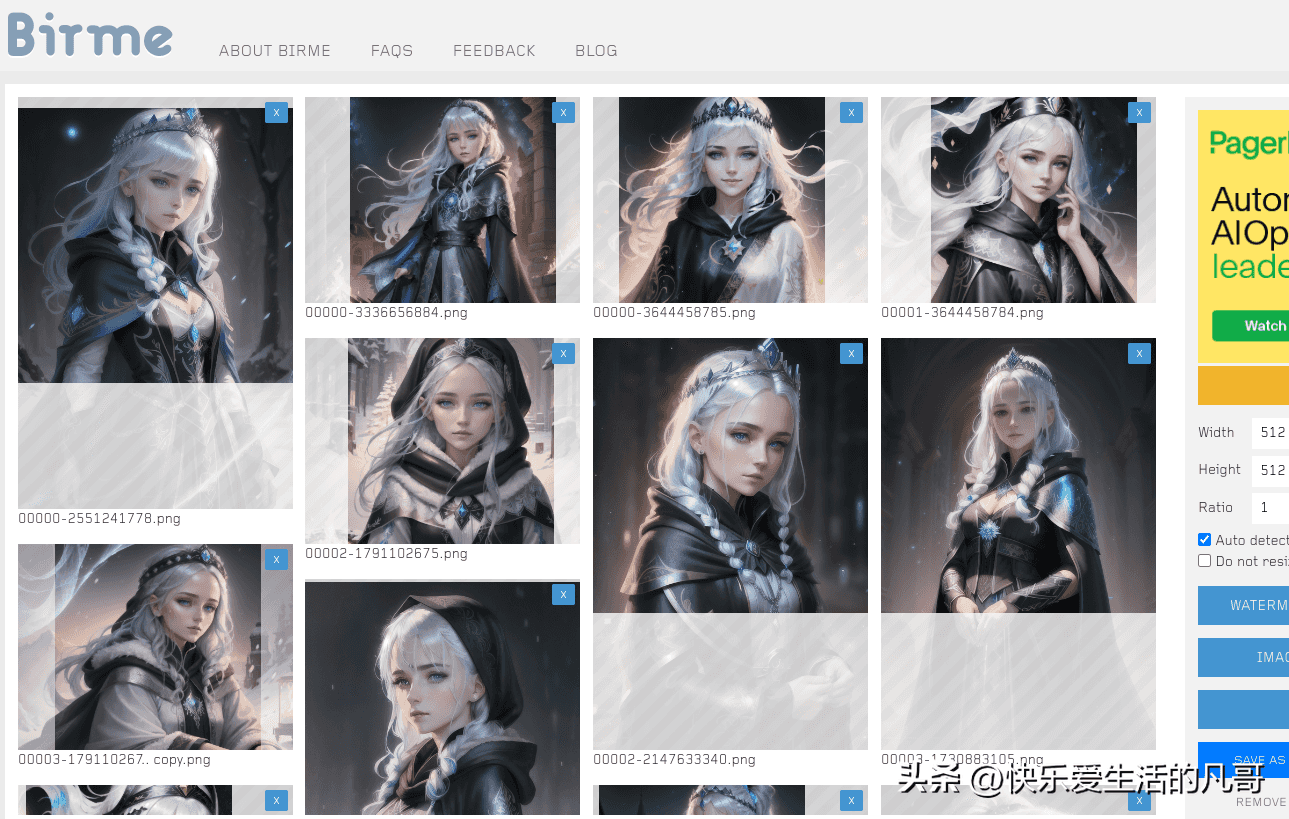
使用BIRME裁切训练素材
预处理
接下来是最重要的一步,LoRA的品质除了跟训练图本身的品质,以及训练的设定有关之外,另一个重点是训练图的提示词文本。
有关如何在Automatic1111上帮训练图提炼提示词文本,这个在之前的文章中有详细教程,可自行翻阅。
在Use BLIP for caption与Use deepbooru for caption这两个选项,我都用BLIP来提炼提示词,因为deepbooru给的提示词实在太多了,很多其实是瞎猜,如果你的训练图超过30张,光是删掉不对的提示词就够累了。
第二点,你必须打开每个提示词文本文件,一个一个修正提示词,否则你怎么训练都不会练出有用的LoRA。
以我想要训练的角色为例:
名字(提示词):Vallaria。外表特征:银白色头发,白皮肤,深蓝色眼眸,黑眉毛,有雀斑。名字最好是够独特的,如果太大众化的名字,会跟模型里面的同名物体冲突,如果真的不想取其他名字,试试看后面加数字,例如Jack888,避免冲突。
(顺带一提,SD里面真的有一个叫Jack的提示词,会算出成年男性,虽然每次叫出来的Jack都长得不一样)
当你打开提示词文件时,可能会看到像这样的叙述:
a woman with white hair and blue eyes and black robe and a flower on the shoulder of the robe at a snowy street.
此时,要将对象提示词a woman换成你要的角色名,在这个例子要换成Vallaria。接着,把关于发色white hair与眼眸颜色blue eyes等我们定义好的外表特征也删掉。接着,观察原本的图片,把不是你想要但是显示在图片上的提示词写进去,例如头上有戴帽的话就要加hat,背景的光线布局与季节是秋光autumn lights,她手上有一根烛台之类的,与角色特征无关,但是预处理程式没抓出来的事情。更改过的提示词会变成这样:
Vallaria with black robe and a hat on her head and a flower on the shoulder of the robe at a snowy street, autumn lights, candle stick on her hand
你大概会觉得这句子文法不通。没关系,电脑在训练时会将整个提示词文本用自己的方法拆成一堆单词,电脑是不太在乎语法的。
至于为什么要删掉特征,加上没提到的事情,是因为这就是训练的目的。
AI学习绘图,就是建立在图形与提示词的关联上,所以当电脑发现这是一个蓝眼睛白皮肤白头发的女性,但是却在提示词文本上找不到眼睛颜色、头发颜色、皮肤颜色的提示词,却反而每张图都有一个叫Vallaria的提示词时,他就会学到Vallaria等于蓝眼睛白发的白人女性,以及诸如脸型,五官比例等等特征。
相反地,你不要AI建立关联的特质,就必须要尽量标示出来,例如我的训练图八成以上Vallaria都有戴上帽子或公主冠等头饰,就必须要在每个出现的图片上都标示在提示词文本上,否则AI会认为头上有头饰是这个角色的外表特征,训练出来的LoRA会变成Vallaria出现时,头上必戴公主冠的问题。
准备训练
本文后续教程,都使用google cloab进行。
将训练图与文本都准备好之后,上Google Drive确认自己有足够多的空间(大约1到2GB),没有Google帐号的请申请,我们将在下一篇开始训练LoRA,而且这个方式不需要本机安装任何东西,也不需要任何怪兽显卡,人人都能用!
接下来,就是正式训练:



















暂无评论内容